 格陵兰正在采取措施,大幅改善其偏远东部和北部地区的互联网接入,不再依赖美国供应商。国家电信公司 Tusass 与法国公司 Eutelsat 的 OneWeb 卫星网络合作,为缺乏传统基础设施(如海底电缆)的社区提供更快速、更稳定的连接。
此举旨在弥合塔西拉克、伊托科托米特和卡纳克等城镇居民的数字鸿沟,这些居民长期以来一直遭受着不可靠的服务。Tusass 曾考虑过埃隆·马斯克的 Starlink,但由于已建立的信任和熟悉度,他们选择扩大与 Eutelsat 的现有合作关系。
重要的是,此举也反映了格陵兰希望对其关键电信基础设施保持控制的愿望,解决了对国家安全的担忧,并优先考虑对通信系统的本地管理。预计塔西拉克将成为年底前首批受益于改进服务的地区,未来还将进一步扩展。
格陵兰正在采取措施,大幅改善其偏远东部和北部地区的互联网接入,不再依赖美国供应商。国家电信公司 Tusass 与法国公司 Eutelsat 的 OneWeb 卫星网络合作,为缺乏传统基础设施(如海底电缆)的社区提供更快速、更稳定的连接。
此举旨在弥合塔西拉克、伊托科托米特和卡纳克等城镇居民的数字鸿沟,这些居民长期以来一直遭受着不可靠的服务。Tusass 曾考虑过埃隆·马斯克的 Starlink,但由于已建立的信任和熟悉度,他们选择扩大与 Eutelsat 的现有合作关系。
重要的是,此举也反映了格陵兰希望对其关键电信基础设施保持控制的愿望,解决了对国家安全的担忧,并优先考虑对通信系统的本地管理。预计塔西拉克将成为年底前首批受益于改进服务的地区,未来还将进一步扩展。
每日HackerNews RSS
列奥·达姆罗什的传记《说书人》精彩地展现了罗伯特·路易斯·史蒂文森的一生,不仅是一位作家,更是一位充满活力和冒险精神的人。本书探讨了传记本身试图理解注定最终被遗忘的个人的“内在自我”,并认为传记作者和小说家一样,最终都是说书人。达姆罗什以对研究对象的喜爱而著称,揭示了史蒂文森的古怪、脆弱和持久的精神。 传记突出了史蒂文森非传统的生活——他与疾病的斗争,与年长且独立坚强的范妮充满激情的婚姻,以及最终在萨摩亚作为“图西塔拉”(说书人)找到的平静,在那里他备受尊敬。范妮成为一个关键人物,一位强大而复杂的女性,她挑战并激励了史蒂文森,她自己非凡的一生也值得认可。 达姆罗什强调了史蒂文森的文学多才多艺,从广受欢迎的儿童书籍如《金银岛》到心理惊悚片如《杰基尔博士与海德先生》,以及富有洞察力的游记。最终,《说书人》是对一位充分拥抱生活、留下至今仍能吸引读者的遗产的动人致敬。这是一部像史蒂文森自己的作品一样,拓展我们经验并邀请我们进入另一个世界的传记。
## 罗伯特·路易斯·史蒂文森与一个有争议的标题
最近一篇Hacker News上的讨论围绕着《哈德逊评论》的一篇文章展开,文章标题为“罗伯特·路易斯·史蒂文森的吉普赛生活”,引发了关于使用“吉普赛”一词的争论。许多评论员赞扬了史蒂文森的冒险小说,如《金银岛》和《绑架》,并指出它们对年轻男孩的吸引力以及持久的品质。
然而,这个标题引发了一场关于“吉普赛”是否构成诽谤的讨论,尤其是在指代罗姆人时。一些人认为这个词具有冒犯性,而另一些人则指出它在历史上被使用,并且在某些罗姆人社区中被接受,并将这种现象与其他群体名称的争论相提并论。这场讨论凸显了人们对潜在有害语言的不同敏感度和认识。
最终,这场争论掩盖了文章本身,许多人认为标题是一个糟糕的编辑选择,将注意力吸引到这个词上,而不是史蒂文森的生活和作品。这场对话也涉及了更广泛的社会敏感性趋势以及作者通过语言引发反应的作用。
