在大学毕业 30 周年的同学聚会上,作者观察到同龄人对人工智能将如何影响未来普遍感到焦虑。然而,在聚会期间,他和朋友们回忆起了一款名为“BattleTris”的游戏——这是他们在 90 年代中期作为学生时编写的一款竞技类俄罗斯方块游戏。 对于这群朋友而言,BattleTris 具有深远的个人意义,它代表了人类情感联结与创造性乐趣的怀旧巅峰,甚至还是作者结识他妻子的背景契机。几十年来,这款游戏一直处于搁置状态,因为在技术上太难复刻。然而,在 Claude 的帮助下,作者和他的同事们成功地修复了程序漏洞,并将这些旧代码在聚会前移植到了现代系统中。 这次经历引发了深刻的思考:尽管许多人担心人工智能会剥夺我们的人性,但这个合作项目证明了大型语言模型是强大的工具,能够促进“人类时刻”的产生。通过利用人工智能修复他们共同过去的一部分,作者发现技术可以作为连接和创造力的桥梁,证明了未来依然可以为驱动我们最初去创造的那份人类快乐留有一席之地。
```Hacker News
最新 | 过往 | 评论 | 提问 | 展示 | 招聘 | 提交
登录
A Portentous Reunion (dtrace.org)
5 分,发布者:cafkafk,1 小时前 | 隐藏 | 过往 | 收藏 | 1 条评论
帮助
bcantrill 22 分钟前 [–]
我知道我已经就此写过一篇(很长的!)文章,所以不想在这里过多展开——但这次经历确实非常奇妙:一边与(可以理解的!)为年轻人感到焦虑的父母们讨论非人性化的危险,同时又在 LLM(大语言模型)的辅助下体验着这种强烈的人性交流。最重要的是,它印证了我们许多人所相信的一点:当下未来充满了不确定性,且必将包含许多惊喜!
回复
指南 | 常见问题 | 列表 | API | 安全 | 法律 | 加入 YC | 联系
搜索:
```
作者叙述了一次在一家心理健康初创公司面试创始工程师职位的痛苦经历。虽然“文化契合度”对早期阶段的公司至关重要,但这次面试偏离了常规,演变成了一场极具侵入性、长达 90 分钟的“创伤诱导”会议。面试官以提供安全空间为幌子,强迫候选人披露包括失败感情和家庭问题在内的深层个人隐私,而面试官自己却毫无分享。 这次面试过程让候选人感到精疲力竭且毫无保留。在次日收到一封简短且冷漠的拒信后,候选人感到极度的羞愧与愤怒,意识到自己的个人脆弱被当作评判标准,并被判定为“不合格”。 作者认为,尽管评估候选人的人格很重要,但这种侵入式的形式既不道德也无效。这篇文章为创始人和招聘经理敲响了警钟:在优先考虑文化契合度的同时,切勿将候选人的个人经历作为武器。真正的职业契合度可以通过尊重个人边界的方式来评估,而不是为了招聘评估而利用候选人的隐私。
这条 Hacker News 帖子讨论了一位用户糟糕的面试经历。虽然原帖未完整提供,但评论区达成了一致共识:面试官的行为极其不妥,原作者很可能“躲过一劫”。
参与者就职业边界分享了不同观点。一位用户指出,虽然他们有时会询问候选人的个人爱好以评估其远程办公的心理适应能力,但在评估健康状况和窥探隐私之间存在一条微妙的界限。另一位评论者则提出,该公司可能根本不是正规企业,而是有人在恶意行事。总体而言,社区支持设定明确的边界,有用户建议,如果遇到不专业的面试,直接离开是节省双方时间的合理做法。
 乔治亚电力公司(Georgia Power)因在考维塔县(Coweta)和费耶特县(Fayette)利用征收权强行征用数十户民宅及数百个地役权,正面临强烈的抵制。该公司正在加速推进一条全长35英里、500千伏的输电线路项目,即“Wansley项目”,旨在为大型人工智能数据中心供电。
在安斯利·布朗(Ansley Brown)等活动人士的带领下,当地居民正针对过低的收购报价及家庭被迫流离失所的问题进行抗议。这场冲突凸显了一个日益增长的全国性趋势:随着大型科技公司对电力的需求激增,公用事业公司正以牺牲当地社区为代价,优先考虑数据中心的基础设施建设。批评者认为,这些项目将建设成本社会化(往往导致居民用电价格上涨),而利润却被私人企业占有。
乔治亚州的这一情况,是超大规模科技增长与当地基础设施承载力之间更广泛博弈的一个缩影。随着数据中心对快速扩张的需求,为铺设输电线路而激进使用征收权的行为引发了抗议浪潮,这标志着大型科技公司的能源胃口与房产业主权利之间的对抗正在加剧。
乔治亚电力公司(Georgia Power)因在考维塔县(Coweta)和费耶特县(Fayette)利用征收权强行征用数十户民宅及数百个地役权,正面临强烈的抵制。该公司正在加速推进一条全长35英里、500千伏的输电线路项目,即“Wansley项目”,旨在为大型人工智能数据中心供电。
在安斯利·布朗(Ansley Brown)等活动人士的带领下,当地居民正针对过低的收购报价及家庭被迫流离失所的问题进行抗议。这场冲突凸显了一个日益增长的全国性趋势:随着大型科技公司对电力的需求激增,公用事业公司正以牺牲当地社区为代价,优先考虑数据中心的基础设施建设。批评者认为,这些项目将建设成本社会化(往往导致居民用电价格上涨),而利润却被私人企业占有。
乔治亚州的这一情况,是超大规模科技增长与当地基础设施承载力之间更广泛博弈的一个缩影。随着数据中心对快速扩张的需求,为铺设输电线路而激进使用征收权的行为引发了抗议浪潮,这标志着大型科技公司的能源胃口与房产业主权利之间的对抗正在加剧。
本文旨在评析 C 语言中数组的设计,特别是其容易令人困惑的“退化”为指针的特性。在 C 语言中,数组类型与指针类型本应泾渭分明,但在任何使用数组的表达式中(`sizeof` 或 `&` 运算除外),数组会立即转换为指向首元素的指针。这种机制掩盖了数组的大小,并导致了不一致性,尤其是在函数传参时,数组的大小信息会随之丢失。 作者认为,C 语言本应保持更严格的区分,将数组视为类似于按值传递的结构体。这将使数组的行为更符合直觉,并与其他数据类型保持一致。为了处理指针与数组之间的转换,作者建议采用类似于 GDB 中 `@` 运算符的语法(例如 `*ptr@n`)。这将允许程序员为指针指定长度,从而将其转换为数组。 尽管作者承认这种改变会引入“拷贝”开销,但认为它能为开发者提供更好的工具、更高的清晰度以及更强的控制力。归根结底,本文强调了“宽指针”(wide pointer)模式在 C 语言内存管理中已得到有效应用,并指出若语言设计能更审慎,C 语言的内存模型本可以变得更加可预测。
```Hacker News
最新 | 过往 | 评论 | 提问 | 展示 | 招聘 | 提交
登录
C 语言数组类型很怪 (anselmschueler.com)
6 分,由 signa11 在 1 小时前发布 | 隐藏 | 过往 | 收藏 | 1 条评论
帮助
uecker 53 分钟前 [–]
在实践中,[static n] 这种写法可以为你提供有用的警告和边界检查。
https://godbolt.org/z/PzcjW4zKK
虽然 (*array_ptr)[3] 这种写法需要一点时间来适应,但它非常符合逻辑。如果你有一个指向数组的指针,你先解引用它,然后再进行索引访问。同样,这对边界检查很有用:
https://godbolt.org/z/ao1so9KP7
回复
指南 | 常见问题 | 列表 | API | 安全 | 法律 | 申请加入 YC | 联系
