正在建立安全连接…… 请启用 JavaScript 以继续。 请求 ID: 9b8739dd0028bff2ae5d9fc8e668b0ac
每日HackerNews RSS
抱歉。
当然,桥梁也单纯地提供了绝佳的视野:无论是对战斗者、旁观者,还是最终对艺术家而言皆是如此。到了十七世纪,仪式化的“桥上格斗”(battagliole)已成为威尼斯的标志性娱乐活动之一。这类活动的盛行产生了一系列文字、绘画和印刷记录,这些记录同时也反过来巩固了其人气:其中一些出自威尼斯人之手,另一些则是由外国人创作或为满足外国人的兴趣而作(当时,威尼斯已成为“壮游”的必经之地)。
抱歉。
CachyOS 发布了今年的第四次更新,带来了性能增强、新功能以及多项稳定性修复。 **核心性能与软件包改进:** * **优化:** Python 现在使用扩展的 PGO,新的 GCC 补丁改善了针对现代 Intel 和 AMD CPU 的分支预测调整。 * **安全与稳定性:** `pacman` 现已支持钩子(hooks)的网络隔离,并解决了在高核心数 CPU 上影响 OpenBLAS 的回归问题。 * **工具:** 移除了 `paru`,改用 Shelly;`Resources` 取代了 GNOME 系统监视器。 **安装程序与桌面功能:** * **Hyprland Noctalia:** 现提供一个新的桌面选项,并附带内置预览视频。 * **CachyOS-Welcome:** 增加了对 DNS-over-QUIC 的支持,新增故障排除页面,并扩展了语言本地化。 * **驱动管理 (chwd):** 改进了对具有冲突驱动需求的多 GPU 系统的支持,并为虚拟机添加了 32 位 Vulkan 驱动。 * **系统设置:** 用户服务现具备优化的关机超时设置,以防止系统长时间延迟。 本次发布还修复了安装程序的众多错误,并提升了硬件检测能力。现有用户可通过 `sudo pacman -Syu` 进行更新,无需手动干预。
关于 CachyOS 2026 年 6 月版本发布,Hacker News 上的讨论凸显了该发行版作为一款高性能、以游戏为核心的系统,在从 Windows 转投而来的用户中日益受欢迎。
**核心主题:**
* **性能与兼容性:** 用户称赞 CachyOS 开箱即用的硬件支持,特别是在睡眠/唤醒、Nvidia 固件以及现代电源配置方面。其经过深度优化的定制内核显著提升了响应速度,表现往往优于 Windows。
* **游戏体验:** 得益于 Proton 和 Wine,Linux 游戏生态已大幅成熟。尽管单机游戏运行大多流畅,但使用内核级反作弊系统的竞技游戏(如《Valorant》)仍是完全迁移的主要障碍。
* **AUR 与稳定性:** 对 Arch 用户仓库(AUR)的严重依赖仍是争议焦点。虽然它提供了丰富的软件资源,但部分用户认为其风险较高,更倾向于选择 Fedora 或 Bazzite 等更“稳定”或不可变的发行版。
