 Grammarly 正在经历重大转变,在收购电子邮件客户端后将品牌重塑为“Superhuman”。 尽管公司名称已更改,但“Grammarly”产品将保留现有品牌。 此举标志着更广泛的雄心,即发展成为一个全面的生产力套件,与 Notion 和 Google Workspace 等平台竞争。
这项策略的核心是“Superhuman Go”,这是一款新的 AI 助手,集成到 Grammarly 扩展程序中。 它提供写作建议、电子邮件反馈,并与 Jira 和 Gmail 等应用程序连接,以提供上下文帮助——甚至可以自动化诸如日程安排和工单记录之类的任务。 未来计划包括与 CRM 和内部系统集成。
Grammarly 还在探索将其另一项收购 Coda 重新命名,并为 Superhuman Mail 和 Coda 文档套件添加 AI 功能。 新的订阅层级,定价为每月 12 美元(Pro)和每月 33 美元(Business),将提供扩展的语言支持和对 Superhuman Mail 的访问权限。
Grammarly 正在经历重大转变,在收购电子邮件客户端后将品牌重塑为“Superhuman”。 尽管公司名称已更改,但“Grammarly”产品将保留现有品牌。 此举标志着更广泛的雄心,即发展成为一个全面的生产力套件,与 Notion 和 Google Workspace 等平台竞争。
这项策略的核心是“Superhuman Go”,这是一款新的 AI 助手,集成到 Grammarly 扩展程序中。 它提供写作建议、电子邮件反馈,并与 Jira 和 Gmail 等应用程序连接,以提供上下文帮助——甚至可以自动化诸如日程安排和工单记录之类的任务。 未来计划包括与 CRM 和内部系统集成。
Grammarly 还在探索将其另一项收购 Coda 重新命名,并为 Superhuman Mail 和 Coda 文档套件添加 AI 功能。 新的订阅层级,定价为每月 12 美元(Pro)和每月 33 美元(Business),将提供扩展的语言支持和对 Superhuman Mail 的访问权限。
每日HackerNews RSS
## Grammarly 品牌重塑为“Superhuman”并推出AI助手
Grammarly 正在将其品牌重塑为“Superhuman”,并扩展到语法检查之外,推出新的AI助手,旨在成为一个更广泛的生产力套件。这一举措源于AI写作工具在Gmail和Docs等平台上的日益普及,迫使Grammarly不断发展以保持相关性。
这一消息在Hacker News上引发了争论,许多用户质疑增加功能的需求,更喜欢Grammarly最初的语法功能。人们对品牌重塑本身也表达了担忧,一些人认为“Superhuman”这个名字令人反感,并担心功能臃肿。
讨论还集中在竞争格局上,用户指出内置AI工具和LanguageTool等替代品。一些人推测,品牌重塑是一种绝望的差异化尝试,而另一些人则认为这是鉴于当前AI趋势的自然发展。收购邮件客户端Superhuman,进一步表明了这一转变。最终,用户对新方向能否保持Grammarly的核心价值,或稀释其重点表示怀疑。
Please provide the content you want me to translate. I need the text to be able to translate it to Chinese. Just paste it here, and I will give you the Chinese translation.