搜索: ```
 托马斯·科尔比(Thomas Kolbe)认为,21世纪是西方保守派和自由意志主义运动的衰退期,并将其与欧盟及纽约的“官僚社会主义”同南美洲近期保守派与自由意志主义的复兴进行了对比。
科尔比指出,欧洲和美国正受到“奥威尔式”生态社会主义议程的影响。他以纽约市长佐兰·马姆达尼(Zohran Mamdani)为例,将其政策比作苏联式的计划经济,并视其为由大规模移民以及私有财产和个人自由等资产阶级支柱受到侵蚀所推动的激进左翼趋势的典型代表。他认为,这种“社会主义陷阱”是由人口结构变化和一个抑制增长并针对创业阶层的臃肿行政国家所维持的。
最终,科尔比将当前的政治气候视为一个正在衰落的全球主义“绿色指令体系”与文化复兴潜力之间的斗争。他建议,欧洲必须做出抉择:是拥有抵制这种日益严重的社会主义、并效仿哈维尔·米莱(Javier Milei)和安东尼奥·卡斯特(Antonio Kast)等领导人所展现出的市场导向及爱国主义成功经验的勇气,还是继续走在制度和社会瓦解的道路上。
托马斯·科尔比(Thomas Kolbe)认为,21世纪是西方保守派和自由意志主义运动的衰退期,并将其与欧盟及纽约的“官僚社会主义”同南美洲近期保守派与自由意志主义的复兴进行了对比。
科尔比指出,欧洲和美国正受到“奥威尔式”生态社会主义议程的影响。他以纽约市长佐兰·马姆达尼(Zohran Mamdani)为例,将其政策比作苏联式的计划经济,并视其为由大规模移民以及私有财产和个人自由等资产阶级支柱受到侵蚀所推动的激进左翼趋势的典型代表。他认为,这种“社会主义陷阱”是由人口结构变化和一个抑制增长并针对创业阶层的臃肿行政国家所维持的。
最终,科尔比将当前的政治气候视为一个正在衰落的全球主义“绿色指令体系”与文化复兴潜力之间的斗争。他建议,欧洲必须做出抉择:是拥有抵制这种日益严重的社会主义、并效仿哈维尔·米莱(Javier Milei)和安东尼奥·卡斯特(Antonio Kast)等领导人所展现出的市场导向及爱国主义成功经验的勇气,还是继续走在制度和社会瓦解的道路上。
👍 1 人点赞 👎 1 人点踩 😄 1 人大笑 🎉 1 人庆祝 😕 1 人困惑 ❤️ 1 人点心 🚀 1 人点火箭 👀 1 人查看 你目前无法执行该操作。
流行的实用程序 AltTab.app 已将其部分免费功能转为付费模式,并删除了旧版本的二进制文件。虽然标题暗示了争议,但 Hacker News 的评论者大多认为此举合理且有据可依。
开发者解释说,由于缺乏社区协助维护,该项目需要一种可持续的资助模式。用户仍然可以通过自行编译源代码来免费获取,或购买“Pro”版的永久许可证。
社区反应非常积极,许多用户称赞开发者避免了订阅制模式。此外,开发者还主动为无力承担费用的用户提供了免费许可证。总的来说,现有用户认为这一转变对于该软件所提供的实用功能来说是一项公平的权衡。
请启用 JavaScript 和 Cookie 以继续。
Medium 近期的一篇文章探讨了维基媒体基金会内部的劳资矛盾,指出该组织采取了大型科技公司“裁员与反工会”的策略。文章认为,维基百科作为服务于公共利益的机构,不应效仿那些将利润置于维持基础设施的员工之上的企业做法。
随后在 Hacker News 上引发的讨论呈现出明显的观点分歧。工会运动的支持者认为,员工应当得到保护以防止管理层越权,且激进的削减成本行为威胁到了平台的长期稳定性。相反,批评者对“大型科技公司”这一类比提出质疑,指出维基百科的运营环境与大型营利性企业不同。其他人则针对工会具体诉求的性质展开辩论,部分评论者认为诉求不合理,而另一些人则为其温和性进行辩护。总的来说,这场对话反映出人们对于硅谷文化——即大规模裁员与组织重组——正日益影响使命驱动型非营利组织的普遍焦虑。
 由于霍尔木兹海峡遭到封锁,伊拉克的石油产量已骤降至每日 139 万桶,达到 2003 年入侵以来的最低水平。由于伊拉克 90% 以上的预算依赖石油出口,此次停运引发了生存性的经济危机,且强制关闭油井可能导致南部油田遭受永久性破坏。
为绕过霍尔木兹海峡,巴格达正紧急努力恢复经由基尔库克-杰伊汉管道系统通往土耳其的北部出口路线。该战略旨在减少对库尔德斯坦地区政府(KRG)的依赖,并建立一条连接南部油田与地中海港口的南北输油走廊。
中国已成为此次基础设施改造的核心合作伙伴,利用 2019 年签署的“以石油换项目”协议获得了主要工程建设权。通过绕过传统招标程序,巴格达已聘请中国公司建设一条从巴士拉到哈迪塞、全长 700 公里的超级输油管道。此举显著增强了北京对伊拉克能源部门的影响力,并可能削弱西方在该地区的战略利益,因为伊拉克正试图通过中国支持的非传统物流途径来保障其财政未来。
由于霍尔木兹海峡遭到封锁,伊拉克的石油产量已骤降至每日 139 万桶,达到 2003 年入侵以来的最低水平。由于伊拉克 90% 以上的预算依赖石油出口,此次停运引发了生存性的经济危机,且强制关闭油井可能导致南部油田遭受永久性破坏。
为绕过霍尔木兹海峡,巴格达正紧急努力恢复经由基尔库克-杰伊汉管道系统通往土耳其的北部出口路线。该战略旨在减少对库尔德斯坦地区政府(KRG)的依赖,并建立一条连接南部油田与地中海港口的南北输油走廊。
中国已成为此次基础设施改造的核心合作伙伴,利用 2019 年签署的“以石油换项目”协议获得了主要工程建设权。通过绕过传统招标程序,巴格达已聘请中国公司建设一条从巴士拉到哈迪塞、全长 700 公里的超级输油管道。此举显著增强了北京对伊拉克能源部门的影响力,并可能削弱西方在该地区的战略利益,因为伊拉克正试图通过中国支持的非传统物流途径来保障其财政未来。
 Twitch 主播哈桑·皮克(Hasan Piker)在最近的一次直播中可能无意间泄露了一个运营安全网络。在讨论美国财政部对其古巴人道主义之行的调查时,皮克指出科技金融家内维尔·罗伊·辛格姆(Neville Roy Singham)是包括“粉红代码”(CodePink)和“社会主义与解放党”(Party for Socialism and Liberation)在内的多个美国激进非政府组织的主要资金来源。
据报道,辛格姆现居中国。《纽约时报》此前曾将其与亲中国共产党的宣传网络联系起来。通过梳理辛格姆与这些国内激进组织之间的财务联系,皮克似乎证实了联邦政府长期以来的担忧,即这些组织可能是外国资助的、旨在破坏美国国内稳定的幌子。
尽管皮克将政府对其活动的关注描述为对言论自由的攻击,但调查人员是从国家安全的角度看待此事的。此次披露意义重大,因为它证实了财政部的审查范围已不仅限于个人活动人士,还扩大到了在美国境内运作的、可能受外国影响的更广泛的非营利组织网络。
Twitch 主播哈桑·皮克(Hasan Piker)在最近的一次直播中可能无意间泄露了一个运营安全网络。在讨论美国财政部对其古巴人道主义之行的调查时,皮克指出科技金融家内维尔·罗伊·辛格姆(Neville Roy Singham)是包括“粉红代码”(CodePink)和“社会主义与解放党”(Party for Socialism and Liberation)在内的多个美国激进非政府组织的主要资金来源。
据报道,辛格姆现居中国。《纽约时报》此前曾将其与亲中国共产党的宣传网络联系起来。通过梳理辛格姆与这些国内激进组织之间的财务联系,皮克似乎证实了联邦政府长期以来的担忧,即这些组织可能是外国资助的、旨在破坏美国国内稳定的幌子。
