## SQLite-Graph:SQLite 的图数据库扩展(Alpha)
SQLite-Graph 是一个处于 Alpha 阶段的 SQLite 扩展,它带来了图数据库功能,并提供**完整的、基本的 Cypher 查询支持**。作为 AgentFlare AI 生态系统的一部分开发,它允许利用 SQLite 的可靠性和 Cypher 的表达力来构建复杂的图应用程序。
**主要特性:**核心图操作(通过 SQL 创建、读取、更新、删除节点/边)、端到端 Cypher 执行(包括 `CREATE`、`MATCH`、`WHERE` 和 `RETURN`)、图虚拟表以及基本的图算法(连通性、密度、中心性)。它拥有令人印象深刻的性能——**30 万+ 节点/秒和 39 万+ 边/秒**——并包含 **Python 3.6+ 绑定**。
**目前,由于其 Alpha 状态和潜在的 API 变更,不建议将此扩展用于生产环境**。开发重点是实现完全的 openCypher 兼容性、高级查询功能和性能优化,路线图一直延伸到 2027 年。
**安装**涉及下载预构建的二进制文件或从源代码构建。基本用法示例演示了 Cypher 查询和基于 SQL 函数的图操作。
每日HackerNews RSS
## SQLite 图形扩展:摘要
一个名为 SQLite Graph Ext 的新 alpha 项目,使用 Cypher 查询语言为 SQLite 带来了图形数据库功能。由 Agentflare AI 开发,它允许用户在现有的 SQLite 数据库中创建和查询图形,而无需单独的图形数据库系统。
该扩展拥有令人印象深刻的性能——高达 340K 节点/秒的插入速度和 390K 边/秒的创建速度——并利用完全的执行流水线(词法分析器、解析器、计划器、执行器),用 C99 构建,没有外部依赖。目前,它支持节点和关系创建、基本过滤以及结果的 JSON 序列化。
虽然仍处于早期阶段,但其局限性包括仅支持正向关系、不支持关系属性过滤以及缺乏聚合等高级功能。开发者计划在 2026 年第一季度实现对 Cypher 的完全支持,优先考虑双向关系和属性投影。该项目采用 MIT 许可,并欢迎反馈,定位为现有 SQLite 用户的一个轻量级、集成的图形解决方案——类似于 SQLite 的 FTS5 扩展,用于全文搜索。
[GitHub 仓库](https://github.com/agentflare-ai/sqlite-graph)
这篇文章解释了迷人的**抖动**过程,这是一种用于创造*看起来*比实际可用的颜色更多的技术的手段。具体来说,它着重介绍了抖动如何使用只有黑白像素来模拟灰度阴影。 与简单地将像素映射到最接近的可用颜色(导致生硬的过渡)不同,抖动策略性地以图案分布黑白像素。更密集的黑色浓度产生更深的阴影,而更密集的白色浓度产生更浅的阴影。 一种方法,**有序抖动**,利用**阈值图**——一个将每个像素的亮度与设定的值进行比较的网格。如果像素比阈值亮,它就变成白色;否则,变成黑色。在整个图像上重复此过程,通过不同的像素密度来重现阴影。 本质上,抖动不是*添加*效果,而是巧妙地*移除*颜色信息,同时保留整体视觉外观。这是三部分系列文章的第一部分,未来将计划探索不同的抖动算法,例如阈值图创建和误差扩散。