* **社区评价:** 用户体验褒贬不一。许多“Windows 难民”青睐其流畅的界面和便捷的迁移过程;而另一些用户则批评该发行版过于激进的定制化、包管理器(如 Shelly)可能带来的混乱,以及相较于商业背景支持的发行版,其社区文化显得不够成熟。
总的来说,CachyOS 被视为进阶用户的绝佳选择,但其“折腾”的特性需要用户投入一定的维护精力,这是部分用户所希望避免的。
请启用 JavaScript 和 Cookie 以继续。
抱歉。
Microlink 通过将其软件光栅化器从 Chrome 默认的“SwiftShader”切换为“Mesa llvmpipe”,将其无头 WebGL 的渲染速度提升了四倍。 由于 Microlink 的基础设施运行在无 GPU 的 Linux 节点上,它依赖基于 CPU 的模拟来渲染 WebGL。SwiftShader 设计初衷是为了保守兼容,效率较低,捕获 3D 页面需要约 24 秒。通过配置 Chrome 使用带有 Mesa llvmpipe 的 `ANGLE`(`--use-angle=gl`),该团队利用 JIT 编译和多线程技术,将渲染时间缩短至约 6 秒。 实现这一过程需要自定义的多阶段 Docker 构建以包含更新版本的 Mesa,并配合虚拟显示器(`xvfb`)来支持 GL 表面。为防止“静默失败”(即 Chrome 默认回退到看起来渲染成功但实际为平面 2D 的模式),团队添加了 CI 断言以验证当前活动的渲染器确实是 `llvmpipe`。 虽然这种基于软件的方法无法替代物理 GPU 的性能,但它有效地消除了超时问题,并成功稳定了整个浏览器集群的 WebGL 截图功能。
抱歉。
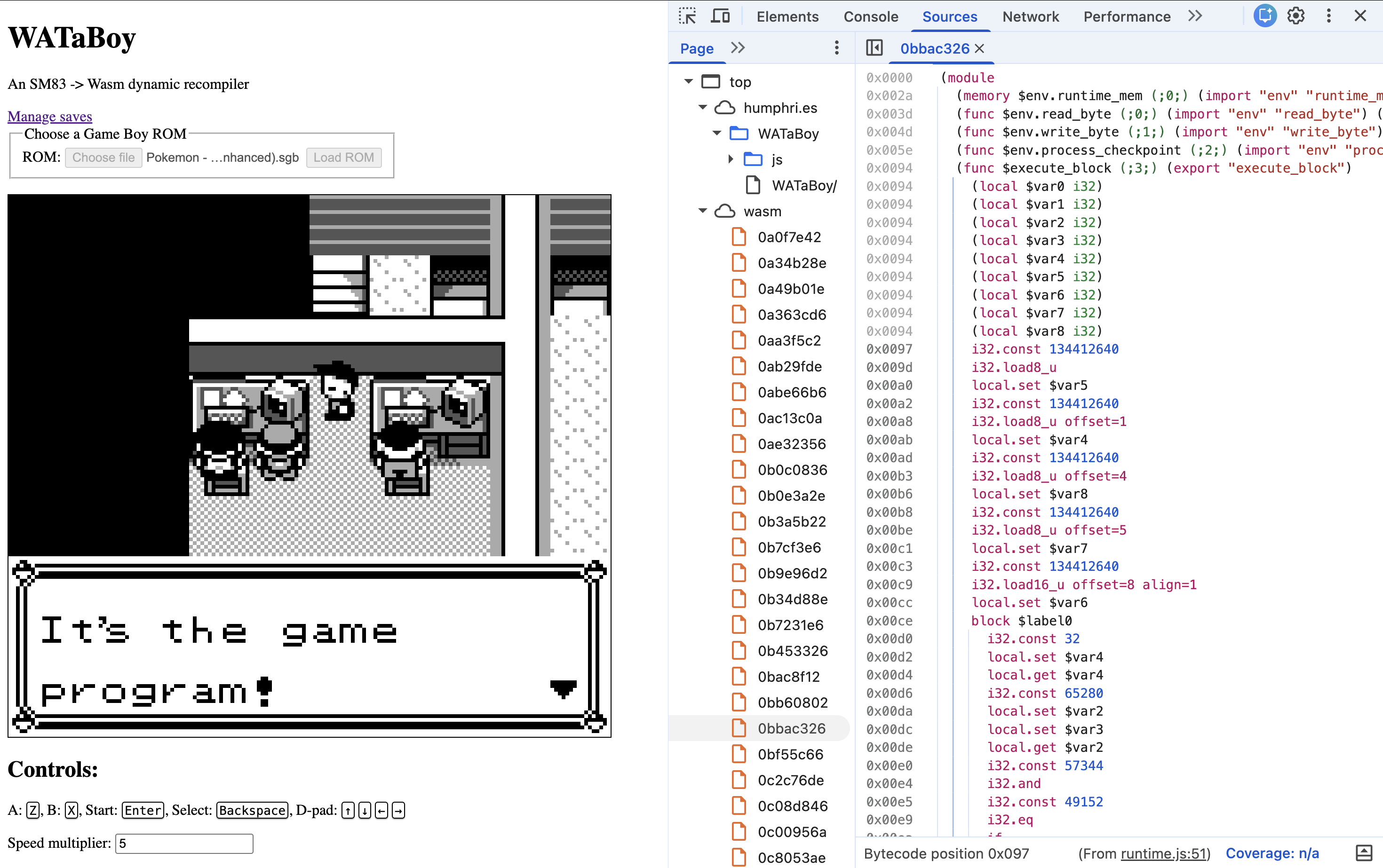 由于苹果对 iOS 上的 JIT 编译进行了限制,诸如 Dolphin 等高性能模拟器通常无法使用。本篇博客探讨了一种替代方案:“JIT-to-Wasm”。该技术通过在运行时生成 WebAssembly (Wasm) 字节码来绕过上述限制,随后由浏览器引擎将其编译为原生机器码。
作者开发了一款名为“WATaBoy”的 Game Boy 模拟器作为概念验证,用于对比该方法与传统解释器的性能。该实现依赖 `wasm-encoder` 来生成字节码,并利用 C ABI 在 Rust 和 JavaScript 之间传递数据。由于 Wasm 采用哈佛架构,作者使用了“后期链接”(late-linking)流程:即由浏览器实例化新的 Wasm 模块,将其添加到主实例的间接函数表中,并通过 `call_indirect` 执行。
尽管 JIT-to-Wasm 方法在性能上优于解释器,但作者指出,它仍缺乏专业模拟器所使用的底层优化(如硬件快速内存访问)。此外,缺乏稳健且易用的运行时 Wasm 生成工具,依然是其广泛应用的主要障碍。未来的工作将专注于完善 PPU 模拟,并探索更深层的优化,以进一步挖掘这一 JIT 策略的潜力。