尽管皮克将政府对其活动的关注描述为对言论自由的攻击,但调查人员是从国家安全的角度看待此事的。此次披露意义重大,因为它证实了财政部的审查范围已不仅限于个人活动人士,还扩大到了在美国境内运作的、可能受外国影响的更广泛的非营利组织网络。
Stack Overflow 的论坛虽已死,但这家公司依然活着。 Stack Overflow’s forum is dead but the company’s still kicking
2 小时前
Stack Overflow 曾是开发者获取知识的权威中心,如今正面临公众论坛参与度严重下滑的困境,其流量正被 ChatGPT 和 Copilot 等生成式 AI 工具所蚕食。月度提问量已骤降至 2008 年的水平,引发了外界对于该网站正面临“被大语言模型(LLM)取代”的担忧。 然而,尽管公众论坛的影响力在减弱,该公司在财务上依然稳健。通过摆脱对广告的依赖,Stack Overflow 的年收入已翻倍至 1.15 亿美元。目前,它正通过向 AI 开发商授权数据,以及销售企业级生成式 AI 解决方案“Stack Internal”(目前有 2.5 万家企业使用)来挖掘其海量人工精选存档的价值。 首席执行官 Prashanth Chandrasekar 认为,对于大语言模型难以解决的复杂、微妙的技术问题,该网站依然不可或缺。通过将历史存储库转型为高价值数据资源,Stack Overflow 已成功从一个公共问答论坛转型为 AI 时代以 B2B 为核心的关键基础设施提供商。该公司成为了老牌内容平台如何通过将其专业知识商品化,从而在威胁其原有模式的技术浪潮中生存甚至蓬勃发展的典范。
近期 Hacker News 上的讨论凸显了一种共识:Stack Overflow 正处于衰落的终局,而这不仅源于大语言模型(LLM)的兴起,更归因于长期以来的文化转变。
尽管许多用户认可该网站的历史价值,但他们认为其最终的崩塌是咎由自取。多年来,该平台曾经追求质量的初衷演变成了一种“严苛”的审核机制。用户经常反映,那种吹毛求疵的“把关”行为、过度使用“因重复而关闭”的裁定,以及对新手问题充满敌意、阻碍社区参与的环境,令他们倍感挫折。
人工智能的出现成为了最终的催化剂,它提供了即时且不带偏见的答案,使得该网站那种对抗性的问答模式显得过时。批评者指出,虽然大语言模型偶尔会产生幻觉,但对开发者而言,它们提供了阻力最小的路径。
更深层的担忧在于技术知识“公共广场”的丧失。随着社区驱动的验证机制逐渐消失,整个生态系统面临着失去细微差别、多元视角以及同行评审解决方案的风险——而这些曾是软件开发集体智慧的定义所在。许多评论者现在认为,该平台唯一存续的途径是转型为类似维基百科的非营利性、社区维护模式,而非继续作为营利性实体存在。
 1983年法兰克福车展上亮相的Steinwinter Supercargo,是重型卡车行业一次雄心勃勃且激进的革命性尝试。这款由德国工程师曼弗雷德·斯坦温特(Manfred Steinwinter)设计的超低底盘半挂卡车,旨在通过消除牵引车与挂车之间产生风阻的间隙,来最大限度地提高货运能力和燃油效率。Supercargo配备了强劲的梅赛德斯柴油发动机,采用可搭载集装箱或客车车身的模块化设计,其驾驶舱更类似于豪华跑车,在当时堪称超越时代的杰作。
然而,该项目最终以失败告终。这款卡车存在严重的机械可靠性问题、操控性能差以及驾驶员视野受限等缺陷。由于缺乏梅赛德斯等大型制造商的支持,资金链断裂,这款“未来卡车”最终未能投入量产。除了曾在电视剧《The Highwayman》和《Power Rangers Time Force》中作为影视道具短暂出现外,Supercargo便逐渐淡出了人们的视野。尽管现代物流行业仍在努力克服Supercargo当年试图解决的设计局限,但它最终只留下了“引人入胜却不切实际的汽车怪胎”这一名声。
1983年法兰克福车展上亮相的Steinwinter Supercargo,是重型卡车行业一次雄心勃勃且激进的革命性尝试。这款由德国工程师曼弗雷德·斯坦温特(Manfred Steinwinter)设计的超低底盘半挂卡车,旨在通过消除牵引车与挂车之间产生风阻的间隙,来最大限度地提高货运能力和燃油效率。Supercargo配备了强劲的梅赛德斯柴油发动机,采用可搭载集装箱或客车车身的模块化设计,其驾驶舱更类似于豪华跑车,在当时堪称超越时代的杰作。
然而,该项目最终以失败告终。这款卡车存在严重的机械可靠性问题、操控性能差以及驾驶员视野受限等缺陷。由于缺乏梅赛德斯等大型制造商的支持,资金链断裂,这款“未来卡车”最终未能投入量产。除了曾在电视剧《The Highwayman》和《Power Rangers Time Force》中作为影视道具短暂出现外,Supercargo便逐渐淡出了人们的视野。尽管现代物流行业仍在努力克服Supercargo当年试图解决的设计局限,但它最终只留下了“引人入胜却不切实际的汽车怪胎”这一名声。
```Hacker News最新 | 过往 | 评论 | 提问 | 展示 | 招聘 | 提交登录Steinwinter Supercargo (thedrive.com)12 分,由 itronitron 发布于 3 小时前 | 隐藏 | 过往 | 收藏 | 讨论 帮助
指南 | 常见问题 | 列表 | API | 安全 | 法律 | 加入 YC | 联系
搜索: ```
 路透社近期的一篇报道称五角大楼与 SpaceX 之间关系紧张,并将常规的合同谈判解读为埃隆·马斯克施加不当影响的证据。文章将美军无人机所用星链终端的价格上涨形容为利用军事依赖进行的“价格欺诈”。
然而,SpaceX 和五角大楼均对此予以驳斥,澄清称该争议属于合同合规性问题,而非财务剥削。SpaceX 长期以来坚持一项明确政策:商用星链不得用于军事武器系统。此次问题源于有承包商违规将民用终端用于无人机,而非使用专为国防应用设计的安全产品“星盾”(Starshield)。
官方表示,这并非价格冲突,而是为了确保卫星技术被正当使用而必须执行的服务条款。双方均强调通过“星盾”计划保持着持续且富有成效的合作关系,这与该报道中关于双方矛盾与博弈的描述相悖。
路透社近期的一篇报道称五角大楼与 SpaceX 之间关系紧张,并将常规的合同谈判解读为埃隆·马斯克施加不当影响的证据。文章将美军无人机所用星链终端的价格上涨形容为利用军事依赖进行的“价格欺诈”。
然而,SpaceX 和五角大楼均对此予以驳斥,澄清称该争议属于合同合规性问题,而非财务剥削。SpaceX 长期以来坚持一项明确政策:商用星链不得用于军事武器系统。此次问题源于有承包商违规将民用终端用于无人机,而非使用专为国防应用设计的安全产品“星盾”(Starshield)。
官方表示,这并非价格冲突,而是为了确保卫星技术被正当使用而必须执行的服务条款。双方均强调通过“星盾”计划保持着持续且富有成效的合作关系,这与该报道中关于双方矛盾与博弈的描述相悖。
 得益于名为“OmniDrive”的新型专用固件,复古游戏保存工作变得容易了许多。该固件允许特定的蓝光光驱读取来自 GameCube、Wii、初代 Xbox、Xbox 360 和 Dreamcast 等游戏主机的专用游戏光盘。