## 抖动解释:黑客新闻总结
最近黑客新闻上出现了一场关于抖动(visualrambling.space)的讨论,该内容以视觉化的方式呈现。文章的展示广受好评,但也引发了关于什么才是真正的“抖动”,以及与半调等相关技术的区别的争论。
一些人认为,文中展示的技术,使用图案来*看起来*增加颜色深度,并非真正的抖动,他们将抖动定义为在颜色调色板有限的情况下,使用噪声来平滑颜色分层。另一些人则指出,定义中包含有序抖动也是一种抖动形式,即使没有明确的噪声。
讨论延伸到抖动的历史和细微之处,提到了早期Windows界面和现代应用程序(Squoosh.app、GIMP)中使用的技术,甚至包括游戏开发(Obra Dinn、Quake纹理)。 许多用户分享了资源,包括Rust和Go中的代码实现,以及来自Coding Train等来源的相关YouTube解释链接。
最终,这场讨论突出了颜色表示的复杂性,以及对创造*看起来*比实际可用的更多色调的技术的持续迷恋。
 Extropic 正在开发革命性的热力学计算硬件,旨在比传统 GPU 更加节能,尤其是在 AI 工作负载方面。他们的核心创新——热力学采样单元 (TSU) 本质上是概率性的,与概率 AI 算法完美契合。
为了方便开发,Extropic 提供 XTR-0 平台,用于低延迟的芯片到处理器的通信,以及 THRML,一个用于算法创建和 TSU 模拟的开源 Python 库。
Extropic 通过多次媒体露面(Wired、TED AI、Lex Fridman & Garry Tan 的播客)和详细介绍其技术的出版物而备受关注。他们正在积极扩大团队,寻找工程师和科学家来推进这种新的计算范式。最终,Extropic 旨在以其节能的 AI 处理方法颠覆当前的数据中心格局。
Extropic 正在开发革命性的热力学计算硬件,旨在比传统 GPU 更加节能,尤其是在 AI 工作负载方面。他们的核心创新——热力学采样单元 (TSU) 本质上是概率性的,与概率 AI 算法完美契合。
为了方便开发,Extropic 提供 XTR-0 平台,用于低延迟的芯片到处理器的通信,以及 THRML,一个用于算法创建和 TSU 模拟的开源 Python 库。
Extropic 通过多次媒体露面(Wired、TED AI、Lex Fridman & Garry Tan 的播客)和详细介绍其技术的出版物而备受关注。他们正在积极扩大团队,寻找工程师和科学家来推进这种新的计算范式。最终,Extropic 旨在以其节能的 AI 处理方法颠覆当前的数据中心格局。
## 外向型:一种新的计算方法?
Extropic 正在开发新型热力学计算硬件,旨在提高特定人工智能任务的效率——特别是扩散模型中的去噪步骤。他们正在构建能够生成可控随机性的硬件,超越简单的随机数生成(RNG),提供复杂的概率分布。
尽管有些人持怀疑态度,并引用了类似概念过去的失败案例(例如早期硬件 RNG 的尝试),但另一些人则看到了潜力。核心思想是在标准 CMOS 工艺中实现的模拟计算,可能提供四倍数量级的加速。然而,人们仍然担心这是否是一个可行的创业项目,而不仅仅是大学研究项目。
该公司最近发布了一个原型平台“XTR-0”,引发了对其合法性和实际效用的争论。有些人认为这是一个骗局或过度炒作,而另一些人则持谨慎乐观态度。网站本身虽然视觉效果令人印象深刻,但让一些人担心它将美学放在了实质之上。