## 萨科齐开始服刑,开创先例 前法国总统尼古拉·萨科齐成为现代法国历史上首位入狱的前国家元首,他因共谋使用已故利比亚独裁者卡扎菲的非法资金为2007年竞选活动提供资金而被判处五年徒刑。尽管他始终坚称自己无罪并对判决提出上诉,但70岁的他已向巴黎拉桑特监狱报到,受到支持者高呼他名字的迎接。 萨科齐被判犯有犯罪共谋罪,但并未被判直接收受资金。此案的中心是他的助手与卡扎菲的情报主管会面,以确保竞选资金。目前,他被关押在监狱的隔离病房,以确保安全,且活动和基本设施受到限制。 马克龙总统承认事态的严重性,表示这一事件自然会引发评论,司法部长计划访问以确保萨科齐的安全。萨科齐已誓言保持坚强,并相信“真相将会胜出”,将他的监禁视为对法国本身的打击。他计划通过阅读书籍来消磨时间,包括《基督山伯爵》,讲述了一个被冤枉监禁和复仇的故事。
研究人员完成首次人体肠内通气可行性试验。
Researchers complete first human trial on viability of enteral ventilation
42 天前
启用 JavaScript 和 Cookie 以继续。
## 肠道通气:人体试验总结
研究人员已完成首次人体试验,研究**肠道通气**——通过直肠输送氧气。这项研究在Hacker News上被重点介绍,旨在评估该程序的**安全性**,而非有效性,并成功地证明了参与者的耐受性。
这个概念并非新颖;一些动物,如彩绘乌龟,甚至历史上的人类(通过烟熏灌肠用于溺水者),都可以通过高度血管化的直肠组织吸收氧气。虽然看似不寻常,但讨论探讨了潜在的应用,超越了紧急呼吸支持,包括耐力运动兴奋剂的可能性,甚至辅助自由潜水。
然而,评论员强调直肠输送氧气与传统肺功能之间的显著差异,指出肺部具有远大的表面积。这项试验是第一步,未来的研究将集中在确定该程序在向血液输送氧气和潜在减少对呼吸机的依赖方面的实际功效。
如果你造出这么愚蠢的“工具”,为什么要宣传这件事?
If you'd built a "tool" that stupid, why would you advertise the fact?
42 天前
 古生物学家迈克尔·韦德尔收到了一封来自academia.edu的奇怪邮件,称他的关于蜥脚类恐龙神经棘的科学论文被他们的AI转变成了“类比”。该AI将棘的 bifurcation(分叉)比作河口三角洲——韦德尔认为这种比较毫无意义,相当于将研究比作《追忆似水年华》。
韦德尔对AI的滥用感到沮丧,强调了真正有帮助的应用(如ChatGPT提供的编程协助)与这种无意义的输出之间的差距。他质疑为什么平台会*宣传*这种有缺陷的“工具”,并拒绝付费升级以查看更多例子。这一事件凸显了人们对AI生成内容质量和相关性的日益担忧,尤其是在应用于科学研究等专业领域时。
古生物学家迈克尔·韦德尔收到了一封来自academia.edu的奇怪邮件,称他的关于蜥脚类恐龙神经棘的科学论文被他们的AI转变成了“类比”。该AI将棘的 bifurcation(分叉)比作河口三角洲——韦德尔认为这种比较毫无意义,相当于将研究比作《追忆似水年华》。
韦德尔对AI的滥用感到沮丧,强调了真正有帮助的应用(如ChatGPT提供的编程协助)与这种无意义的输出之间的差距。他质疑为什么平台会*宣传*这种有缺陷的“工具”,并拒绝付费升级以查看更多例子。这一事件凸显了人们对AI生成内容质量和相关性的日益担忧,尤其是在应用于科学研究等专业领域时。
