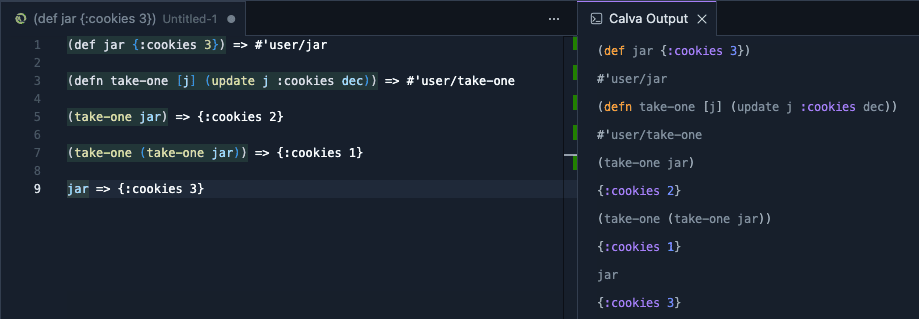
 Lisp 常因其非传统的语法和陡峭的学习曲线而被忽视,但它提供了一种独特的范式,能够从根本上改变你处理编程的方式。与大多数语言不同,Lisp 具有“同像性”(homoiconic),这意味着代码和数据都以列表的形式呈现。这一特性支持强大的宏功能,允许开发者扩展语言本身,从而根据问题来塑造工具,而不是强迫问题去适应工具。
除了语法之外,Lisp 还通过 REPL(读取-求值-输出循环)提供了“实时”的开发体验。这种环境支持交互式的迭代开发,代码是在运行进程中不断演进的,而非通过传统的“编写-编译-运行”这一静态周期。这种能力结合 Lisp 与生俱来的可扩展性,使其在构建高度可定制的领域特定系统方面具有独特优势——Emacs 的无限模块化便体现了这一哲学。
虽然 Lisp 可能永远不会成为主流,但学习它能为软件架构提供极其宝贵的视角。掌握 Lisp 后,你将获得编写“能编写程序”的程序的能力,从而解锁其他语言难以企及的强大功能与灵活性。
Lisp 常因其非传统的语法和陡峭的学习曲线而被忽视,但它提供了一种独特的范式,能够从根本上改变你处理编程的方式。与大多数语言不同,Lisp 具有“同像性”(homoiconic),这意味着代码和数据都以列表的形式呈现。这一特性支持强大的宏功能,允许开发者扩展语言本身,从而根据问题来塑造工具,而不是强迫问题去适应工具。
除了语法之外,Lisp 还通过 REPL(读取-求值-输出循环)提供了“实时”的开发体验。这种环境支持交互式的迭代开发,代码是在运行进程中不断演进的,而非通过传统的“编写-编译-运行”这一静态周期。这种能力结合 Lisp 与生俱来的可扩展性,使其在构建高度可定制的领域特定系统方面具有独特优势——Emacs 的无限模块化便体现了这一哲学。
虽然 Lisp 可能永远不会成为主流,但学习它能为软件架构提供极其宝贵的视角。掌握 Lisp 后,你将获得编写“能编写程序”的程序的能力,从而解锁其他语言难以企及的强大功能与灵活性。
每日HackerNews RSS
这段 Hacker News 讨论探讨了编程界的“光明面与黑暗面”:即限制性、安全性导向的语言与宽容、强大语言之间的博弈。
Lisp 在这场争论中占据了独特的位置。拥护者认为,其同像性(代码即数据)和强大的宏系统提供了无与伦比的表达能力,使开发者能够构建领域特定语言并抽象掉复杂性。相反,批评者则认为它更像是一个缺乏现代人机工程学、标准化并发机制以及大规模团队生产所需安全保障的学术性“狂热”。
核心主题包括:
* **宏的争论**:支持者声称宏能带来“Lisp 启示”,允许用户构建自定义类型系统或安全约束。批评者则认为,与 Rust 或 Haskell 等现代语言中由编译器强制执行的稳健安全性相比,这些只是“派对戏法”。
* **开发体验**:许多人强调,Lisp 的真正价值不仅在于语法,还在于其交互式、基于镜像的“实时”开发周期。然而,怀疑论者指出,这些优势在其他开发环境中也正变得越来越普遍。
* **AI 的影响**:参与者认为,大语言模型(LLM)可能会改变这一格局,因为 Lisp 的结构非常适合交互式、代理驱动的开发,这或许能弥补它在理论能力与实际应用之间的鸿沟。
这段内容是 PDF 文件的原始二进制流数据,并非可阅读的文本信息。即使翻译成中文,也无法呈现为有意义的文字内容。
抱歉。
《Damn Interesting》的创始人艾伦·贝洛斯(Alan Bellows)正在发起一项一次性的筹款活动,旨在为他的深度新闻写作争取时间。二十年来,贝洛斯一直兼顾兼职工程工作与写作;然而,随着现代就业市场转向全职岗位,他投入该网站的时间日益减少。 在充斥着人工智能生成内容的数字环境中,贝洛斯希望筹集到足够的资金,以弥补他一年内因辞去全职工作而损失的薪水。这一目标将使他能够脱离全职工作,重新专注于研究、写作和编辑工作。 虽然《Damn Interesting》有独立的“Give a Damn”系统来支付网站运营费用,但这项新计划是专门为支持创始人的时间成本而设计的。贝洛斯以一种戏谑的方式类比“魔力8号球”来形容这次尝试,他表示尽管未来充满不确定性,但他对读者能够帮助保留高质量的人类原创内容持乐观态度。捐款可通过他的 GoFundMe 页面进行。
网站 *Damn Interesting* 是一家以深度研究和高质量叙事著称的老牌刊物,近期其网站流量因 Hacker News 的推介而激增,这也引发了关于独立在线出版所面临挑战的讨论。
该网站创办人指出,他们常受“博客垃圾内容”抄袭者的困扰,这些人通过剽窃其原创研究牟利。虽然有读者建议转向 Substack 等平台或采用 Patreon 模式来确保财务可持续性,但创办人对建立在“反复无常”的第三方平台上的工作方式持谨慎态度,并援引了过往 Facebook 算法变更带来的负面经验。