最终,Extropic 的成功取决于展示相对于现有技术的切实好处,以及有效地扩展其硬件。
Uv 是过去十年 Python 生态系统中最好的事情。
Uv is the best thing to happen to the Python ecosystem in a decade
32 天前
## 使用 `uv` 简化 Python 开发 对 Python 环境管理的复杂性感到沮丧吗?Astral 的全新、免费且开源工具 `uv` 旨在彻底改变这一过程。`uv` 使用 Rust 构建,具有速度快和跨平台兼容性,可以处理 Python 版本安装、包管理、虚拟环境和依赖关系解析——通常比现有工具更快。 安装简单,大多数操作系统只需一行命令即可。`uv` 无缝利用 `pyproject.toml` 文件来定义项目依赖项和 Python 版本。关键命令包括 `uv init` 用于启动新项目,`uv sync` 用于安装依赖项并创建锁定环境(确保团队之间的一致性),以及 `uv run` 用于在正确环境中执行命令,无需激活。 使用 `uv add` 可以简化添加依赖项的操作,并且可以为项目稳定性固定特定的 Python 版本。对于快速的一次性任务,`uvx` 提供了一张“赦免卡”,在临时环境中运行工具。 `uv` 已经证明对于团队来说非常有价值,例如 The Astrosky Ecosystem 的开发者,确保在各种系统上安装一致的 Python 版本,并简化 CI/CD 管道。它是 Python 开发领域的重要一步,提供更简单、更快、更可靠的体验。 了解更多信息,请访问 [uv 文档](https://uv.readthedocs.io/en/latest/)。
## Uv:Python 的潜在游戏规则改变者
最近的 Hacker News 讨论强调了 **uv**,这是一种在 Python 生态系统中越来越受欢迎的新工具,许多人称其为十年来的最佳改进。Uv 旨在通过结合通常由 `pip`、`pyenv` 和 `virtualenv` 等独立工具处理的功能来简化 Python 开发。
用户称赞其速度、符合人体工程学的 CLI 以及“开箱即用”的方法,简化了依赖项和 Python 版本管理。一些开发者,之前使用 `pyenv` 和 `poetry`,报告解决了长期存在的依赖项解析和系统包兼容性问题。
虽然有些人更喜欢成熟的工具,如 `venv` 或 `conda`,但许多人发现 uv 显著改善了他们的工作流程,尤其是在与 `ruff` 等工具结合使用时。Astral,uv 背后的公司,还提供付费产品 Pyx,表明其具有可持续的商业模式。有人对供应商锁定表示担忧,但另一些人指出 Astral *源于* 这些开源工具,因此追求可持续性是合理的。最终,uv 似乎是一种很有前途的工具,可以提供更集成和高效的 Python 开发体验。
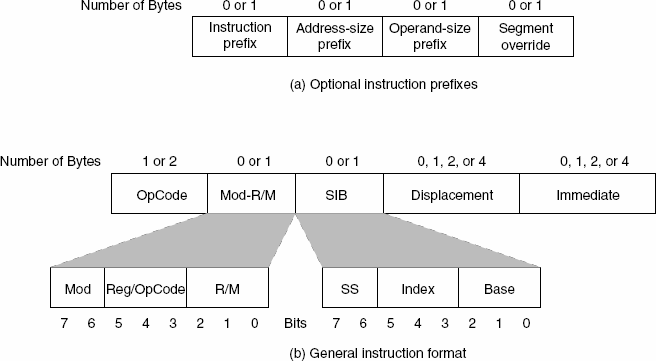 ## x86 指令编码概要
本文概述了 x86 指令编码的基础知识。x86 指令使用一个或两个字节的 opcode,第二个字节用于 opcode *扩展*(前缀 `0Fh`)。这些 opcode 编码了操作、操作数及其大小。