Spotify因在其平台上允许美国移民及海关执法局(ICE)的招聘广告而面临批评,尽管用户对此表示强烈抗议,并担心广告中可能带有煽动恐惧的语言(“危险的非法移民”)。Spotify为这一决定辩护,称这些广告符合其政策,并且是更广泛的政府宣传活动的一部分。 其他平台,如HBO Max、YouTube和Meta也在投放这些广告,因为ICE正在积极招募Z世代,招聘职位超过14,000个。国土安全部庆祝该活动的成功,称收到了超过150,000份申请。 这场争议导致订阅取消和艺术家抵制,反映了过去围绕Spotify内容政策和政治捐款的问题(包括向特朗普就职典礼捐款15万美元)。与此同时,Spotify首席执行官丹尼尔·埃克正准备卸任,并且该公司对一家德国人工智能军事防御公司进行了大量投资,进一步加剧了对该平台选择的批评。
## Spotify & ICE 广告争议 - 摘要
近期报告显示,Spotify在其常规内容中投放了美国移民及海关执法局(ICE)的招聘广告,引发了愤怒和抵制呼声。这些广告也出现在HBO Max、YouTube、X等平台,引发了关于这些公司是否有责任避免从潜在有害的政府行为中获利的质疑。
许多评论员对Spotify愿意投放这些广告表示担忧,并将之与历史上企业协助压迫政权的情况相提并论。虽然一些人承认平台拒绝政府广告可能会带来负面影响,但另一些人认为应该采取立场,即使这会影响工作保障。
讨论还集中在Spotify的替代方案上,用户提到了YouTube Music、Tidal和Bandcamp。一些人强调了更广泛的企业共谋问题,以及支持像IPFS和Bit Torrent这样的去中心化平台的需求。这场辩论也涉及到了Joe Rogan在Spotify上的存在,一些人引用他有争议的内容作为过去考虑离开该平台的理由。
绘制文本并非易事:基准测试控制台与图形渲染。
Drawing Text Isn't Simple: Benchmarking Console vs. Graphical Rendering
42 天前
 ## 从 Go 到 C#: 一个基于文本的文件管理器之旅
为了学习 Go,作者开始了一个具有挑战性的项目:重写 FAR Manager,一个高效的基于文本的文件管理器。最初在 Go 中的尝试在寻求高性能屏幕输出时遇到了瓶颈,发现该语言不适合低级图形任务。转向 C# 和 .NET 开启了 GPU 加速渲染的大门。
对 GDI、DirectX 和 Vulkan 进行广泛测试后发现,DirectX 提供了最佳性能,但真正的瓶颈并非渲染 API 本身——而是 Windows 的 CPU 密集型字体绘制。一种将字符缓存为纹理的巧妙解决方案最初显示出希望,但最终证明对于典型用例来说,比优化的直接文本绘制更慢。
最终结论:**DirectX 结合直接文本绘制提供了速度和灵活性的最佳平衡。** 该项目强调了选择合适工具的重要性,打破了常见的性能假设,并强调了实现看似简单的任务(如在屏幕上显示文本)所需的知识深度。
## 从 Go 到 C#: 一个基于文本的文件管理器之旅
为了学习 Go,作者开始了一个具有挑战性的项目:重写 FAR Manager,一个高效的基于文本的文件管理器。最初在 Go 中的尝试在寻求高性能屏幕输出时遇到了瓶颈,发现该语言不适合低级图形任务。转向 C# 和 .NET 开启了 GPU 加速渲染的大门。
对 GDI、DirectX 和 Vulkan 进行广泛测试后发现,DirectX 提供了最佳性能,但真正的瓶颈并非渲染 API 本身——而是 Windows 的 CPU 密集型字体绘制。一种将字符缓存为纹理的巧妙解决方案最初显示出希望,但最终证明对于典型用例来说,比优化的直接文本绘制更慢。