目前,作者正通过筹款来争取更多写作时间,因为现有的“Give a Damn”支持系统仅能覆盖运营成本。作者表达了坚持独立性的坚定承诺,拒绝让赞助者影响其编辑立场。支持者们称赞该网站是现代“泛知识”类播客的先驱,在感叹“旧互联网”衰落的同时,也为能够继续看到如此高质量、非人工智能生成的内容感到欣慰。
高效的职场邮件应优先考虑速度、清晰度和实用性。为实现最佳效果,请在第一句话中直接点明核心目的——无论是请求、决策、进展还是风险。避免使用客套话、通用问候语或铺垫性的叙述等“废话”。 每封邮件都应内容完整,包含所有必要的背景、姓名、日期和事实,确保即使被转发也能让人看懂。使用精确的语言,避免模糊的措辞,并以具体数据代替主观猜测。每封邮件仅讨论一个主题,并使用清晰且具有行动导向的主题行(例如:“[待办]:项目 X 审批”)。 内容的逻辑结构应为:先陈述结论,随后提供简洁的支持性事实,并明确指出后续步骤的负责人及截止日期。清楚区分事实、判断和建议。确保邮件篇幅适中,在一屏之内即可读完。 归根结底,你的目标不是显得深奥或过于正式,而是让读者能瞬间理解情况并果断采取行动。如果某个话题需要细腻的情感交流或复杂的探讨,请放弃邮件,改用通话或聊天沟通,之后再补发一份简短的书面总结。保持直接、尊重且人性化。
总部位于米兰的科技集团 Bending Spoons 近期在纳斯达克上市,市值超过 250 亿美元,为其此前私人估值的两倍。该公司源于一家倒闭初创公司的残余,现已演变成一家收购成熟数字品牌(如 Evernote、Meetup、Vimeo、AOL 和 Eventbrite)的行业巨头。 与经常转手资产的私募股权公司不同,Bending Spoons 将收购的品牌整合进一个中心化平台,侧重于通过人工智能、提价及大规模裁员进行激进的优化。尽管其削减成本和裁员的措施引发了争议,但公司坚称,这些转型是为了稳定和实现“老牌互联网”品牌的现代化,而非任其消亡。 这一战略正带来强劲的财务回报:该公司 2025 年报告营收为 13.1 亿美元,月活跃用户超过 5 亿。尽管拥有庞大的用户群,Bending Spoons 的核心“Spooner”团队却保持得非常精简,并利用人工智能来推动高生产力。目前,该公司已锁定超过 1000 个潜在的收购目标,旨在扩大其“收购并转型”的模式;随着向数十亿美元规模交易的转变,该公司押注市场的不确定性和人工智能驱动的效率将进一步推动其增长。
Bending Spoons 是一家科技公司,以收购处于衰退期或停滞状态的 SaaS 产品(如 Evernote、Vimeo 和 AOL)并对其进行重组以实现盈利而闻名。尽管该公司将自身战略描述为避免沦为“科技坟墓”的“长期管理”,但 Hacker News 上的评论者认为这种做法本质上是私募股权式的“强制变质”。
常见的用户抱怨包括大幅涨价、引入激进的变现策略以及大规模裁撤原员工。然而,支持者则认为,Bending Spoons 让那些核心但正在走下坡路的服务得以存续,并不时进行必要的架构更新和增加前任所有者已放弃的功能。
这场争论凸显了两种理念之间的冲突:一种观点将 Bending Spoons 视为利用用户锁定效应榨取价值的“秃鹫”;另一种观点则将其视为在追求持续增长的市场环境中,让成熟产品维持活力的理性经营者。归根结底,该公司的模式导致了用户群的分化,许多用户在面对这些变化时,选择转向开源或更可持续的替代方案。
问题所在:当家人遭遇医疗紧急情况或离世时,家属往往会突然面临诸多难题:寻找文件、联系相关人员、处理账户、理解保险条款以及确保账单按时支付。LastShelf 助您提前做好这一贴心准备,为您爱的人留下一份清晰的指引。
```❯ npx @robzolkos/lazypi ◆ 安装所有内容还是选择部分包? ● 安装所有(推荐) ✔ pi-subagents 已安装 ✔ pi-memory-md 已安装 ✔ pi-mcp-adapter 已安装 ✔ 67 个主题已安装 ✔ 60+ 个技能已就绪 ◆ 完成。运行 pi 以开始。```