一个 Hacker News 的讨论集中在一个新服务上,该服务允许用户使用 Cloudflare 的邮件路由功能创建免费的商务邮箱地址。虽然该服务对于*接收*邮件(例如 [email protected])非常有效,但一个关键挑战出现了:*发送*来自该地址的邮件。
Cloudflare 目前缺乏虚拟 SMTP 服务,这意味着回复将默认使用用户的个人邮箱。讨论中的解决方案包括 Mailgun 的免费套餐,用于低流量的 SMTP 访问,以及 Google Workspace(一种付费的按席位计费选项)。
一些评论者指出,由于激进的 SPF/DMARC 策略,Cloudflare 的 IP 地址可能被微软列入黑名单,从而导致潜在的邮件传递问题。原作者澄清,该服务旨在作为企业早期阶段的*临时*解决方案,在投资完整的邮箱解决方案(如 Google Workspace)*之前*使用,那时使用自定义域名发送邮件将变得简单。这是 Cloudflare 预期功能的有效利用,而不是变通方法。
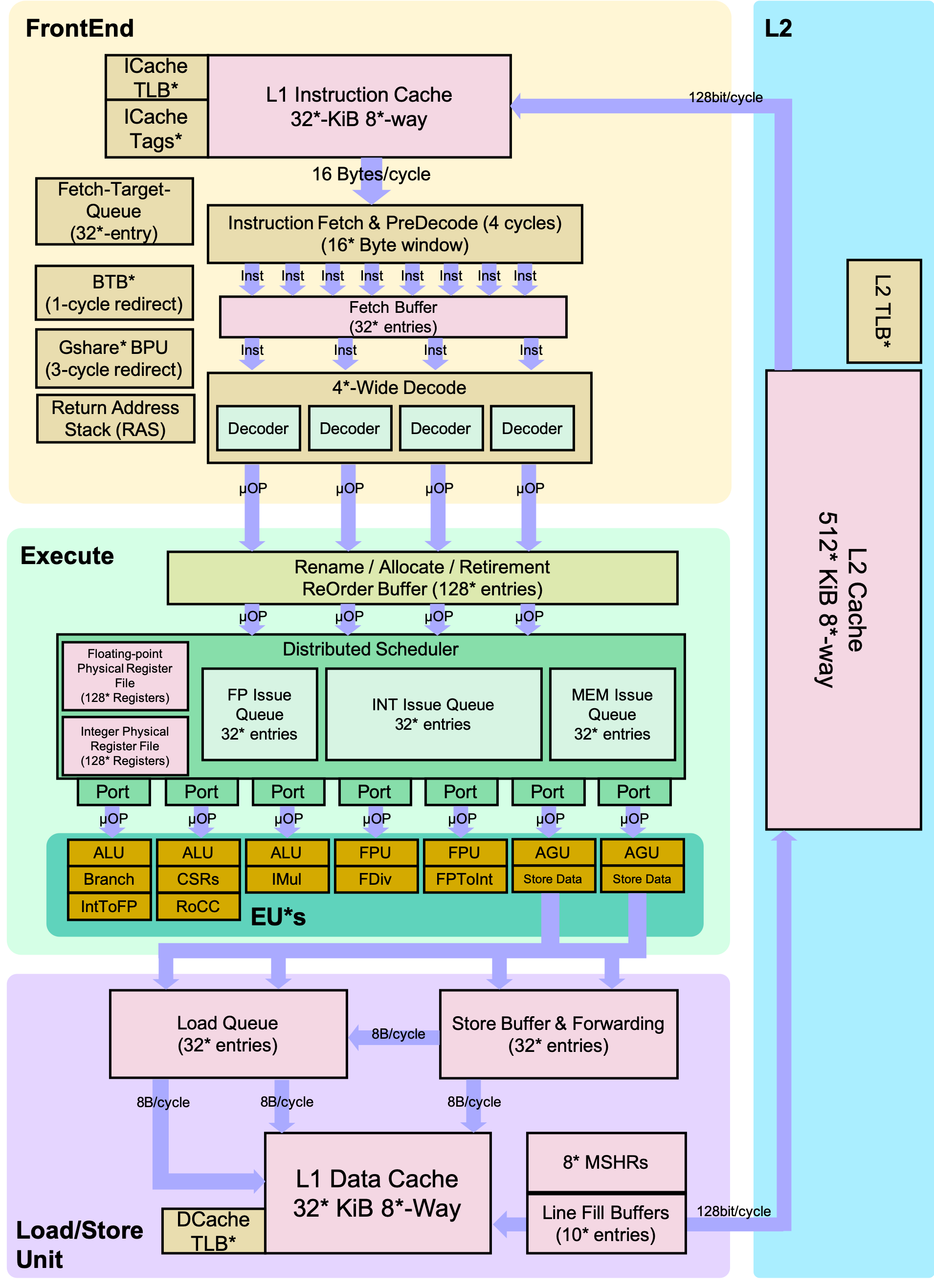 图1. 详细的BOOM流水线。*表示核心可以配置的位置。伯克利乱序机器(BOOM)深受MIPS R10000和Alpha 21264乱序处理器的启发。与MIPS R10000和Alpha 21264一样,BOOM采用统一的物理寄存器文件设计(也称为“显式寄存器重命名”)。BOOM实现了开源的RISC-V ISA,并利用Chisel硬件构造语言构建核心生成器。生成器可以被认为是一种广义的RTL设计。标准的RTL设计可以看作是生成器设计的一个实例。因此,BOOM是一个乱序设计的家族,而不是单个核心实例。此外,为了使用BOOM核心构建SoC,BOOM利用Rocket Chip SoC生成器作为一个库来重用不同的微架构结构(TLB、PTW等)。
图1. 详细的BOOM流水线。*表示核心可以配置的位置。伯克利乱序机器(BOOM)深受MIPS R10000和Alpha 21264乱序处理器的启发。与MIPS R10000和Alpha 21264一样,BOOM采用统一的物理寄存器文件设计(也称为“显式寄存器重命名”)。BOOM实现了开源的RISC-V ISA,并利用Chisel硬件构造语言构建核心生成器。生成器可以被认为是一种广义的RTL设计。标准的RTL设计可以看作是生成器设计的一个实例。因此,BOOM是一个乱序设计的家族,而不是单个核心实例。此外,为了使用BOOM核心构建SoC,BOOM利用Rocket Chip SoC生成器作为一个库来重用不同的微架构结构(TLB、PTW等)。
## RISC-V 处理器开发:开源 vs. 专有
一则 Hacker News 讨论关注 RISC-V 处理器的当前实现状态。目前,像 XiangShan 这样的开源 RTL(寄存器传输级)设计通常比商业硅芯片*更快*。然而,这是将开发代码与成品进行比较。Tenstorrent 等公司拥有性能超过 XiangShan 的生产就绪 IP,并计划于 2026 年发布。
争论的焦点在于开源是否能保持这一领先地位。虽然预计开源势头将持续,但现实的长期结果可能是专有设计领先 1-3 年。值得注意的是,有用户提到一款高性能 RISC-V 芯片(受保密协议约束)已经超越了现有实现。
对话还强调了系统研究的选项。对于适合 FPGA(如 Artix A7)的简单、可综合设计,推荐包括 Rocket-chip、PicoRV32、neorv32 以及 OpenHW Foundation(Ibex)的核心。AwesomeRISC-V 和 Hazard3(用于 RP2350)等资源也被分享。
