Echoes (Live at Pompeii)
36 分钟前

The Zulip Foundation
38 分钟前
Microscale Thermite Reaction
39 分钟前

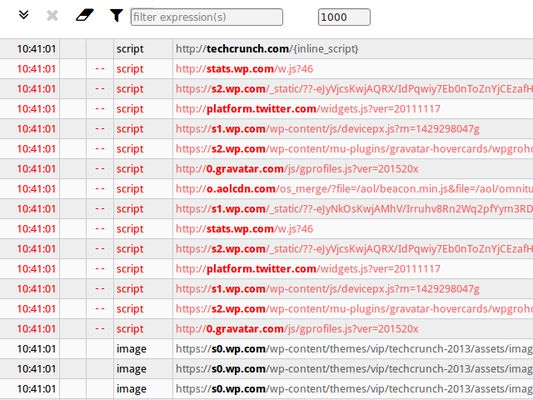



Aperio Lang
3 小时前


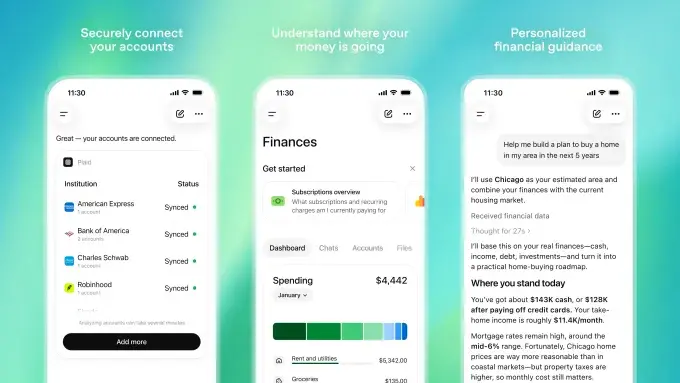

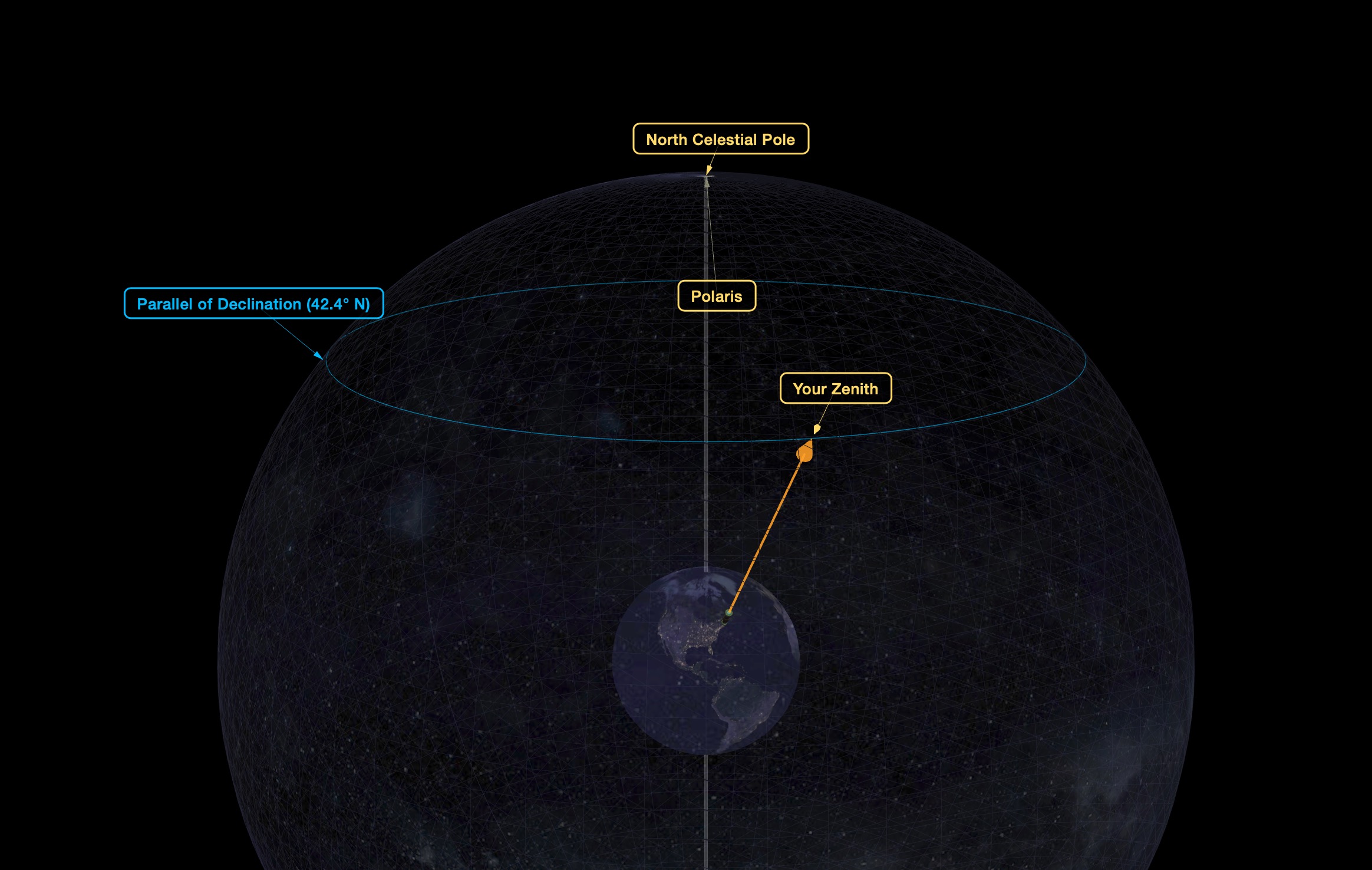

ASCII by Jason Scott
6 小时前