```javascript import ContextDev from 'context.dev'; import { z } from 'zod'; const contextDevClient = new ContextDev({ apiKey: process.env['CONTEXT_DEV_API_KEY'] }); // 定义 Context.dev 应从页面中提取的精确结构。 const schema = z.object({ company_name: z.string(), pricing_tiers: z.array( z.object({ tier_name: z.string(), tier_description: z.string(), tier_price: z.number(), tier_currency: z.string(), tier_billing_frequency: z.string(), tier_billing_model: z.enum(['monthly', 'yearly', 'one_time', 'usage_based']), }) ), }); // 将 Zod schema 转换为 JSON Schema 以用于 /web/extract。 const result = await contextDevClient.web.extract({ url: 'https://www.context.dev', schema: schema.toJSONSchema(), }); // result.data 现在匹配上述 schema。 console.log(result.data.pricing_tiers); ```
Context.dev (YC S26) 是一款旨在简化网页数据集成至应用程序与 AI 智能体(Agent)的 API。该服务由 Yahia Bakour 创立,可将原始 URL 转换为 Markdown、JSON、截图以及提取出的元数据(如 Logo、字体、联系方式)等结构化、易于使用的格式。
核心功能包括:
* **结构化数据**:通过 JSON 模式提取特定详细信息(如定价、产品类别等)。
* **品牌背景**:为入职流程和 CRM 工作流提供丰富的组织数据。
* **以基础设施为先**:针对构建 AI 智能体和聊天机器人的开发者进行了优化,强调可靠性和低错误率,而非单纯的抓取。
* **负责任的爬取**:使用缓存层以避免给网站造成过大压力,并尊重退出请求。
尽管“爬取即服务”(scraping-as-a-service)市场竞争激烈,但 Context.dev 通过透明的定价(无隐藏积分倍数)以及对智能体工作流高质量输出的关注,实现了差异化竞争。在 Hacker News 的发布讨论中,创始人指出,许多用户迁移到该平台是为了摆脱构建自建抓取基础设施带来的维护负担。该服务现已上线,并已包含对 MCP 等集成的支持。
拒绝访问 拒绝访问 您没有权限访问此服务器上的 "http://mitpress.mit.edu/9780262053198/simpolitics/"。 参考编号 #18.1cd62c17.1783611180.417b2df https://errors.edgesuite.net/18.1cd62c17.1783611180.417b2df
抱歉。
 管理内部服务的 TLS 证书时,往往会遇到自签名证书报错,或因忽略警告而导致的安全隐患。本文提出了一种更优的解决方案,即利用**水平分割 DNS (split-horizon DNS)** 为内部应用提供合法的公共 TLS 证书。
通过使用 **NetBird** 等工具,你可以配置水平分割 DNS,使内部服务在通过 VPN 访问时解析为私有 IP 地址,同时仍可进行公网解析。这允许你使用 **Let's Encrypt** 等受信任的 CA 颁发标准证书。
为了保障安全,作者配合使用了一个绑定 VPN 接口的 **NGINX 反向代理**,它能有效发挥 Web 应用防火墙 (WAF) 的作用,拦截外部流量。自动化流程通过 **acme.sh** 和自定义定时任务 (cron job) 处理,负责证书更新并确保 NGINX 自动重载。
这种方法提供了一种专业且“一劳永逸”的工作流,既消除了浏览器警告,又通过多层防御提升了安全水平,且无需手动维护证书。
管理内部服务的 TLS 证书时,往往会遇到自签名证书报错,或因忽略警告而导致的安全隐患。本文提出了一种更优的解决方案,即利用**水平分割 DNS (split-horizon DNS)** 为内部应用提供合法的公共 TLS 证书。
通过使用 **NetBird** 等工具,你可以配置水平分割 DNS,使内部服务在通过 VPN 访问时解析为私有 IP 地址,同时仍可进行公网解析。这允许你使用 **Let's Encrypt** 等受信任的 CA 颁发标准证书。
为了保障安全,作者配合使用了一个绑定 VPN 接口的 **NGINX 反向代理**,它能有效发挥 Web 应用防火墙 (WAF) 的作用,拦截外部流量。自动化流程通过 **acme.sh** 和自定义定时任务 (cron job) 处理,负责证书更新并确保 NGINX 自动重载。
这种方法提供了一种专业且“一劳永逸”的工作流,既消除了浏览器警告,又通过多层防御提升了安全水平,且无需手动维护证书。
抱歉。