请启用 JavaScript 并关闭任何广告拦截器
每日HackerNews RSS
抱歉。
**WhatChord** 是一款通过非传递性评分引擎对“候选对象”(可能的和弦名称)进行排名,从而识别 MIDI 弹奏和弦的应用程序。由于音乐命名常涉及循环关系(例如:A 胜过 B,B 胜过 C,C 胜过 A),引擎无法使用标准排序。因此,它采用了一种 $O(n^2)$ 的“线性化”算法来排列候选对象。 在保持输出结果“字节完全一致”的前提下,最初的性能优化尝试仅提升了 30% 的速度,其中包括: * **门控掩码 (Gate Masks):** 预先计算硬规则的适用性,以跳过不必要的检查。 * **短路逻辑 (Short-circuiting):** 当得分差距较大时,绕过完整的 $O(n^2)$ 引擎。 当团队不再要求低排名、非必要选项的输出必须与原先字节完全一致时,取得了突破性进展。通过修剪低分、难以被用户发现的候选对象“长尾”,并建立一个安全的“显示阈值”,候选集合的规模得到了显著缩小。 这一改变在保留了应用程序核心功能(即正确识别第一和弦及所有有效备选方案)的同时,将未缓存状态下的排名时间缩短了超过 85%。这一经验表明,提升算法性能最有效的方法,往往是重新定义问题,使其更贴合实际的产品需求。
抱歉。
在混乱之中,叙述者和室友道恩观察到花园里筑巢的一只知更鸟。他们就这只鸟是否代表试图从阴间联络的已故亲人展开了一场异想天开且带有病态色彩的辩论。这场对话演变成了一系列关于他们父母的性别、恋爱史以及在灵界可能经历的性别转换等荒诞猜测。 叙述者以要求报销费用结束了这段记录,语气也从对存在主义的沉思突然转向了琐碎的抱怨。他们详细列出了前往吉尔丁(Gilding’s)一行的开销,包括税费、交通费和火车票,总计 227 英镑,并将整个经历斥为“苦难与敲诈”的混合体。
抱歉。
 开发者近期在 “Snow” 模拟器上成功实现了 A/UX 1.1(苹果公司早期为 68k Mac 开发的 UNIX 系统)的稳定运行。这一里程碑得益于社区成员 Dominic Sharp 提供的一套新归档的珍稀 34 张软盘。
运行 A/UX 1.1 的过程充满挑战,因为该操作系统对视频硬件极为挑剔。开发者不得不在 Snow 中实现 Macintosh II 的 “Toby” 显卡,并完成复杂的多阶段安装过程,包括分区、System 6 “引导程序”以及 SASH(独立 Shell)环境配置。
该过程还需要修复 Snow 模拟器中的两个关键问题:一个是导致修饰键卡住的 ADB 键盘实现错误,另一个是阻止内核启动的 SCSI DMA 时序错误。在更换了 26 张安装盘后,系统终于成功引导,证明了 A/UX 1.1 可以在 Snow 上流畅运行。开发者计划在未来支持磁带驱动器模拟,以简化此类老旧介质的安装流程。这一项目的成功确保了又一段苹果计算历史能够通过模拟技术得以留存。
开发者近期在 “Snow” 模拟器上成功实现了 A/UX 1.1(苹果公司早期为 68k Mac 开发的 UNIX 系统)的稳定运行。这一里程碑得益于社区成员 Dominic Sharp 提供的一套新归档的珍稀 34 张软盘。
运行 A/UX 1.1 的过程充满挑战,因为该操作系统对视频硬件极为挑剔。开发者不得不在 Snow 中实现 Macintosh II 的 “Toby” 显卡,并完成复杂的多阶段安装过程,包括分区、System 6 “引导程序”以及 SASH(独立 Shell)环境配置。
该过程还需要修复 Snow 模拟器中的两个关键问题:一个是导致修饰键卡住的 ADB 键盘实现错误,另一个是阻止内核启动的 SCSI DMA 时序错误。在更换了 26 张安装盘后,系统终于成功引导,证明了 A/UX 1.1 可以在 Snow 上流畅运行。开发者计划在未来支持磁带驱动器模拟,以简化此类老旧介质的安装流程。这一项目的成功确保了又一段苹果计算历史能够通过模拟技术得以留存。
如果您拥有一个个人网站,并且至少有一位朋友,作者建议您建立一个“网络环”(webring)。“网络环”本质上是一个由拥有共同爱好或兴趣的网站组成的环形链接网络,旨在促进社区交流与发现。 您可以手动设置,让每位参与者链接到环中的下一个站点。对于更高级的自动化方法,作者建议使用网络服务器将成员的网址存储在 JSON 文件中。通过路由设置 `/next`(下一个)、`/prev`(上一个)和 `/random`(随机)端点,您可以让用户在各个站点间顺畅地浏览。 作者通过免费的 Cloudflare Worker 成功实现了这一功能,并指出这种设置既易于管理,又是一种与在线他人建立联系的有趣方式。