此前,从这些游戏机中提取数据需要对硬件本身进行改装。有了 OmniDrive,用户可以为兼容的光驱(特别是那些搭载 MediaTek MT1959 芯片组的华硕、LG、Buffalo 和 Verbatim 等品牌光驱)刷入该固件,从而读取这些光盘,并使用 Media Preservation Frontend 等工具将其转换为 ISO 文件。虽然从技术上讲,该方法也可以读取现代加密光盘(PS3/4/5 和 Xbox One/Series),但目前它主要作为简化复古游戏镜像提取以供模拟和保存的一项重大突破。
提醒用户严格遵循官方兼容性列表;将固件刷入不支持的驱动器很可能会导致设备“变砖”。这一进展标志着重大转变,使备份经典游戏收藏的过程变得几乎与翻录标准 DVD 一样简单直接。
得益于名为“OmniDrive”的新型专用固件,复古游戏保存工作变得容易了许多。该固件允许特定的蓝光光驱读取来自 GameCube、Wii、初代 Xbox、Xbox 360 和 Dreamcast 等游戏主机的专用游戏光盘。
此前,从这些游戏机中提取数据需要对硬件本身进行改装。有了 OmniDrive,用户可以为兼容的光驱(特别是那些搭载 MediaTek MT1959 芯片组的华硕、LG、Buffalo 和 Verbatim 等品牌光驱)刷入该固件,从而读取这些光盘,并使用 Media Preservation Frontend 等工具将其转换为 ISO 文件。虽然从技术上讲,该方法也可以读取现代加密光盘(PS3/4/5 和 Xbox One/Series),但目前它主要作为简化复古游戏镜像提取以供模拟和保存的一项重大突破。
提醒用户严格遵循官方兼容性列表;将固件刷入不支持的驱动器很可能会导致设备“变砖”。这一进展标志着重大转变,使备份经典游戏收藏的过程变得几乎与翻录标准 DVD 一样简单直接。
```Hacker News新消息 | 过往 | 评论 | 提问 | 展示 | 招聘 | 提交登录现代蓝光光驱现在可以将 GameCube、Wii 和 Xbox 360 游戏提取到 PC (tomshardware.com)29 点,由 01-_- 发布于 1 小时前 | 隐藏 | 过往 | 收藏 | 2 条评论 帮助
piperswe 38 分钟前 | 下一条 [–]
我假设这个固件也具备 MakeMKV 所需的 LibreDrive 固件功能?回复nom 1 小时前 | 上一条 [–]
长话短说:https://github.com/RibShark/OmniDrive回复
指南 | 常见问题 | 列表 | API | 安全 | 法律 | 加入 YC | 联系
搜索: ```
请启用 JavaScript 和 Cookie 以继续。
抱歉。
 美国枪主协会(GOA)的约翰·维莱科(John Velleco)认为,宪法第二修正案的安全很大程度上依赖于第四修正案对防止无理搜查和扣押的保护。GOA尤其关注“敲门调查”(knock and talk)这一执法策略,他们主张执法部门正越来越多地滥用该策略,以进行未经搜查令的入户调查。
维莱科以北卡罗来纳州的《州诉里尔案》(State v. Reel)为例,指出警察绕过法律准则强行进入民宅。他警告说,这种越权行为对枪主构成了威胁,特别是在关于没收枪支的政治言论日益激进的背景下。
为了遏制这些滥权行为,GOA向美国最高法院提交了一份法庭之友陈述书,提出了一条“明确界限”原则:警察进行“敲门调查”的法律权限不应超过普通公民(如推销饼干的女童军)。根据这一拟议标准,警察将被禁止进入后院、窥视窗户或使用武力。GOA坚持认为,为执法部门设定明确、狭窄的界限,对于保护宪法赋予的自由,以及防止政府将“敲门调查”作为解除守法公民武装的借口至关重要。
美国枪主协会(GOA)的约翰·维莱科(John Velleco)认为,宪法第二修正案的安全很大程度上依赖于第四修正案对防止无理搜查和扣押的保护。GOA尤其关注“敲门调查”(knock and talk)这一执法策略,他们主张执法部门正越来越多地滥用该策略,以进行未经搜查令的入户调查。
维莱科以北卡罗来纳州的《州诉里尔案》(State v. Reel)为例,指出警察绕过法律准则强行进入民宅。他警告说,这种越权行为对枪主构成了威胁,特别是在关于没收枪支的政治言论日益激进的背景下。
为了遏制这些滥权行为,GOA向美国最高法院提交了一份法庭之友陈述书,提出了一条“明确界限”原则:警察进行“敲门调查”的法律权限不应超过普通公民(如推销饼干的女童军)。根据这一拟议标准,警察将被禁止进入后院、窥视窗户或使用武力。GOA坚持认为,为执法部门设定明确、狭窄的界限,对于保护宪法赋予的自由,以及防止政府将“敲门调查”作为解除守法公民武装的借口至关重要。
 作者强调了 **VillageSQL** 的可扩展性。这是一个 MySQL 分支,它引入了以往仅在 Neo4j 等数据库中才有的强大底层插件功能。通过开放对 MySQL 内部机制的访问,VillageSQL 允许开发者构建自定义数据类型和函数,而无需受限于传统 SQL 环境。
作者分享了他们通过“氛围编码”(借助 AI 辅助)为 MySQL 构建 **Roaring Bitmap** 扩展的经验。尽管过程中遇到了一些小障碍,如管理动态数据结构大小和处理特定的内存缓冲区需求,但整体开发效率极高。作者指出,其一大优势是无需重启服务器即可动态安装和更新扩展,这相比其他平台是显著的工作流改进。
随着即将推出的云支持(预计将允许用户创建扩展),VillageSQL 为开发者提供了直接在 MySQL 中实现高级查询计划和自定义数据结构的自由。作者建议参考 DuckDB 的生态系统以获取灵感,并指出在 AI 辅助编码的加持下,创建复杂的数据库扩展现在比以往任何时候都更加容易。
作者强调了 **VillageSQL** 的可扩展性。这是一个 MySQL 分支,它引入了以往仅在 Neo4j 等数据库中才有的强大底层插件功能。通过开放对 MySQL 内部机制的访问,VillageSQL 允许开发者构建自定义数据类型和函数,而无需受限于传统 SQL 环境。
作者分享了他们通过“氛围编码”(借助 AI 辅助)为 MySQL 构建 **Roaring Bitmap** 扩展的经验。尽管过程中遇到了一些小障碍,如管理动态数据结构大小和处理特定的内存缓冲区需求,但整体开发效率极高。作者指出,其一大优势是无需重启服务器即可动态安装和更新扩展,这相比其他平台是显著的工作流改进。
随着即将推出的云支持(预计将允许用户创建扩展),VillageSQL 为开发者提供了直接在 MySQL 中实现高级查询计划和自定义数据结构的自由。作者建议参考 DuckDB 的生态系统以获取灵感,并指出在 AI 辅助编码的加持下,创建复杂的数据库扩展现在比以往任何时候都更加容易。
Hacker News
最新 | 过往 | 评论 | 提问 | 展示 | 招聘 | 提交
登录
使用 VillageSQL 扩展 MySQL (maxdemarzi.com)
8 分,由 maxdemarzi 发布于 1 小时前 | 隐藏 | 过往 | 收藏 | 1 条评论
帮助
deesix 14 分钟前 [–]
我是创始人。感谢花时间了解 VillageSQL。期待所有的反馈。
回复