由于苹果对 iOS 上的 JIT 编译进行了限制,诸如 Dolphin 等高性能模拟器通常无法使用。本篇博客探讨了一种替代方案:“JIT-to-Wasm”。该技术通过在运行时生成 WebAssembly (Wasm) 字节码来绕过上述限制,随后由浏览器引擎将其编译为原生机器码。
作者开发了一款名为“WATaBoy”的 Game Boy 模拟器作为概念验证,用于对比该方法与传统解释器的性能。该实现依赖 `wasm-encoder` 来生成字节码,并利用 C ABI 在 Rust 和 JavaScript 之间传递数据。由于 Wasm 采用哈佛架构,作者使用了“后期链接”(late-linking)流程:即由浏览器实例化新的 Wasm 模块,将其添加到主实例的间接函数表中,并通过 `call_indirect` 执行。
尽管 JIT-to-Wasm 方法在性能上优于解释器,但作者指出,它仍缺乏专业模拟器所使用的底层优化(如硬件快速内存访问)。此外,缺乏稳健且易用的运行时 Wasm 生成工具,依然是其广泛应用的主要障碍。未来的工作将专注于完善 PPU 模拟,并探索更深层的优化,以进一步挖掘这一 JIT 策略的潜力。
请启用 JavaScript 和 Cookie 以继续。
抱歉。
 Rocket Lab 已宣布达成最终协议,将以约 80 亿美元的现金加股票交易方式收购 Iridium Communications。该交易预计于 2027 年年中完成,届时将把 Rocket Lab 的发射与卫星制造能力,与 Iridium 的全球卫星网络及 L 波段频谱进行整合。
通过整合这些业务,Rocket Lab 旨在成为一家具备端到端能力的垂直一体化太空公司,能够自行设计、发射并运营卫星星座。此次收购使公司能够立即立足于高增长的卫星服务市场,包括物联网(IoT)、直接连接设备(D2D)连接,以及关键导航与安全服务。
从财务角度来看,该交易预计将带来增值,凭借 Iridium 超过 255 万活跃用户的基数,为 Rocket Lab 提供可观的经常性收入和稳定的现金流。合并后的公司计划利用这一合作关系,加速下一代卫星星座的开发,加强国家安全与防御能力,并拓展至未开发的商业市场。双方董事会已一致批准该交易,目前仍有待股东及监管机构的批准。
Rocket Lab 已宣布达成最终协议,将以约 80 亿美元的现金加股票交易方式收购 Iridium Communications。该交易预计于 2027 年年中完成,届时将把 Rocket Lab 的发射与卫星制造能力,与 Iridium 的全球卫星网络及 L 波段频谱进行整合。
通过整合这些业务,Rocket Lab 旨在成为一家具备端到端能力的垂直一体化太空公司,能够自行设计、发射并运营卫星星座。此次收购使公司能够立即立足于高增长的卫星服务市场,包括物联网(IoT)、直接连接设备(D2D)连接,以及关键导航与安全服务。