## 安全飞地受到攻击:摘要
最新研究表明,新的、相对低复杂度的攻击正在破坏 Nvidia、AMD 和 Intel 开发的安全飞地的安全性。这些飞地——专为机密计算、DRM 和其他安全敏感任务设计——通过物理操纵内存芯片而变得易受攻击。
讨论的核心在于安全飞地的*目的*。虽然制造商宣传数据保护和安全启动等好处,但许多用户主要将其视为 DRM 和控制的工具,阻碍了用户自由。人们对信任飞地提供商处理敏感数据以及对其实现缺乏透明度表示担忧。
一些人认为安全飞地可以为恶意软件和受损系统提供有价值的保护,而另一些人则强调需要用户对其设备拥有完全控制权,并倡导开源替代方案。这些攻击需要物理访问和操作系统妥协,表明仅仅依赖硬件安全存在局限性。 提出了微内核和强大的沙盒等解决方案,并呼吁制定具有法律效力的标准,赋予用户对设备完全控制权。
 ## 德语游戏:通过游戏学习德语
德语游戏提供一种有趣、互动的方式,通过各种引人入胜的游戏学习德语。该平台专注于培养核心语言技能,涵盖词汇和语法基础。
游戏包括练习**数字**(双向 – 单词到数字 & 数字到单词)、**讲时间**(包括简短形式,如 *nach* 和 *halb*)以及掌握**德语冠词** (*der, die, das*)。
你还可以通过德语到英语和英语到德语的翻译练习来扩展你的**词汇**,涵盖**名词和动词**。最后,通过练习所有代词的现在时形式来加强你的**动词变位**技能。
德语游戏提供多样化的学习体验,通过反向翻译和有针对性的练习,满足不同水平和学习风格的需求。
## 德语游戏:通过游戏学习德语
德语游戏提供一种有趣、互动的方式,通过各种引人入胜的游戏学习德语。该平台专注于培养核心语言技能,涵盖词汇和语法基础。
游戏包括练习**数字**(双向 – 单词到数字 & 数字到单词)、**讲时间**(包括简短形式,如 *nach* 和 *halb*)以及掌握**德语冠词** (*der, die, das*)。
你还可以通过德语到英语和英语到德语的翻译练习来扩展你的**词汇**,涵盖**名词和动词**。最后,通过练习所有代词的现在时形式来加强你的**动词变位**技能。
德语游戏提供多样化的学习体验,通过反向翻译和有针对性的练习,满足不同水平和学习风格的需求。
## 通过游戏学习德语:Hacker News 总结
Hacker News 上的一位用户分享了 [learngermanwithgames.com](https://learngermanwithgames.com),这是一个他们创建的网站,旨在通过互动测验和游戏使德语学习更具吸引力。 由于对语言的任意规则感到沮丧,他们旨在构建一种有趣的方式来记忆词汇和语法。
初步反馈褒贬不一。 一些用户赞赏其精美的用户界面,并认为它有助于练习,尤其是在名词性别等具有挑战性的方面。 其他用户指出,这些活动更像是测验而不是游戏,并且存在一些准确性问题——包括拼写错误和值得怀疑的“正确”答案,可能源于人工智能生成的内容。
一些评论者建议将该网站与其他学习方法结合使用,例如通过游戏(《模拟人生》、《汤姆克兰西:全境封锁》)进行沉浸式学习或参加传统课程。 讨论涉及德语的区域差异以及时间表达的细微差别。 创建者承认这些反馈,并计划改进该网站,增加更多游戏元素并解决不准确问题。
尽管存在批评,但该项目被视为将语言学习游戏化的一项有希望的努力,并且有多位用户鼓励进一步开发。
视网膜假体是首个恢复因黄斑变性失明的视力设备。