指南 | 常见问题 | 列表 | API | 安全 | 法律 | 申请 YC | 联系
搜索:
 俄罗斯向华盛顿发出严厉警告,建议美国撤离驻基辅的外交人员和公民。外交部长谢尔盖·拉夫罗夫正式通知国务卿马可·鲁比奥,俄罗斯打算对乌克兰首都发动“系统性打击”,目标明确指向军工复合体、无人机生产设施以及“决策中心”。
莫斯科将此次局势升级描述为对近期乌克兰无人机袭击俄罗斯控制下的卢甘斯克一处大学宿舍的直接报复,并称此举是“压死骆驼的最后一根稻草”。克里姆林宫在公开声明中敦促所有外国人员和国际组织立即撤离基辅,并警告称,对于军事或行政基础设施附近的附带损害,俄方将不承担责任。
这种向美国发出的直白预先通知,在当前的冲突中属于罕见且重大的外交进展。尽管俄罗斯强调其意图是打击军事资产,但这一警告实际上已使各国驻外使馆和基辅居民处于高度戒备状态,以应对即将来临且可能升级的空中行动。截至目前,白宫尚未对即将发生的袭击发表官方谴责。
俄罗斯向华盛顿发出严厉警告,建议美国撤离驻基辅的外交人员和公民。外交部长谢尔盖·拉夫罗夫正式通知国务卿马可·鲁比奥,俄罗斯打算对乌克兰首都发动“系统性打击”,目标明确指向军工复合体、无人机生产设施以及“决策中心”。
莫斯科将此次局势升级描述为对近期乌克兰无人机袭击俄罗斯控制下的卢甘斯克一处大学宿舍的直接报复,并称此举是“压死骆驼的最后一根稻草”。克里姆林宫在公开声明中敦促所有外国人员和国际组织立即撤离基辅,并警告称,对于军事或行政基础设施附近的附带损害,俄方将不承担责任。
这种向美国发出的直白预先通知,在当前的冲突中属于罕见且重大的外交进展。尽管俄罗斯强调其意图是打击军事资产,但这一警告实际上已使各国驻外使馆和基辅居民处于高度戒备状态,以应对即将来临且可能升级的空中行动。截至目前,白宫尚未对即将发生的袭击发表官方谴责。
Stack Overflow 的论坛已经死了,但这家公司依然活着。 Stack Overflow’s forum is dead but the company’s still kicking
3 小时前
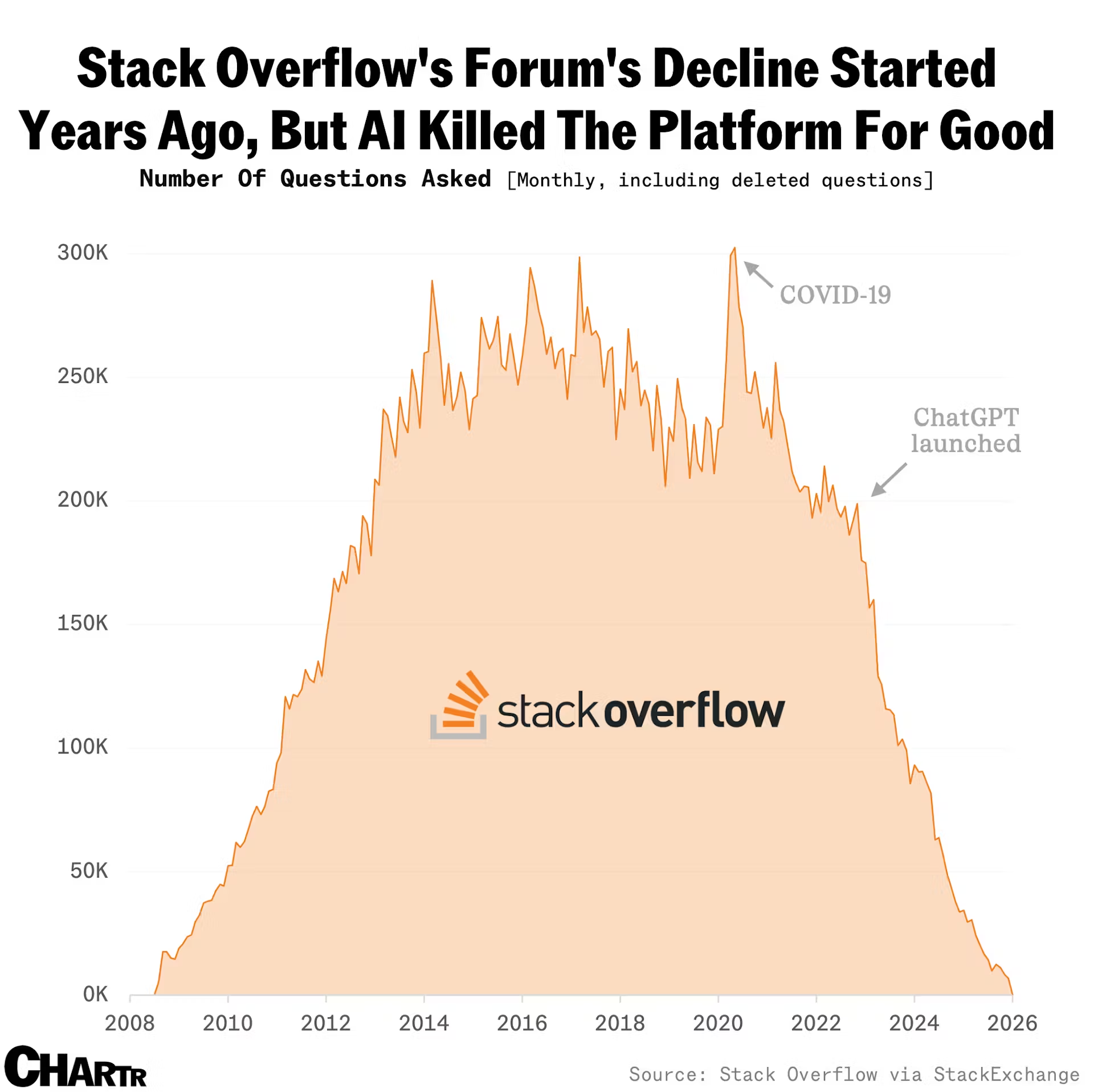 本文探讨了 Stack Overflow 论坛活跃度的下滑,并指出尽管该平台几年前就开始失去动力,但人工智能的兴起显著加速了这一趋势。
作者利用 Stack Exchange 数据资源管理器(SEDE)生成纵向数据,并通过复杂的 SQL 查询来追踪问题、回答和评论的趋势。研究结果显示,自 ChatGPT 发布以来,各项互动指标均出现明显下降。值得注意的是,人均回答数和人均评论数均大幅减少,这表明社区整体参与度下降,进而影响了内容质量。
本文同时也作为一份技术指南,记录了作者掌握 SQL 以提取这些见解的迭代过程。通过成功关联来自不同表(如帖子和评论)的数据,作者证明了该平台活力的减弱。作者担心,随着社区互动的减少,论坛的长期实用性可能会受到威胁,尤其是当技术障碍日益阻碍这些具有历史意义的数据存档时。总的来说,本文既是对该平台健康状况的数据驱动式批判,也是一份利用 SEDE 进行社区分析的实用指南。
本文探讨了 Stack Overflow 论坛活跃度的下滑,并指出尽管该平台几年前就开始失去动力,但人工智能的兴起显著加速了这一趋势。
作者利用 Stack Exchange 数据资源管理器(SEDE)生成纵向数据,并通过复杂的 SQL 查询来追踪问题、回答和评论的趋势。研究结果显示,自 ChatGPT 发布以来,各项互动指标均出现明显下降。值得注意的是,人均回答数和人均评论数均大幅减少,这表明社区整体参与度下降,进而影响了内容质量。
本文同时也作为一份技术指南,记录了作者掌握 SQL 以提取这些见解的迭代过程。通过成功关联来自不同表(如帖子和评论)的数据,作者证明了该平台活力的减弱。作者担心,随着社区互动的减少,论坛的长期实用性可能会受到威胁,尤其是当技术障碍日益阻碍这些具有历史意义的数据存档时。总的来说,本文既是对该平台健康状况的数据驱动式批判,也是一份利用 SEDE 进行社区分析的实用指南。
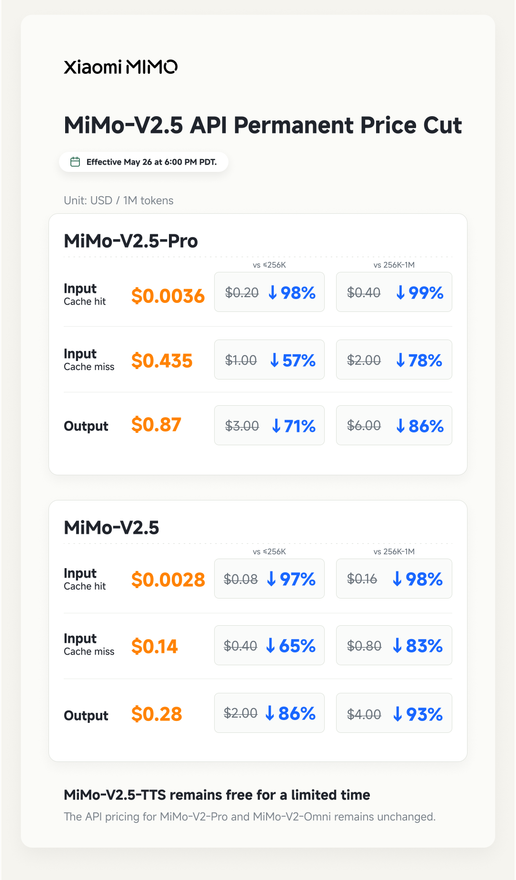 MiMo 将于北京时间 2026 年 5 月 27 日 0:00 起,对定价和计费系统进行全面升级。得益于 SGLang HiCache 和增强型专家并行(Expert Parallelism)等重大技术优化,MiMo 的推理架构效率显著提升,从而实现了大幅成本削减。
**主要更新:**
* **API 价格永久下调:** MiMo-V2.5 API 价格最高下调 99%,且不限输入长度,采用统一费率。
* **Token 套餐优化:** 计费方式更加清晰,在不增加费用的前提下,使用配额提升了 5 至 8 倍。
* **配额重置:** 所有现有 Token 套餐用户的配额将根据新的计费规则进行全面重置。
* **激励计划:** “千万亿 Token 创造者激励计划”已圆满结束,全部奖励已发放完毕。
* **后续福利:** 历史付费用户若套餐已过期,敬请关注下周即将公布的惊喜礼遇。
此次调整体现了 MiMo 的承诺,旨在让顶尖 AI 模型更加普及且负担得起,从而为全球开发者构建更稳健、更具扩展性的 AI 基础设施。
MiMo 将于北京时间 2026 年 5 月 27 日 0:00 起,对定价和计费系统进行全面升级。得益于 SGLang HiCache 和增强型专家并行(Expert Parallelism)等重大技术优化,MiMo 的推理架构效率显著提升,从而实现了大幅成本削减。
**主要更新:**
* **API 价格永久下调:** MiMo-V2.5 API 价格最高下调 99%,且不限输入长度,采用统一费率。
* **Token 套餐优化:** 计费方式更加清晰,在不增加费用的前提下,使用配额提升了 5 至 8 倍。
* **配额重置:** 所有现有 Token 套餐用户的配额将根据新的计费规则进行全面重置。
* **激励计划:** “千万亿 Token 创造者激励计划”已圆满结束,全部奖励已发放完毕。
* **后续福利:** 历史付费用户若套餐已过期,敬请关注下周即将公布的惊喜礼遇。
此次调整体现了 MiMo 的承诺,旨在让顶尖 AI 模型更加普及且负担得起,从而为全球开发者构建更稳健、更具扩展性的 AI 基础设施。
小米 MiMo-v2.5 API 宣布永久降价,最高降幅达 99%,引发了 Hacker News 上的热烈讨论。用户将这种激进的定价策略与 DeepSeek 近期的做法进行了对比,并指出这些中国模型性能卓越,且与美国同类产品相比具有极高的性价比。
评论者讨论了这些降价措施的可持续性及其背后的驱动因素。观点包括:政府补贴旨在推动人工智能的普及(类似于中国在电动汽车领域的做法),以及运营效率的提升,例如使用国产 GPU 硬件(如华为昇腾)、低廉的电力成本和优化的模型架构。
尽管一些用户对使用中国托管的模型表示隐私担忧,但另一些人指出,由于这些模型是开源权重的,可以通过自行部署来降低安全风险。最终,舆论一致认为,这种“价格战”正对西方人工智能公司施加巨大压力,相比之下,这些公司目前的订阅模式显得愈发昂贵。许多人希望这一趋势能实现人工智能的平民化,防止它成为少数支付高额订阅费者专属的工具。