关于“网页环”(webrings)的 Hacker News 讨论捕捉到了一场怀旧的辩论,即早期互联网去中心化、“人性化”的本质,与现代搜索和社交媒体的实用性之间的博弈。
网页环起源于 20 世纪 90 年代,是一系列以环形或列表形式相互链接的网站,允许用户在相关的独立站点之间导航。批评者认为,这种结构在功能上已经过时且脆弱,远不如现代基于搜索的发现方式或简单的精选链接列表。
然而,支持者将网页环视为对现代网络“量化和功利化”的一种抗议。他们认为,网页环促进了真实的社区交流,优先考虑偶然性,并通过允许创作者在没有算法干预或商业动机的情况下相互链接,保持了网络的“人性”。虽然有些人认为这纯粹是怀旧,但另一些人则认为,它是对抗现代“社交媒体垃圾信息”的必要解毒剂。归根结底,人们达成了一种共识:尽管网页环在技术设计上并非最优,但作为一种从企业掌控的平台手中夺回开放、互联网络的创意实践,它们依然具有深远的意义。
 在过去的十五年里,作者对 XML 的态度已从最初的热衷推崇转变为更务实、更成熟的视角。回顾 21 世纪初的“XML 热潮”及其随后的抵触情绪(常被表达为“仇恨”),作者将技术关系比作人际关系:从最初的迷恋,转变为对工具优缺点及其内在复杂性更深层、更细致的理解。
针对开发者对于掌握 XML 专业生态系统难度较大的抱怨,作者指出,这些挑战并非 XML 所独有。任何数据建模任务,无论是使用 SQL 还是其他格式,都要求开发者成为领域专家。归根结底,作者认为用来描述技术的感性语言——“爱”或“恨”——往往是表演性或隐喻性的,其作用更像是个人对音乐的品味,而非真正的喜爱或敌意。尽管作者承认冗长语法带来的困扰,但他坚持认为,XML 依然是实现互操作性的重要工具,即便数据最终存储在关系型数据库中,它仍是标准的传输格式。
在过去的十五年里,作者对 XML 的态度已从最初的热衷推崇转变为更务实、更成熟的视角。回顾 21 世纪初的“XML 热潮”及其随后的抵触情绪(常被表达为“仇恨”),作者将技术关系比作人际关系:从最初的迷恋,转变为对工具优缺点及其内在复杂性更深层、更细致的理解。
针对开发者对于掌握 XML 专业生态系统难度较大的抱怨,作者指出,这些挑战并非 XML 所独有。任何数据建模任务,无论是使用 SQL 还是其他格式,都要求开发者成为领域专家。归根结底,作者认为用来描述技术的感性语言——“爱”或“恨”——往往是表演性或隐喻性的,其作用更像是个人对音乐的品味,而非真正的喜爱或敌意。尽管作者承认冗长语法带来的困扰,但他坚持认为,XML 依然是实现互操作性的重要工具,即便数据最终存储在关系型数据库中,它仍是标准的传输格式。
对不起。
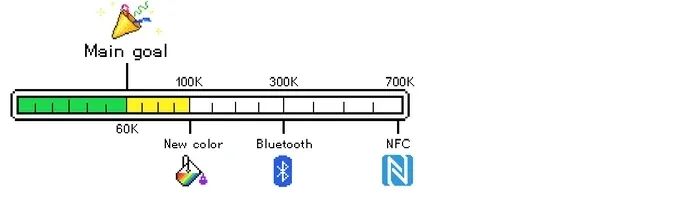 为了回应社区反馈,Flipper Devices 重申了其对 Flipper Zero 固件的承诺。虽然公司目前将工作重心转向新硬件的开发,但他们承诺将通过结构化的异步流程来支持社区贡献,从而维护现有的固件。
为了有效地管理这一流程,团队引入了一套新的参与框架:
* **以 GitHub 为中心的协作:** 所有功能需求必须通过 GitHub Discussions 提交,并由社区进行投票。团队将根据这些投票结果,优先处理并实施相应功能。
* **更严格的指导方针:** 合并请求(Pull Requests)现在将面临严格的评估,包括强制性的集成和回归测试,以确保稳定性。
* **更明确的界限:** 官方开发沟通将仅限于 GitHub 进行,而 Discord 和 Reddit 等社交渠道将保留用于一般的社区讨论。
公司强调,由于团队规模较小,他们无法进行实时聊天,但这种新方法可以确保社区最迫切的需求得到解决,在保持核心固件稳定性的同时,推动 Flipper Zero 平台的不断发展。
为了回应社区反馈,Flipper Devices 重申了其对 Flipper Zero 固件的承诺。虽然公司目前将工作重心转向新硬件的开发,但他们承诺将通过结构化的异步流程来支持社区贡献,从而维护现有的固件。
为了有效地管理这一流程,团队引入了一套新的参与框架:
* **以 GitHub 为中心的协作:** 所有功能需求必须通过 GitHub Discussions 提交,并由社区进行投票。团队将根据这些投票结果,优先处理并实施相应功能。
* **更严格的指导方针:** 合并请求(Pull Requests)现在将面临严格的评估,包括强制性的集成和回归测试,以确保稳定性。
* **更明确的界限:** 官方开发沟通将仅限于 GitHub 进行,而 Discord 和 Reddit 等社交渠道将保留用于一般的社区讨论。