一个关键组成部分是 **MOD-REG-R/M 字节**,它指定操作数寻址模式——数据是在寄存器中还是内存中,以及任何位移值。**MOD** 字段定义寻址模式,**REG** 标识一个寄存器,**R/M** 指定第二个操作数或单操作数指令的唯一操作数。opcode 中的方向位 (`d`) 决定了源/目的地的角色。
操作数大小由 opcode 中的一位 (`s`) 指示,使用前缀字节 (`66h`) 来指定 32 位环境中的 16 位操作数。还存在其他前缀,用于重复字符串 (`REP`, `REPE`, `REPNE`)、段覆盖以及操作数/地址大小修改。
Intel 提供了针对常用指令的替代、更短的编码,使用累加器寄存器 (AL, AX, EAX) 来优化代码大小。理解这些编码需要查阅诸如 Intel 架构软件开发人员手册之类的资源,特别是第 2 卷(指令集参考),其中详细介绍了每个指令的机器代码表示。x86 架构代表了功能、效率和向后兼容性之间复杂的平衡。
## x86 指令编码概要
本文概述了 x86 指令编码的基础知识。x86 指令使用一个或两个字节的 opcode,第二个字节用于 opcode *扩展*(前缀 `0Fh`)。这些 opcode 编码了操作、操作数及其大小。
一个关键组成部分是 **MOD-REG-R/M 字节**,它指定操作数寻址模式——数据是在寄存器中还是内存中,以及任何位移值。**MOD** 字段定义寻址模式,**REG** 标识一个寄存器,**R/M** 指定第二个操作数或单操作数指令的唯一操作数。opcode 中的方向位 (`d`) 决定了源/目的地的角色。
操作数大小由 opcode 中的一位 (`s`) 指示,使用前缀字节 (`66h`) 来指定 32 位环境中的 16 位操作数。还存在其他前缀,用于重复字符串 (`REP`, `REPE`, `REPNE`)、段覆盖以及操作数/地址大小修改。
Intel 提供了针对常用指令的替代、更短的编码,使用累加器寄存器 (AL, AX, EAX) 来优化代码大小。理解这些编码需要查阅诸如 Intel 架构软件开发人员手册之类的资源,特别是第 2 卷(指令集参考),其中详细介绍了每个指令的机器代码表示。x86 架构代表了功能、效率和向后兼容性之间复杂的平衡。
## Hacker News 上关于 x86 指令编码的讨论
一篇 Hacker News 讨论,源于一个关于 x86 指令编码的资源链接 ([https://www-user.tu-chemnitz.de/~heha/hs/chm/x86.chm/](https://www-user.tu-chemnitz.de/~heha/hs/chm/x86.chm/)),揭示了一个令人惊讶的共识:理解 x86 编码比通常认为的要简单,*如果* 你超越了专注于原始 8086 处理器的过时解释。
几位评论者分享了编写自己的解码器和编码器的经验,指出现代 x86 解码的复杂性低于预期。 另一些人强调了与 x86 相比,ARM64 编码的相对简单性,尽管 ARM64 以其复杂性而闻名。 讨论还涉及 x86 的历史背景、其演变(包括 AMD 的贡献),以及由于分支预测和缓存的进步,解码复杂性在现代处理器中日益无关紧要。
诸如 sandpile.org 和一个关于 x86 汇编的 YouTube 播放列表等资源被分享,以及指向 x86-64 编码更新文档的链接。 讨论最终质疑了在现代硬件能力下 x86 复杂性的必要性,同时承认了它在计算领域中的持续存在。