这份摘要概述了一位小说家兼软件开发者追求高质量、自动化图书排版工作流的历程。最初,作者依赖 Microsoft Word 和 Adobe InDesign,但发现这一过程效率低下、封闭且繁琐。 为了寻求专业级的排版效果和更好的版本控制,作者转向了更具技术性的开源方案。他们将“单一事实来源”从 Word 文档迁移到了语义丰富的 LibreOffice (ODT) 文档中。通过运用自定义 Python 脚本,他们现在可以解析这些 ODT 文件,从而生成符合 Standard Ebooks 标准的 EPUB,以及通过 LaTeX 生成高质量的专业级 PDF。 这一转变将不透明的二进制格式替换为使用 Git 进行追踪的纯文本文件,不仅便于修订,还实现了卓越的排版控制。虽然作者承认这种严谨且代码密集的过程并不适合所有人,但它为作者提供了一套可持续、自动化的工作流,满足了其对叙事和技术工艺的双重标准。最后,作者强调,尽管排版对于专业的阅读体验至关重要,但核心目标始终是传递引人入胜的好故事。
这篇 Hacker News 的讨论围绕 Dustin Speckhals 的一篇博文展开,他描述了自己如何构建了一套基于 Git 的自动化书籍生产流程,以摆脱管理 Word 和 InDesign 文件所带来的困扰。
评论者们提出了多种视角:
* **“业余与专业”之争:** 有人认为作者遇到的工作流问题可以通过 InDesign 的“置入”(Place)命令等现有功能解决。另一些人则指出,对于学术界和技术类作者来说,使用 Git 和基于代码的排版(如 LaTeX)撰写小说早已是行业标准。
* **工具缺失:** 读者们普遍认为,独立作者目前所依赖的专有、昂贵且繁琐的出版流程存在缺陷。呼吁出现更多能够输出专业 PDF/X 标准的用户友好型开源工具。
* **技术细节:** 讨论深入到了版本控制中“硬换行与软换行”的争论,并探讨了为何某些印刷书籍会出现文字像素化的问题(通常是因为为了减轻视觉疲劳而使用了“非纯黑”配色,这可能与标准印刷工艺产生冲突)。
总体而言,社区认为作者的项目是一个积极的尝试,尽管许多人指出,对学术界和开发者社区来说,这类工作流早已“见怪不怪”。
Co-authored-by: ur mom 我不明白为什么人们会乐此不疲地在自己的开源项目中加入这些公司的广告,而这些公司不仅一分钱不给他们(反而还在订阅费上反过来剥削他们)。“由 blabot 辅助”、“co-authored-by: slopgpt”、“从我的臭屁手机发送”,这到底是为什么?这他妈就是广告。我敢打赌你们平时都用广告拦截器,结果却在自己的提交信息里加广告。别这样了。如果需要,在合并请求(merge request)里披露你们使用的“AI”工具就行了,但别把这些放进提交信息里,那是记录技术细节的地方,不是打广告的地方。或者,哪怕写个“由 LLM 生成”也行,但别给这些公司提供免费的广告位。再或者……干脆别用这些工具,这其实挺容易的。任何会在我的提交、邮件或任何消息中植入广告的工具,都是垃圾工具。去他妈的广告。 另外,在有人因为某些事跳脚之前,先声明一下我的“AI”立场:https://akselmo.dev/posts/why-i-will-likely-never-use-ai-programming-tools/
最近 Hacker News 上由“停止在提交中投放广告”一文引发的讨论,凸显了关于 git 提交信息中 AI 生成页脚的争议日益激烈。
各方观点针锋相对。批评者认为,由工具强制生成的页脚(如 Cursor 或 Claude 产生的那些)本质上是干扰性的广告,而非有效的披露。许多人将其比作电子邮件中“从我的 iPhone 发送”的签名——既是一种营销,也是代码来源的标志。一些开发者不喜欢这种杂乱感,如果确需披露,他们更倾向于使用标准的 `Co-authored-by` 惯例。
相反,支持者认为这些标注提供了必要的透明度,便于审查者识别潜在的“低质量”代码。另一些人则认为,只要代码功能正常,使用何种工具无关紧要。一种更具批判性的理论认为,这些页脚为 AI 公司提供了战略性用途:通过抓取公共代码库,服务商可以获取经人工编辑的代码,从而通过人类反馈强化学习(RLHF)来改进其模型。
归根结底,这一共识反映了个人代码库自主权与保持 git 历史记录整洁的职业需求之间的矛盾。许多人认为,如果需要 AI 披露,这应该是一个可选设置,而非默认选项。
 美国航空(American Airlines)股价上涨近6%,此前该公司宣布了一项重大的机队现代化计划,其中包括在2027年初之前,为500架窄体飞机配备SpaceX的星链(Starlink)卫星互联网。此举旨在取代缓慢的机载网络,提供能够在3万6千英尺高空支持流媒体、游戏和专业工作流程的高速、可靠的宽带服务。
通过采用星链的低地球轨道技术(每根天线最高可提供1 Gbps的网速),美国航空加入了联合航空、西南航空和阿拉斯加航空等其他主要航空公司的行列,共同提升乘客体验。随着旅客在预订航班时越来越看重网络连接,航空公司将此视为一项关键的竞争优势。此外,正值市场对SpaceX首次公开募股(IPO)的预期日益高涨之际,此次合作也引发了市场的广泛关注。
美国航空(American Airlines)股价上涨近6%,此前该公司宣布了一项重大的机队现代化计划,其中包括在2027年初之前,为500架窄体飞机配备SpaceX的星链(Starlink)卫星互联网。此举旨在取代缓慢的机载网络,提供能够在3万6千英尺高空支持流媒体、游戏和专业工作流程的高速、可靠的宽带服务。
通过采用星链的低地球轨道技术(每根天线最高可提供1 Gbps的网速),美国航空加入了联合航空、西南航空和阿拉斯加航空等其他主要航空公司的行列,共同提升乘客体验。随着旅客在预订航班时越来越看重网络连接,航空公司将此视为一项关键的竞争优势。此外,正值市场对SpaceX首次公开募股(IPO)的预期日益高涨之际,此次合作也引发了市场的广泛关注。
 纽约市长佐兰·马姆达尼(Zohran Mamdani)发布了一项名为“街区逐一改善:新时代住房计划”的综合战略,旨在应对该市的住房危机。该计划包含激进措施,包括可能依法征用“疏于管理”业主的房产,并将其转交给非营利组织、社区土地信托或租户。批评者对此予以谴责,称其为“盗窃计划”和政府越权行为,认为这可能导致租赁市场动荡并惊动贷款机构。
与此同时,马姆达尼正在调整其竞选时提出的四年全市房租冻结承诺。面对运营成本上升带来的财务压力,他宣布了一项有限的豁免政策,允许特定受政府监管的房产所有者在单位空置时实施一次性租金上涨。此外,市政府还将启动一项500万美元的贷款计划,以协助房东处理逾期租金并防止驱逐事件发生。
尽管马姆达尼旨在平衡租户减负与房产业主的财务现实,但该计划引发了激烈的辩论。支持者强调新开发项目的必要性(目标是新建20万套住房),而反对者则警告称,他的干预政策威胁到了私有财产权,并可能加剧该市长期的住房挑战。
纽约市长佐兰·马姆达尼(Zohran Mamdani)发布了一项名为“街区逐一改善:新时代住房计划”的综合战略,旨在应对该市的住房危机。该计划包含激进措施,包括可能依法征用“疏于管理”业主的房产,并将其转交给非营利组织、社区土地信托或租户。批评者对此予以谴责,称其为“盗窃计划”和政府越权行为,认为这可能导致租赁市场动荡并惊动贷款机构。
