Given a list of 
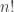
This is an interesting problem, in part because it is easy to get wrong. The standard, all-the-cool-kids-know-it response is the Fisher-Yates shuffle, consisting of a sequence of 
def fisher_yates_shuffle(a):
"""Shuffle list a[0..n-1] of n elements."""
for i in range(len(a) - 1, 0, -1): # i from n-1 downto 1
j = random.randint(0, i) # inclusive
a[i], a[j] = a[j], a[i]
Note that the loop index i decreases from
def forward_shuffle(a):
"Shuffle list a[0..n-1] of n elements."""
for i in range(1, len(a)): # i from 1 to n-1
j = random.randint(0, i) # inclusive
a[i], a[j] = a[j], a[i]
It’s worth emphasizing that this is different from what seems to be the usual “forward” version of the algorithm (e.g., this “equivalent version”), that seems to consistently insist on also “mirroring” the ranges of the random draws, so that they are decreasing with each loop iteration instead of the loop index:
def mirror_shuffle(a):
"Shuffle list a[0..n-1] of n elements."""
for i in range(0, len(a) - 1): # i from 0 to n-2
j = random.randint(i, len(a) - 1) # inclusive
a[i], a[j] = a[j], a[i]
There are a couple of ways to see and/or prove that forward_shuffle does indeed yield a uniform distribution on all possible permutations. One is by induction– the rather nice loop invariant is that, after each iteration i, the sublist a[0..i] is a uniformly random permutation of the original sublist a[0..i]. (Contrast this with the normal Fisher-Yates shuffle, where after each iteration indexed by i, the “suffix” sublist a[i..n-1] is essentially a uniformly permuted reservoir-sampled subset of the entire original list.)
Another way to see that forward_shuffle works as desired is to relate its behavior to that of the original fisher_yates_shuffle, which has already been proved correct. Consider the set of independent discrete random variables 


random.randint(0, i).
Imagine generating the entire set of those 
forward_shuffle applies the same set of random transpositions, but in reverse order. Thus, the permutations resulting from fisher_yates_shuffle and forward_shuffle are inverses of each other… and if a random permutation is uniformly distributed, then so is its inverse.
There is nothing special here– indeed, this forward_shuffle is really just a less dressed-up implementation of what is usually referred to as the “inside-out” version of Fisher-Yates, that for some reason seems to be presented as only appropriate when shuffling a list generated from an external source (possibly of unknown length):
def forward_shuffle(source):
"Return shuffled list from external source."""
a = []
for i, x in enumerate(source):
a.append(x)
j = random.randint(0, i) # inclusive
a[i], a[j] = a[j], a[i]
return a
I say “less dressed-up” because I’ve skipped what seems to be the usual special case j==i comparison that would eliminate the swapping. The above seems simpler to me, and I would be curious to know if these (branchless) swaps are really less efficient in practice.