请启用 JavaScript 并禁用任何广告拦截器。
## 一百年的时钟调整:英国夏令时历史 自1925年夏令时法案以来,英国已经与夏令时的复杂性斗争了100年。这始于威廉·威莱特在1907年提出的提前时钟的提议,最初被议会拒绝,但在第一次世界大战期间于1916年采用。随后的几十年里,出现了一系列混乱的调整——日期每年变化,受到战争需求(如二战期间的“双夏令时”)和燃料短缺(导致1947年四次时钟调整!)的影响。 1925年规则得到简化,但随着调查和试验,规则不断演变,包括在20世纪60年代末对永久使用GMT+1(英国标准时间)进行为期三年的试验,最终被放弃。 1980年代和90年代的欧盟指令带来了进一步的协调,最终确定了在三月最后一个星期日提前时钟,并在十月最后一个星期日恢复原时制——这一制度已经实施了30年。尽管英国脱欧为改变提供了机会,但这一问题的分裂性质以及与爱尔兰可能出现的复杂情况意味着“最后一个星期日”的规则可能仍将保留,在经历了百年的“麻烦和调整”之后,提供一定程度的简单性。
这个Hacker News讨论围绕着英国夏令时(BST)的历史和原因。一位用户zeristor分享了一篇关于BST历史的博客文章,引发了关于其用处性的讨论。
一个关键点是,常见的支持BST的论点——例如帮助上学通勤和农业——实际上支持全年使用格林威治标准时间(GMT)。六月晚日落的好处,与坚持使用GMT的潜在优势进行了权衡。
该帖子还包含来自皇家格林威治博物馆的更多阅读链接,以及关于“geezer”一词在美式英语和英式英语中不同含义的简短语言说明。最后,发布了一则Y Combinator申请公告。
关于 新闻 版权 联系我们 创作者 广告 开发者 条款 隐私政策和安全 YouTube 工作原理 测试新功能 © 2025 Google LLC
Character.AI 将禁止 18 岁以下儿童使用其聊天机器人。
Character.ai to bar children under 18 from using its chatbots
32 天前
请启用 JavaScript 并禁用任何广告拦截器。
## Character.AI 将屏蔽未成年用户
Character.AI 宣布将禁止 18 岁以下用户使用,并采用技术检测年龄,依据对话、互动和关联社交媒体。此举源于对人工智能辅助的有害互动和潜在法律责任的担忧。
Hacker News 上的讨论显示,人们对检测方法的有效性表示怀疑,许多人认为精通技术的孩子可以绕过限制。一些人认为,此举主要是为了法律保护,而非真正的安全问题,并指出谷歌对 Character.AI 的收购是一个因素。
强制性身份验证等替代方案正在讨论中,但存在隐私方面的担忧。另一些人建议关注家长责任,或采取基于成熟度而非年龄的更细致的方法。一个关键点是可能出现误报,以及准确评估在线行为的困难。 许多评论员强调了在互联网上平衡匿名性和安全性的更广泛问题。
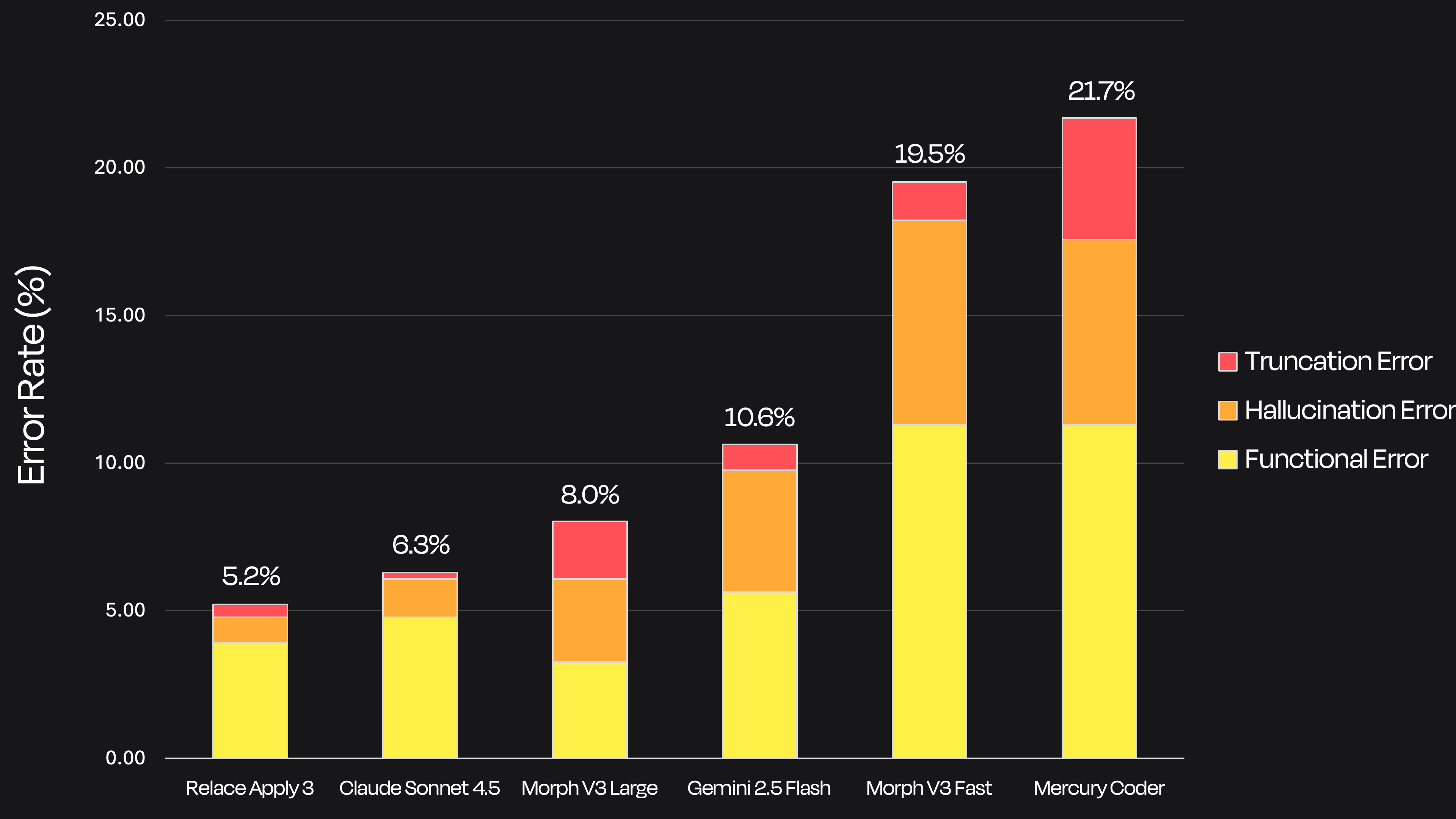 ## Relace Apply 3:开源一款快速且准确的代码合并模型