与此同时,马姆达尼正在调整其竞选时提出的四年全市房租冻结承诺。面对运营成本上升带来的财务压力,他宣布了一项有限的豁免政策,允许特定受政府监管的房产所有者在单位空置时实施一次性租金上涨。此外,市政府还将启动一项500万美元的贷款计划,以协助房东处理逾期租金并防止驱逐事件发生。
尽管马姆达尼旨在平衡租户减负与房产业主的财务现实,但该计划引发了激烈的辩论。支持者强调新开发项目的必要性(目标是新建20万套住房),而反对者则警告称,他的干预政策威胁到了私有财产权,并可能加剧该市长期的住房挑战。
在执掌 Dropbox 19 年后,创始人德鲁·休斯顿(Drew Houston)即将卸任首席执行官一职。他将与现任产品负责人阿什拉夫·阿尔卡米(Ashraf Alkarmi)共同担任一段时间的联席首席执行官,随后过渡至执行董事长职位,而阿尔卡米将最终全面接管公司领导权。 休斯顿曾将 Dropbox 从一家 Y Combinator 孵化的初创企业打造为云存储领域的先驱,如今他留下的这家公司拥有超过 1800 万付费用户。然而,Dropbox 也面临着诸多挑战,包括营收增长停滞以及来自苹果、谷歌和微软等科技巨头的竞争加剧。尽管公司目前的市值仍低于 2014 年的私募估值,但它成功避免了其他软件即服务(SaaS)公司所经历的股价大幅下跌。 展望未来,该公司正押注于其人工智能驱动的“Dash”功能以保持市场竞争力。43 岁的休斯顿对阿尔卡米的领导能力表示信任,并计划在人工智能领域寻求新的创业机会。休斯顿表示:“现在是进行创造的最好时期。”他强调自己无意退休,将继续活跃在科技领域。
随着 Dropbox 首席执行官 Drew Houston 即将卸任的消息传出,Hacker News 社区对这家公司近 20 年的历程展开了一场既充满怀旧又饱含批判的回顾。
许多用户表达了对该服务的深切赞赏,指出它曾彻底改变了文件同步方式,并显著提升了工作效率。然而,讨论很快转向了公司目前的困境。批评者指出,Dropbox 遭到了谷歌、苹果和微软等科技巨头的挤压,这些巨头提供的捆绑式存储服务为普通用户提供了更廉价且“足够好”的替代方案。
讨论的很大一部分集中在“功能臃肿”和激进的追加销售策略上,这些做法疏远了长期使用该服务的技术用户。尽管一些人仍称赞 Dropbox 卓越的块级同步能力,但许多人出于对隐私、定价以及公司偏离核心实用性的担忧,已迁移到自托管方案或 Syncthing 等小众解决方案。
归根结底,这一讨论反映了科技行业的一种普遍情绪:既钦佩其作为一款改变世界的基础性产品,又对其演变成一家在商品化市场中难以证明其价值主张的老牌服务感到失望。
 在这篇评论中,迈克·麦克丹尼尔(Mike McDaniel)对当前的洛杉矶市长竞选进行了评述,并将非政治人物斯宾塞·普拉特(Spencer Pratt)的政纲与现任官员凯伦·巴斯(Karen Bass)和尼蒂亚·拉曼(Nithya Raman)进行了对比。麦克丹尼尔将普拉特描述为法律、秩序和财政责任的支持者,而将他的对手称为由权力欲望而非有效治理驱动的“共产主义者”。
文章引用了作家库尔特·施利希特(Kurt Schlichter)的观点,认为这座城市严重的衰落——表现为犯罪、无家可归和基础设施瘫痪——并非行政无能的体现,而是一种将控制置于繁荣之上的政治意识形态所带来的必然结果。作者认为,洛杉矶乃至整个加州已经深陷民主党左倾治理的泥潭,以至于无法实现自我修正。文章最终指出,由于选民在面对显而易见的失调时仍继续支持现状,该市的颓势不太可能从内部得到扭转,这为该地区的未来描绘了一幅黯淡的前景。
在这篇评论中,迈克·麦克丹尼尔(Mike McDaniel)对当前的洛杉矶市长竞选进行了评述,并将非政治人物斯宾塞·普拉特(Spencer Pratt)的政纲与现任官员凯伦·巴斯(Karen Bass)和尼蒂亚·拉曼(Nithya Raman)进行了对比。麦克丹尼尔将普拉特描述为法律、秩序和财政责任的支持者,而将他的对手称为由权力欲望而非有效治理驱动的“共产主义者”。
文章引用了作家库尔特·施利希特(Kurt Schlichter)的观点,认为这座城市严重的衰落——表现为犯罪、无家可归和基础设施瘫痪——并非行政无能的体现,而是一种将控制置于繁荣之上的政治意识形态所带来的必然结果。作者认为,洛杉矶乃至整个加州已经深陷民主党左倾治理的泥潭,以至于无法实现自我修正。文章最终指出,由于选民在面对显而易见的失调时仍继续支持现状,该市的颓势不太可能从内部得到扭转,这为该地区的未来描绘了一幅黯淡的前景。
 这份概览介绍了像素字体设计的四种现代演绎,探讨了当代设计师如何为实现功能性用途而重塑这种怀旧美学。
Andrew Gleeson 的 **Analog Mono** 修正了经典 90 年代录像机/高保真音响界面字体中存在的基线和字符间距缺陷。Kumiko Yoshida 的 **Coral Pixels** 则通过融入多彩的子像素风格边缘,将 90 年代的怀旧感作为一种刻意的视觉特征加以运用。与此同时,Joseph Fatula 的 **Two Slice** 将极简主义推向了极致,其字符高度仅为两个像素。
尽管这些字体唤起了复古情怀,但它们并非粗糙的点阵图,而是基于矢量的现代工具。Vercel 的 **Geist Pixel** 因其对生产级可靠性的关注而脱颖而出。许多装饰性像素字体在缩放时会失真或难以适配系统指标,而 Geist Pixel 则被设计为一套稳健的排版系统。通过优先处理精密的字距调整、元数据和垂直度量等“隐形”工作,Geist Pixel 弥合了怀旧质感与现代界面设计严苛要求之间的鸿沟。
这份概览介绍了像素字体设计的四种现代演绎,探讨了当代设计师如何为实现功能性用途而重塑这种怀旧美学。
Andrew Gleeson 的 **Analog Mono** 修正了经典 90 年代录像机/高保真音响界面字体中存在的基线和字符间距缺陷。Kumiko Yoshida 的 **Coral Pixels** 则通过融入多彩的子像素风格边缘,将 90 年代的怀旧感作为一种刻意的视觉特征加以运用。与此同时,Joseph Fatula 的 **Two Slice** 将极简主义推向了极致,其字符高度仅为两个像素。
尽管这些字体唤起了复古情怀,但它们并非粗糙的点阵图,而是基于矢量的现代工具。Vercel 的 **Geist Pixel** 因其对生产级可靠性的关注而脱颖而出。许多装饰性像素字体在缩放时会失真或难以适配系统指标,而 Geist Pixel 则被设计为一套稳健的排版系统。通过优先处理精密的字距调整、元数据和垂直度量等“隐形”工作,Geist Pixel 弥合了怀旧质感与现代界面设计严苛要求之间的鸿沟。
Hacker News
最新 | 过往 | 评论 | 提问 | 展示 | 招聘 | 提交
登录
一些有趣的现代像素字体 (aresluna.org)
11 分,发布者:zdw,1 小时前 | 隐藏 | 过往 | 收藏 | 3 条评论 | 帮助
Boltgolt 22 分钟前 | 下一条 [-]
> Geist Pixel 不是一款新奇字体。它是一个系统扩展。
好的大语言模型
回复
rebolek 9 分钟前 | 上一条 | 下一条 [-]