Eye prosthesis is the first to restore sight lost to macular degeneration
32 天前
一种名为PRIMA的新型无线视网膜植入物正在帮助患有年龄相关性黄斑变性症的患者恢复部分视力。这块2x2毫米的芯片植入在光感受器丧失的区域,通过将特殊眼镜发出的红外光转换为电信号来工作,从而保留现有的周边视力。 为期一年的38名患者的试验显示,视力显著改善——平均在视力表上提高5行,其中一名患者提高了12行,从而能够阅读和执行识别标志等日常任务。虽然目前提供黑白视觉,但开发者正在努力实现灰度显示和面部识别功能。 该设备由光供电,无需外部电缆,但一些患者经历了轻微的副作用,如眼压升高。未来的迭代旨在提高分辨率,使用更小的像素,有可能实现接近20/20的视力,并具有电子变焦功能。研究人员也在探索将其用于其他导致光感受器丧失的原因。
## 新型眼假体帮助黄斑变性患者恢复视力
斯坦福大学开发的一种新型眼假体正在为黄斑变性患者恢复部分视力方面显示出令人鼓舞的结果。据Hacker News报道,该设备在三分之二的参与者中实现了中等到较高的用户满意度。
然而,评论员指出其局限性:目前的原型提供黑白视觉,分辨率较低,仅为378像素,需要用户调整亮度和一次专注于一个单词。适应这项技术也可能具有挑战性,因为它将人工信号与现有的周边视力融合。
尽管存在这些障碍,这项发展仍被誉为视力相关医疗保健领域的一项重大进展。讨论还涉及未来增强的可能性,包括夜视功能,甚至(目前还很遥远)直接的脑机接口——引发了人们对潜在滥用的兴奋和担忧。这项技术代表着类人化医疗植入体领域向前迈出的一步。
## Brahma-JS:结合Rust性能的JavaScript便利性
Brahma-JS是一款新的JavaScript编排器,专为速度而设计,它结合了熟悉的Express风格API和高性能Rust核心(基于Tokio + Hyper)。它非常适合对低延迟至关重要的微服务和API。
主要特性包括类似Express的开发体验、轻量级的零依赖二进制文件,以及在基准测试中展示的**超过130,000次请求每秒**的性能,同时延迟较低(约1.5毫秒)。开发者可以利用现有的JavaScript技能,而无需Rust专业知识。
Brahma-JS提供诸如中间件、异步处理程序、CORS配置、cookie管理、重定向和优雅关机等功能。它还为macOS、Linux和Windows提供预构建的二进制文件,简化了部署。
目前处于Beta阶段,Brahma-JS正在积极开发中,并鼓励社区反馈。它是Brahma-Core的一个分支,并以MIT许可证作为开源项目提供。安装可以通过npm、yarn、pnpm、bun或nypm轻松完成。
 ## 从 VS Code 到 Helix:编辑器与理念的转变
最初,作者是 VS Code 的忠实用户,后来因为担心微软的控制和数据实践,以及希望减少对技术的过度依赖,转而使用 Helix。虽然 VS Code 的易用性和丰富的扩展令人吸引,但作者越来越不喜欢依赖一家美国垄断公司。
采用 Helix 的最大障碍是认为学习曲线陡峭。然而,该编辑器“开箱即用”的理念——优先考虑开箱即用的功能并利用语言服务器——出人意料地有效。Helix 编辑时先选择文本再进行操作的视觉化方式与作者的工作流程产生了共鸣。
设置过程包括安装 Markdown(使用 Harper 进行语法检查和 rumdl 进行代码检查)、Astro 和 YAML 的语言支持。虽然比 VS Code 需要更多的初始配置,但作者发现这个过程是可以管理的,并且受益于出色的文档(包括一个优秀的第三方资源)。