最终结论:**DirectX 结合直接文本绘制提供了速度和灵活性的最佳平衡。** 该项目强调了选择合适工具的重要性,打破了常见的性能假设,并强调了实现看似简单的任务(如在屏幕上显示文本)所需的知识深度。
这个Hacker News讨论围绕一篇博客文章([co.hu](https://co.hu))展开,该文章对控制台和图形方法进行文本渲染性能基准测试。核心观点是,高效绘制文本出乎意料地复杂。
用户们讨论了优化技术,建议范围从使用单个全屏三角形和像素着色器(可能在现代GPU上达到1000fps)到为稀疏文本使用贴合形状的四边形。纹理图集和基于字形级别的缓存(而非字符级别)对于Unicode支持的重要性也被强调。
几位评论者指出了Unicode渲染的细微之处,强调即使对于看似简单的字符,也需要塑形引擎来正确组装字形。Windows Console Host和Windows Terminal(后者使用GPU加速)之间的性能差异也被提及。
有趣的是,一篇关于博客文章*自身*性能的讨论浮出水面,用户报告由于backdrop-filter效果导致Firefox出现滞后,这在讨论渲染优化的一篇文章中显得颇具讽刺意味。最后,包含了一个Y Combinator申请的公告。
模式检测到:邮件调度逻辑 推理步骤已明确… 生成的函数:schedule_email_task() 已部署至代理技能库 未来请求将使用确定性代码
## AutoLearn:自我提升的智能体
一个名为 **AutoLearn (autolearn.dev)** 的新开源项目,旨在简化创建和管理用于自我提升的AI智能体的“技能”,类似于Claude Skills,但仅需一个MCP客户端。AutoLearn是在最近的一次黑客马拉松期间开发的,它允许智能体学习和完善能力,而无需手动维护大量的技能定义。
开发者toobulkeh正在寻求反馈和合作,以进一步开发该项目,目前该项目缺乏自动推理跟踪监控和安全功能。讨论强调了潜在的好处,例如减少AI响应的非确定性,并提高软件开发速度。
讨论中的挑战包括确保智能体在面对众多选项时有效地利用可用工具,以及确定智能体如何识别技能需要改进的时机。 演示视频可在 ([https://youtu.be/s_9m4P9_6jc?si=P7By-zl62GkFMRpH](https://youtu.be/s_9m4P9_6jc?si=P7By-zl62GkFMRpH)) 观看,代码托管在GitHub上 ([https://github.com/tarkaai/autolearn](https://github.com/tarkaai/autolearn))。
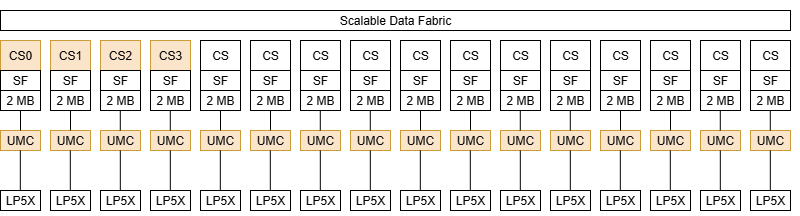 ## AMD Strix Halo:深入剖析Infinity Cache性能
AMD的Strix Halo,为Ryzen AI MAX系列提供动力,结合了16核Zen 5 CPU和强大的20 WGP RDNA 3.5 GPU。其关键特性在于Infinity Cache的实现(32MB),旨在缓解来自快速LPDDR5X-8000内存(256位)的带宽需求。这标志着首次能够详细监控Infinity Cache性能,这得益于可访问的性能计数器。
在华硕ROG Flow Z13上的测试表明,即使在高负载下,该缓存也能有效防止DRAM带宽瓶颈。虽然峰值需求接近256 GB/s的限制,但缓存始终捕获约73%的内存流量。分辨率显著影响性能;更高的分辨率会降低缓存命中率,但系统仍然保持稳定。