公司强调,由于团队规模较小,他们无法进行实时聊天,但这种新方法可以确保社区最迫切的需求得到解决,在保持核心固件稳定性的同时,推动 Flipper Zero 平台的不断发展。
这篇 Hacker News 帖子讨论了 Flipper Zero 的未来发展。尽管该项目已经实现了最初的目标,但由于公司将重心转向新产品,核心固件的更新有所放缓,引发了社区的不满。
讨论的焦点主要集中在固件是否应该完全开源。一些用户认为,公司对官方代码库的严格控制以及对其 Discord 频道的激进审核,正将用户推向非官方的、功能“全包含”的第三方固件。支持官方立场的人则认为,保持产品的“完成度”是一种美德,且过于激进的功能集会招致不必要的监管审查。
除了软件生命周期之外,讨论还演变成了一场关于网络安全社区中“兽迷”(furry)文化盛行与否的争议性话题。虽然一些用户对该项目品牌和文档中的美学选择表示不满,但另一些人则认为信息安全界这种多元化且带有“反主流文化”色彩的构成是一个积极的包容性特征。归根结底,共识表明对于许多用户而言,无论官方企业支持与更广泛的黑客社区之间存在怎样的持续紧张关系,Flipper Zero 依然是硬件爱好者手中多功能的“瑞士军刀”。
所提供的内容并非可读的文档或文章,而是 PDF 的原始源代码。 它包含了 PDF 文件典型的技术结构元素,包括: * **文件头与版本信息:** `%PDF-1.7` 表示文档格式。 * **交叉引用表 (xref):** 一系列字节偏移量,用于告知 PDF 阅读器特定对象在文件中的位置。 * **对象定义:** 用于组织数据、元数据和图形内容的数字标识符(例如 `194 0 obj`)。 * **尾部与 Startxref:** 供软件定位文件结构并正确结束文档的信息。 * **压缩流:** 最后几行代表压缩数据流(“stream”标签),其中很可能以二进制格式包含了 PDF 的实际可见内容(如文本、图像或格式说明),无法作为纯文本阅读。 总之,这是数字文件内部架构的底层技术呈现,而非可读内容。
达特茅斯学院近期针对一款名为“Phosphor”的AI辅导平台进行了一项研究。报告显示,充分利用该材料的学生,期末考试成绩提高了0.71至1.30个标准差,效果显著。研究人员认为,大语言模型(LLM)能够提供传统教材所无法实现的个性化且可扩展的反馈。
然而,Hacker News社区对这些结果表达了强烈的质疑。主要批评意见包括:
* **选择偏差**:批评者指出该研究属于观察性研究而非随机对照试验。主动选择使用AI工具的学生通常动力更足或表现更优,因此难以将平台的有效性与学生的内驱力区分开来。
* **方法论缺陷**:评论者质疑其统计设计,指出参与度指标可能仅仅反映了学生对新鲜事物的好奇或教师的热情,而非教学价值。此外,也有人担心考试题目可能与AI平台的内容存在重叠。
* **对“辅导”的定义**:许多人认为该平台更像是一款AI评分的测试工具,而非真正意义上的辅导员,因为后者应具备识别并纠正学生特定认知偏差的能力。
尽管存在上述批评,但许多人仍承认该平台高达90%的自愿采用率表明,它确实能有效吸引那些平时很少接触传统课程材料的学生。
马克·扎克伯格告诉员工,人工智能智能体的发展尚未达到预期。 Mark Zuckerberg tells staff that AI agents haven't progressed enough
9 天前
Meta 首席执行官马克·扎克伯格近日承认,公司向人工智能领域的转型速度慢于预期。尽管今年早些时候采取了激进措施——包括裁员 8000 人,并将 7000 名员工重新分配到专门的 AI 部门——但扎克伯格坦言,这些结构性调整尚未产生预期的成果。 在一次内部员工大会上,扎克伯格将此前的裁员形容为“混乱的”,并指出重组是由于迫切需要适应快速变化的行业环境。来自这些新 AI 部门员工的反馈则颇为负面,他们形容工作环境“令人心碎”。尽管面临内部困境且进展缓慢,Meta 仍坚定致力于该技术,计划今年在 AI 基础设施上投入高达 1450 亿美元。不过,扎克伯格依然保持乐观,预计这些重大投资将在未来三到六个月内带来实质性的改善。
抱歉。
arXivLabs 是一个允许合作者直接在我们的网站上开发并分享 arXiv 新功能的框架。与 arXivLabs 合作的个人和组织都认同并接受我们关于开放、社区、卓越和用户数据隐私的价值观。arXiv 致力于这些价值观,并仅与遵循这些价值观的合作伙伴开展合作。您是否有为 arXiv 社区增值的项目想法?了解更多关于 arXivLabs 的信息。
抱歉。