最终,Helix 对效率和简化体验的关注赢得了作者的青睐。尽管作者承认该项目存在维护挑战(大量的 PR backlog),但他欣赏其原则,并认为这是朝着更开放和平衡的技术生态系统迈出的一步。
## 从 VS Code 到 Helix:编辑器与理念的转变
最初,作者是 VS Code 的忠实用户,后来因为担心微软的控制和数据实践,以及希望减少对技术的过度依赖,转而使用 Helix。虽然 VS Code 的易用性和丰富的扩展令人吸引,但作者越来越不喜欢依赖一家美国垄断公司。
采用 Helix 的最大障碍是认为学习曲线陡峭。然而,该编辑器“开箱即用”的理念——优先考虑开箱即用的功能并利用语言服务器——出人意料地有效。Helix 编辑时先选择文本再进行操作的视觉化方式与作者的工作流程产生了共鸣。
设置过程包括安装 Markdown(使用 Harper 进行语法检查和 rumdl 进行代码检查)、Astro 和 YAML 的语言支持。虽然比 VS Code 需要更多的初始配置,但作者发现这个过程是可以管理的,并且受益于出色的文档(包括一个优秀的第三方资源)。
最终,Helix 对效率和简化体验的关注赢得了作者的青睐。尽管作者承认该项目存在维护挑战(大量的 PR backlog),但他欣赏其原则,并认为这是朝着更开放和平衡的技术生态系统迈出的一步。
 ## LeRobot 剧集评分工具摘要
该工具集提供了一种使用传统计算机视觉指标和可选的Gemini驱动的视觉-语言模型(VLM)检查来自动评估LeRobot演示剧集质量的方法。它在视觉清晰度、流畅性、碰撞检测、运行时和任务成功等维度上对剧集进行评分,为每个维度分配0-1的分数。
该工具集允许用户过滤低质量剧集以改进下游训练,并比较在过滤数据集与未过滤数据集上训练的模型性能。主要功能包括:对数据集进行评分、根据用户定义的阈值过滤剧集以及与LeRobot的训练流程集成。
用户可以选择基于OpenCV的视觉评分,或利用Gemini进行基于VLM的分析(需要Google API密钥)。该工具集可通过pip轻松安装,并提供命令行参数以进行自定义,包括数据集位置、输出路径和训练选项。会生成详细的评分报告和可视化效果,以帮助识别有问题剧集并优化数据集质量。
## LeRobot 剧集评分工具摘要
该工具集提供了一种使用传统计算机视觉指标和可选的Gemini驱动的视觉-语言模型(VLM)检查来自动评估LeRobot演示剧集质量的方法。它在视觉清晰度、流畅性、碰撞检测、运行时和任务成功等维度上对剧集进行评分,为每个维度分配0-1的分数。
该工具集允许用户过滤低质量剧集以改进下游训练,并比较在过滤数据集与未过滤数据集上训练的模型性能。主要功能包括:对数据集进行评分、根据用户定义的阈值过滤剧集以及与LeRobot的训练流程集成。
用户可以选择基于OpenCV的视觉评分,或利用Gemini进行基于VLM的分析(需要Google API密钥)。该工具集可通过pip轻松安装,并提供命令行参数以进行自定义,包括数据集位置、输出路径和训练选项。会生成详细的评分报告和可视化效果,以帮助识别有问题剧集并优化数据集质量。
黑客新闻 新 | 过去 | 评论 | 提问 | 展示 | 招聘 | 提交 登录 展示HN:自动化机器人数据质量改进 (github.com/roboticsdata)
9点 由 machinelearning 1天前 | 隐藏 | 过去 | 收藏 | 1评论
marshavoidance 1天前 [–]