有趣的是,尽管PS5利用了更高的理论带宽(448 GB/s)且没有内存侧缓存,但Strix Halo的图形性能与PS5相当。这突显了AMD方法的效率——在缓存大小与DRAM带宽之间取得平衡,这种策略也出现在过去的Intel iGPU和当前的游戏主机设计中。最终,分析证实了AMD的设计选择是有效的,但来自AMD工具的直接Infinity Cache命中率数据将提供更深入的见解。
## AMD Strix Halo:深入剖析Infinity Cache性能
AMD的Strix Halo,为Ryzen AI MAX系列提供动力,结合了16核Zen 5 CPU和强大的20 WGP RDNA 3.5 GPU。其关键特性在于Infinity Cache的实现(32MB),旨在缓解来自快速LPDDR5X-8000内存(256位)的带宽需求。这标志着首次能够详细监控Infinity Cache性能,这得益于可访问的性能计数器。
在华硕ROG Flow Z13上的测试表明,即使在高负载下,该缓存也能有效防止DRAM带宽瓶颈。虽然峰值需求接近256 GB/s的限制,但缓存始终捕获约73%的内存流量。分辨率显著影响性能;更高的分辨率会降低缓存命中率,但系统仍然保持稳定。
有趣的是,尽管PS5利用了更高的理论带宽(448 GB/s)且没有内存侧缓存,但Strix Halo的图形性能与PS5相当。这突显了AMD方法的效率——在缓存大小与DRAM带宽之间取得平衡,这种策略也出现在过去的Intel iGPU和当前的游戏主机设计中。最终,分析证实了AMD的设计选择是有效的,但来自AMD工具的直接Infinity Cache命中率数据将提供更深入的见解。
## AMD Strix Halo & Infinity Cache:摘要
一篇近期文章(chipsandcheese.com)引发了Hacker News关于AMD的Infinity Cache的讨论,这是一种连接到内存控制器而非CPU本身的超大缓存内存。这种设计旨在减少缓存一致性问题并提高性能,尤其是在共享内存并行处理方面。
讨论强调Infinity Cache并非全新事物——IBM的Power系列使用了类似的“最后一级缓存”设计。虽然它提供了一种经济高效的增加缓存大小的方式,但与传统CPU缓存相比,它引入了更高的延迟。有人推测AMD未来可能会将重点转向更大的L2缓存。
一个关键点是AMD的软件支持,与Nvidia更对开发者友好的生态系统形成对比。尽管AMD在ROCm和兼容层(如HIP)方面做出了努力,但在即使是像Strix Halo这样强大的硬件上,运行AI模型仍然存在挑战。讨论表明,AMD需要优先投资软件,并可能采用更开放源代码的方法才能有效竞争。最终,AMD硬件的成功在很大程度上依赖于一个强大且易于访问的软件环境。
## Erowid:怀旧且重要的资源
最近的Hacker News讨论提到了Erowid (erowid.org),这是一个长期存在的网站,记录了人类与精神活性物质之间复杂的关系。许多用户回忆起年轻时发现这个网站,赞扬其丰富的资料和关注减害的理念——与仅强调禁欲的教育形成了鲜明对比。
一些评论者分享了Erowid提供关键安全信息的故事,甚至通过识别危险的药物相互作用来防止潜在的健康危机。该网站详细的经验库和全面的化学信息被反复引用为宝贵的资源。
对话还涉及了LSD等物质的来源和测试,建议范围从具有供应商信誉的暗网市场到使用试剂测试套件。用户强调了在探索精神活性物质时谨慎和明智决策的重要性,并强调了Psychonautwiki和Tripsit.me等资源与Erowid并列。总的来说,讨论强调了Erowid在一个特定在线社区中持久的遗产,以及它作为一种独特且可能救命的资源的地位。