从财务角度来看,该交易预计将带来增值,凭借 Iridium 超过 255 万活跃用户的基数,为 Rocket Lab 提供可观的经常性收入和稳定的现金流。合并后的公司计划利用这一合作关系,加速下一代卫星星座的开发,加强国家安全与防御能力,并拓展至未开发的商业市场。双方董事会已一致批准该交易,目前仍有待股东及监管机构的批准。
Rocket Lab 对 Iridium 的收购在 Hacker News 上引发了激烈讨论,议题涉及轨道可持续性、市场策略以及航天工业的未来。
支持者认为此举是一次战略胜利,为 Rocket Lab 提供了盈利的基础设施、宝贵的无线电频谱以及全球客户群。通过整合 Iridium 成熟的网络,Rocket Lab 获得了抵御市场波动的重要筹码,使其能够更有效地与 SpaceX 竞争。
然而,讨论中也体现了对“太空垃圾”的深切担忧。批评者认为,低地球轨道(LEO)中卫星密度的增加,提高了碰撞风险和有害大气污染的可能性。一些用户主张征收“轨道价值税”以资助清理工作并监管轨道层,并将当前局势比作“公地悲剧”。
怀疑论者还质疑了此次收购的财务逻辑,指出其沉重的债务负担以及在面对 Starlink 的直连设备技术时的竞争挑战。此外,该讨论帖还探讨了 Rocket Lab 性质的转变——从曾经的新西兰之光,转变为日益融入美国航空航天和情报体系的一员;与此同时,也有人对那些仍在扩大发射能力的航天公司是否拥有高估值展开了辩论。
写过手写 HTML 的开发者:现代前端开发指南 A field guide to the modern front end for developers who hand-wrote HTML
26 天前
网页开发已经从简单的 FTP 上传演变成了一个复杂且工具繁多的生态系统。曾经,开发者只需管理简单的 HTML 文件,如今却要面对令人眼花缭乱的软件包和构建流程。 然而,这种复杂性并非随意产生。每一个工具都是“伤痕”——是针对网络在扩展过程中出现的特定历史问题所提出的解决方案。现代开发技术栈只是二十年来针对真实痛点进行增量式修复后的累积结果。 通过追踪一个 `<button>` 元素在这些工具演变过程中的历程,我们可以揭开当前技术格局的神秘面纱。与其死记硬背各种工具,不如去探寻它们旨在治愈的“创伤”。理解那些促使解决方案产生的根本问题后,你会发现现代开发只不过是同一项基本任务的高级版本:告诉浏览器该做什么。一旦理解了底层的挑战,这座“疯狂的大教堂”就会变成一张清晰、合乎逻辑的地图。
抱歉。
所提供的文本是一个 PDF 文档(1.7 版本)的原始源代码。它包含了定义文件布局的结构化元数据,例如文档目录、资源字典和页面树。 该文档由 32 个独立页面组成,每个页面的媒体框尺寸均为 960x540 像素。元数据表明,这些页面使用了多种资源,包括字体和不同类型的图像处理集(如 ImageB、ImageC 和 ImageI),这表明该文档为演示文稿或幻灯片格式。文本的最后部分显示了一个压缩数据流的开头。总之,这是一个技术文件结构,而非可阅读的内容。
抱歉。