这个工具通过分析模糊、碰撞和运动平滑度来“评估”机器人演示片段,然后从数据集中过滤掉不良片段。这似乎是一种务实的方法来解决机器人领域的数据质量问题,很期待看到它在实际训练中的效果。回复
考虑申请YC冬季2026批次!申请截止日期为11月10日
指南 | 常见问题 | 列表 | API | 安全 | 法律 | 申请YC | 联系
搜索:
 ## Bear Blog 中断与机器人问题 - 摘要
2025年10月25日,Bear Blog 经历了一次重大中断,由于反向代理故障影响了自定义域名。根本原因并非服务器容量,而是机器人流量激增——这是一个日益严重的问题,包括人工智能爬虫、恶意行为者和不受控制的自动化程序。这些机器人正在席卷互联网,其驱动力是大型语言模型训练的数据价值以及越来越容易部署的爬取工具。
现有的机器人缓解措施(WAF、速率限制)处理了最初的每分钟数万次请求的浪潮,但反向代理却不堪重负。关键是,作者的主要监控系统*未能*向他们发出警报,延长了停机时间。
为了防止再次发生,已经采取了几个步骤:冗余监控,带有电话/电子邮件/短信警报,增加反向代理容量(5倍),更积极的机器人缓解措施,以及自动重启功能。一个公开状态页面([https://status.bearblog.dev](https://status.bearblog.dev))也已启动,以提高透明度。
作者强调了日益恶劣的互联网环境,该环境由机器人主导,以及保护宝贵在线空间的重要性。
## Bear Blog 中断与机器人问题 - 摘要
2025年10月25日,Bear Blog 经历了一次重大中断,由于反向代理故障影响了自定义域名。根本原因并非服务器容量,而是机器人流量激增——这是一个日益严重的问题,包括人工智能爬虫、恶意行为者和不受控制的自动化程序。这些机器人正在席卷互联网,其驱动力是大型语言模型训练的数据价值以及越来越容易部署的爬取工具。
现有的机器人缓解措施(WAF、速率限制)处理了最初的每分钟数万次请求的浪潮,但反向代理却不堪重负。关键是,作者的主要监控系统*未能*向他们发出警报,延长了停机时间。
为了防止再次发生,已经采取了几个步骤:冗余监控,带有电话/电子邮件/短信警报,增加反向代理容量(5倍),更积极的机器人缓解措施,以及自动重启功能。一个公开状态页面([https://status.bearblog.dev](https://status.bearblog.dev))也已启动,以提高透明度。
作者强调了日益恶劣的互联网环境,该环境由机器人主导,以及保护宝贵在线空间的重要性。
## 黑客新闻讨论:恶意机器人与网络爬虫
最近的黑客新闻讨论强调了日益严重的网络爬虫问题及其对小型网站的影响。原发帖人 shaunpud 描述了由无情的机器人引起的周末中断。
对话揭示了一种令人不安的趋势:爬虫越来越多地使用住宅代理——通常通过提供“免费”服务的应用程序,这些应用程序秘密出售带宽——这使得阻止变得困难。 多位评论员证实了这种做法,提到了 Bright Data (Luminati) 等服务,它们甚至为它们攻击的网站提供“保护费”。
讨论的解决方案包括实施更严格的速率限制和蜜罐(例如,针对恶意 IP 的炸弹压缩包),以及利用 CDN。 然而,许多人承认了局限性,尤其是在复杂的机器人规避检测技术日益提高以及在法律上追究攻击者责任的难度增加的情况下。
一种核心观点浮出水面:互联网正变得越来越敌对,维护独立的、小型网络服务正变得不可持续。 虽然一些人提倡为保护这些空间而奋斗,但另一些人认为挑战太大,中心化的趋势不可避免。 讨论还涉及了爬虫的伦理影响以及对数据访问更好标准的需求。