在发布最初的Fast Apply模型一年后,Relace正在开源**Relace Apply 3**背后的经验,该模型在代码合并方面实现了**每秒10k+ tokens**的性能,并具有最先进的准确性。解决的核心问题是使用大型语言模型重新生成整个代码库以进行小幅修改效率低下——这是一个代价高昂且缓慢的过程。
Relace的解决方案采用“diff & apply”方法:前沿模型生成最小的代码更改(diff),而一个更小、更专业的“apply模型”有效地合并这些更改。他们发现高质量、多样化的数据集(约14.5万个示例)至关重要,优先考虑质量而非单纯的大小。该数据集是通过与prompt-to-app公司合作来捕捉真实世界的合并场景创建的,然后使用LLM作为裁判进行可扩展的质量控制。
训练利用了开源模型上的**LoRA**(参数量为3-8B)和**FP8量化**以提高速度。**推测解码**进一步提升了推理速度,利用了代码合并的可预测性。Relace Apply 3在准确性方面超越了之前的模型,尤其是在复杂的编辑方面,并支持256k上下文窗口。这项工作展示了专门的小模型在目标数据上进行训练的强大力量,Relace正在将这种策略扩展到其他编码任务。他们正在积极招聘以继续这项研究。
## Relace Apply 3:开源一款快速且准确的代码合并模型
在发布最初的Fast Apply模型一年后,Relace正在开源**Relace Apply 3**背后的经验,该模型在代码合并方面实现了**每秒10k+ tokens**的性能,并具有最先进的准确性。解决的核心问题是使用大型语言模型重新生成整个代码库以进行小幅修改效率低下——这是一个代价高昂且缓慢的过程。
Relace的解决方案采用“diff & apply”方法:前沿模型生成最小的代码更改(diff),而一个更小、更专业的“apply模型”有效地合并这些更改。他们发现高质量、多样化的数据集(约14.5万个示例)至关重要,优先考虑质量而非单纯的大小。该数据集是通过与prompt-to-app公司合作来捕捉真实世界的合并场景创建的,然后使用LLM作为裁判进行可扩展的质量控制。
训练利用了开源模型上的**LoRA**(参数量为3-8B)和**FP8量化**以提高速度。**推测解码**进一步提升了推理速度,利用了代码合并的可预测性。Relace Apply 3在准确性方面超越了之前的模型,尤其是在复杂的编辑方面,并支持256k上下文窗口。这项工作展示了专门的小模型在目标数据上进行训练的强大力量,Relace正在将这种策略扩展到其他编码任务。他们正在积极招聘以继续这项研究。
Relace.ai 实现了每秒 10,000 个 token 的处理速度,这得益于其“快速应用”模型,该模型旨在快速应用对大型语言模型生成的代码的编辑。他们成功的关键在于构建了一个内部评估工具——一种 Git 样式的差异查看器,用于分类合并结果并保持质量。
与类似的 MorphLLM 模型相比,Relace.ai 的方法优先考虑速度而非对代码进行广泛的“平滑处理”。虽然平滑处理可以修复简单的错误,但会增加引入更复杂、破坏性幻觉(不正确的代码更改)的风险。MorphLLM 的较慢、较大的模型似乎平滑处理得更激进,而其较快版本则表现出奇怪的错误,这可能是由于激进的量化造成的。
讨论还涉及定价问题,Relace.ai 为大批量用户提供折扣,并寻求对成本可行性的反馈。最终,Relace.ai 专注于在代码应用中实现速度和准确性之间的平衡。