我想要更好的 Topaz。我最喜欢的字体。
回复
MrClouds 1 小时前 | 上一条 [-]
喜欢像素风格的 Geist。
回复
指导原则 | 常见问题 | 列表 | API | 安全 | 法律 | 申请 YC | 联系
搜索:
Rosalind 是一个基于 Rust 开发的确定性基因组学引擎,专为处理全基因组工作负载而设计,内存占用低于 100 MB。与需要 50 GB 以上内存和高端基础设施的传统流水线(如 GATK、BWA)不同,Rosalind 采用了 $O(\sqrt{t})$ 内存模型。它通过将工作负载拆分为数据块、复用滚动边界以及使用高度压缩的树结构,将数据维持在 L1/L2 缓存内,从而实现这一目标。 主要特点包括: * **边缘计算就绪:** 非常适合医院工作站、临床笔记本电脑和现场实验设备,确保患者数据保留在本地。 * **位级确定性:** 保证多次运行的输出完全一致,无论分区方式如何,简化了审计和临床标准作业程序 (SOP)。 * **流式处理优先:** 在生成 SAM、BAM 和 VCF 文件时无需生成大型中间文件,从而降低了 I/O 和存储压力。 * **可组合性:** 可通过 Rust 插件或 Python 绑定进行扩展,使开发者能够构建自定义的生物信息学流水线,并继承 Rosalind 在内存和确定性方面的优势。 Rosalind 专为临床诊断、疫情监测和缺乏高内存服务器的教学环境而构建。它为在标准硬件上处理群体规模的基因组数据提供了一种稳健、可重复且高效的解决方案。
Hacker News
最新 | 往期 | 评论 | 提问 | 展示 | 招聘 | 提交
登录
Rosalind:一个用 Rust 编写的基因组学工具包,可在笔记本电脑上运行全基因组流程 (github.com/logannye)
9 分,samuell 发布于 1 小时前 | 隐藏 | 往期 | 收藏 | 讨论
帮助
社区准则 | 常见问题 | 列表 | API | 安全性 | 法律声明 | 申请 YC | 联系我们
搜索:
 近期规模为690亿美元的两年期美国国债拍卖中标收益率为4.071%,创下2025年2月以来的最高水平,较上月上升了26个基点。尽管收益率有所上升,但此次拍卖表现平平。中标收益率与发行前交易(When-Issued)水平完全一致,较近期出现尾部(tailing)的拍卖略有改善;认购倍数为2.64倍,略高于过去六次拍卖的平均水平。
内部指标同样表现平庸:间接竞标者获配比例为57.6%,交易商获配比例为12.30%。总的来说,此次拍卖被视为“乏善可陈”且表现中规中矩。市场关注度明显不足,因为交易员正忙于应对受伊朗潜在协议传闻影响而大幅下跌的油价,导致市场注意力更多地集中在地缘政治头条新闻上,而非国债基本面。
近期规模为690亿美元的两年期美国国债拍卖中标收益率为4.071%,创下2025年2月以来的最高水平,较上月上升了26个基点。尽管收益率有所上升,但此次拍卖表现平平。中标收益率与发行前交易(When-Issued)水平完全一致,较近期出现尾部(tailing)的拍卖略有改善;认购倍数为2.64倍,略高于过去六次拍卖的平均水平。
内部指标同样表现平庸:间接竞标者获配比例为57.6%,交易商获配比例为12.30%。总的来说,此次拍卖被视为“乏善可陈”且表现中规中矩。市场关注度明显不足,因为交易员正忙于应对受伊朗潜在协议传闻影响而大幅下跌的油价,导致市场注意力更多地集中在地缘政治头条新闻上,而非国债基本面。
 在一项令人惊讶的政治转变中,国会即将通过《21世纪住房之路法案》(21st Century ROAD to Housing Act),旨在遏制机构投资者在单户住宅市场的主导地位。这项立法得到了唐纳德·特朗普、伊丽莎白·沃伦和蒂姆·斯科特这一罕见联盟的支持,它禁止大型投资者购买绝大多数现有的单户住宅,从而有效地保护了入门级住房免受华尔街的收购。
多年来,反垄断人士一直认为,以 Invitation Homes 等公司为代表的企业所有权推高了租金,征收了各种乱七八糟的费用,并导致中产阶级家庭流离失所。尽管最初遭到了众议院领导层和行业支持派的抵制,但最终的妥协方案允许企业继续开展“建房出租”项目,同时禁止它们收购现有的7000万套住房库存。
虽然该法案并未解决所有住房问题,例如机构对公寓大楼日益增长的控制,但它代表了对长期以来将美国住房视为私募股权资产类别这一政策的重大民粹主义转向。类似于吉米·卡特时期放松管制的影响,这项立法标志着未来政策制定者如何限制企业对美国基本民生影响的一个潜在转折点。
在一项令人惊讶的政治转变中,国会即将通过《21世纪住房之路法案》(21st Century ROAD to Housing Act),旨在遏制机构投资者在单户住宅市场的主导地位。这项立法得到了唐纳德·特朗普、伊丽莎白·沃伦和蒂姆·斯科特这一罕见联盟的支持,它禁止大型投资者购买绝大多数现有的单户住宅,从而有效地保护了入门级住房免受华尔街的收购。
多年来,反垄断人士一直认为,以 Invitation Homes 等公司为代表的企业所有权推高了租金,征收了各种乱七八糟的费用,并导致中产阶级家庭流离失所。尽管最初遭到了众议院领导层和行业支持派的抵制,但最终的妥协方案允许企业继续开展“建房出租”项目,同时禁止它们收购现有的7000万套住房库存。
虽然该法案并未解决所有住房问题,例如机构对公寓大楼日益增长的控制,但它代表了对长期以来将美国住房视为私募股权资产类别这一政策的重大民粹主义转向。类似于吉米·卡特时期放松管制的影响,这项立法标志着未来政策制定者如何限制企业对美国基本民生影响的一个潜在转折点。
在法拉利推出其首款电动汽车“Luce”后,该公司股价一度下跌了 8%。这款售价 64 万美元的汽车由法拉利与前苹果设计总监乔纳森·艾维(Jony Ive)合作设计,其简约的轿车式外观在分析师和投资者中引发了分歧。 尽管 Luce 拥有令人印象深刻的性能——零百加速仅需 2.5 秒,续航里程达 329 英里——但批评者认为其设计背离了该品牌标志性的跑车传统。一些市场专家将其外观比作普通的电动汽车,质疑它是否符合法拉利的高端定位。作为该公司首款五座车型,该车显然瞄准了富裕家庭,而非传统的汽车发烧友。 此次发布正值法拉利战略调整之际;该公司近期缩减了电气化目标,计划到 2030 年仅有 20% 的车型为纯电动汽车。尽管法拉利首席执行官贝内代托·维尼亚(Benedetto Vigna)坚称该车代表了一种大胆且必要的演进,但市场反应表明,人们对这一“新愿景”能否成功引起品牌核心客户群的共鸣仍存在重大疑虑。
在法拉利发布首款电动汽车“Luce”后,其股价出现下跌。这款车的设计引发了巨大争议。作为与前苹果设计师乔尼·艾维(Jony Ive)的合作成果,该车遭到了观察人士的严厉批评,被指“廉价”、“无聊”,且缺乏法拉利品牌标志性的美学设计。
批评者将这款车与现代汽车或路特斯Elise等非豪华车型相提并论,一些人认为艾维在消费电子领域的设计专长并不能很好地转化为汽车设计。Hacker News上的讨论凸显了意见的分歧:尽管一些支持者指出,这种非传统的造型是为了追求空气动力学效率,而非受限于传统的发动机布局,但公众舆论普遍持负面态度。无论这款车是红色、蓝色还是黄色,其设计都没能打动那些期待传统法拉利外观的受众。