A long time ago, I spent a few years working on garbage collection in the J9 Java VM. And even though I’ve since done mostly done higher-level stuff, having a deeper knowledge of GC has continued to come in useful.
Yesterday, it was an insight from one of my favourite GC papers, A Unified Theory of Garbage Collection, which helped me solve a tricky problem.
ohm’s incremental parsing
I’m working with a team that’s using Ohm to parse text documents and render a rich text version in ProseMirror. The goal is bidirectional updates: changes in ProseMirror should propagate to the text version, and vice versa.
Ohm supports incremental parsing, which means that if you parse some text and then make a small edit, it can quickly reparse by reusing portions of the previous result.
It also supports limited form of incremental transforms. You can define an attribute, which is kind of like a memoized visitor, and the attribute value for a given node will only need to be recalculated if the edit affected one of its subtrees. So you can easily implement a form of persistent data structure, where each new value (e.g., an AST) shares a bunch of structure with the previous one.
the problem
Using this machinery, I tried making an pmNodes attribute that produced a ProseMirror document for a given input. When the text document is edited, it produces a new tree which shares a bunch of nodes with the previous one.
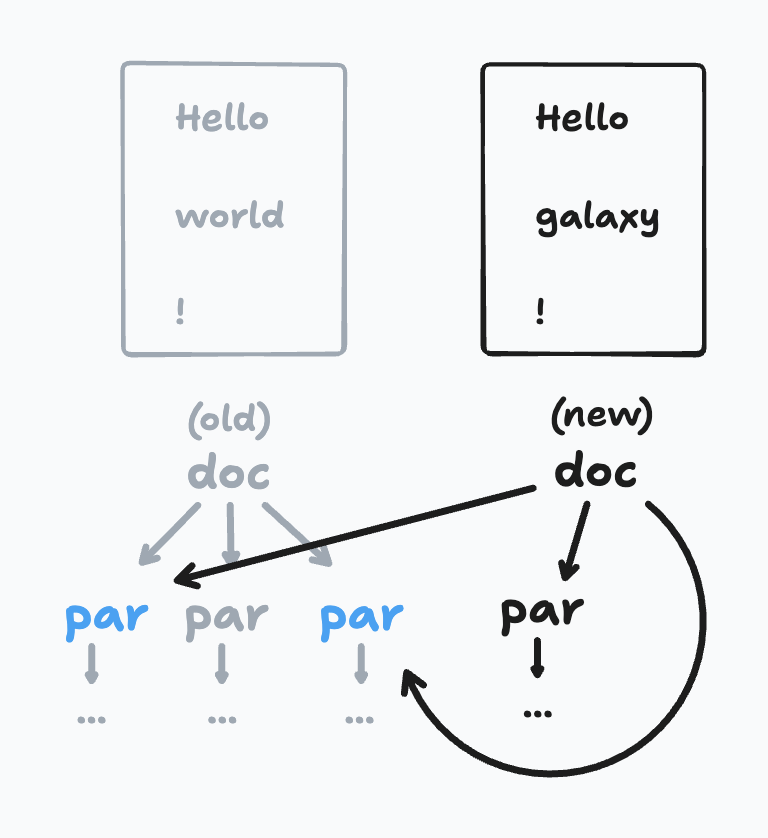
Then, my plan was to construct a ProseMirror transaction that would turn the old tree into the new one. To do that, it’s helpful to know which nodes appeared in the old document, but not the new one.
My first implementation of this was equivalent to tracing garbage collection — after each edit, I walked the entire document, and recorded all the nodes in a Set. The difference between the sets told me which nodes had died.
But this kind of defeats the purpose of incrementality — if you have a long document and make a small edit, we should be able to process without visiting every node in the document.
the solution
Then I remembered A Unified Theory of Garbage Collection, a 2004 OOPSLA paper by some former colleagues of mine:
Tracing and reference counting are uniformly viewed as being fundamentally different approaches to garbage collection that possess very distinct performance properties. We have implemented high-performance collectors of both types, and in the process observed that the more we optimized them, the more similarly they behaved — that they seem to share some deep structure.
We present a formulation of the two algorithms that shows that they are in fact duals of each other. Intuitively, the difference is that tracing operates on live objects, or “matter”, while reference counting operates on dead objects, or “anti-matter”. For every operation performed by the tracing collector, there is a precisely corresponding anti-operation performed by the reference counting collector.
This was the answer I needed! Rather than visiting all the live objects, I wanted to only visit the dead ones, and reference counting would let me do that.
So I added a way of maintaining a reference count for all the nodes in the doc. When we produce a new document, we decrement the reference count of the old root node (it will always be 0 afterwards). So we recursively decrement the ref count of its children, and so on. This gives me exactly what I wanted — a way to find all the nodes that were not reused, without having to visit most of the nodes in the doc.