👋 Hi, I’m Eric. I work on systems and product at Modal.
We recently launched Modal Notebooks, a new cloud Jupyter notebook that boots GPUs and arbitrary custom images in seconds, all with real-time collaboration.
I want to share some of the engineering that made this experience possible. This post isn’t about features, but about the systems work behind running interactive, high-performance GPU workloads in the cloud while still feeling instantaneous.
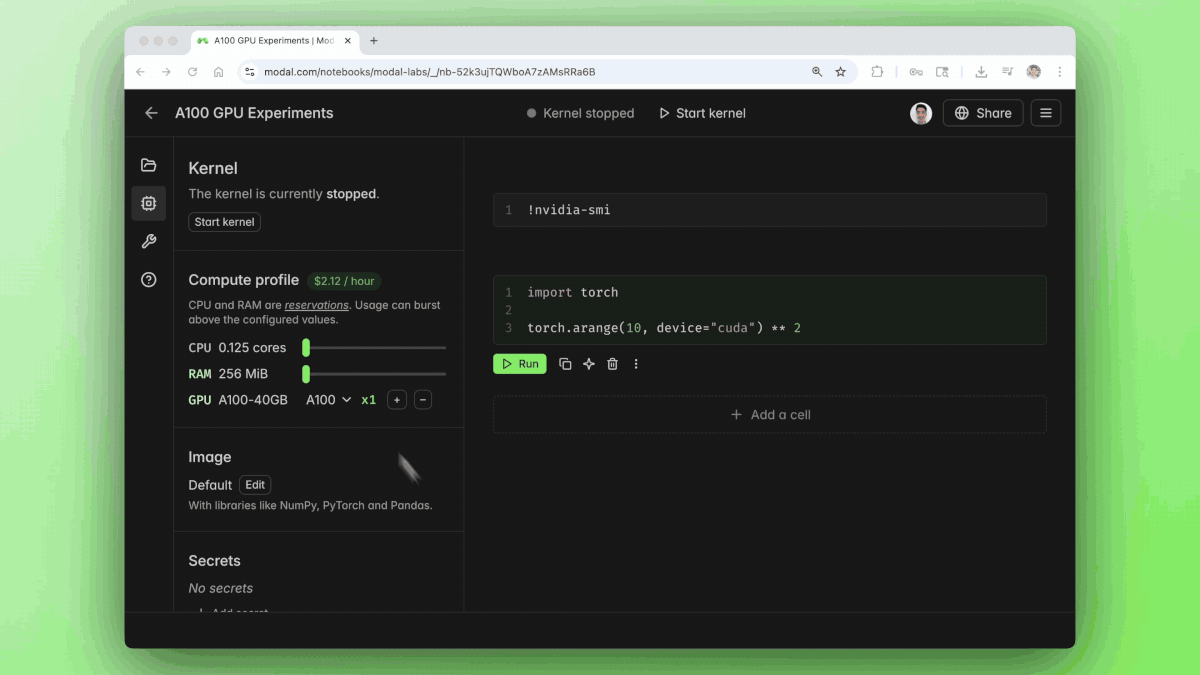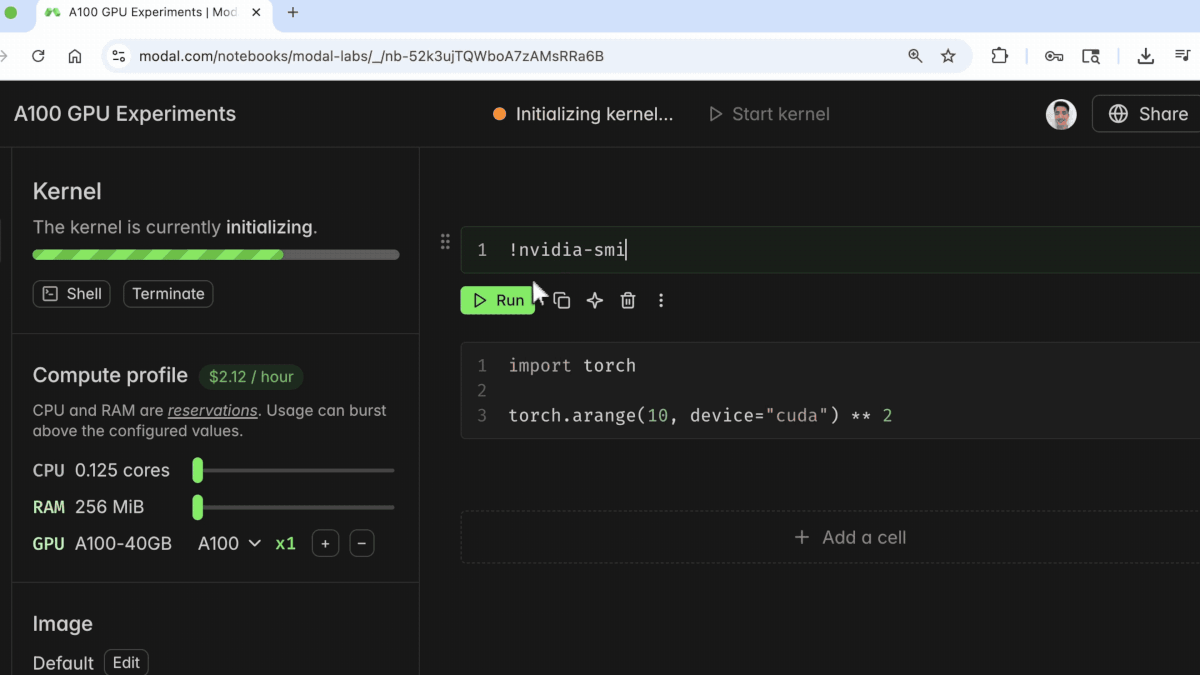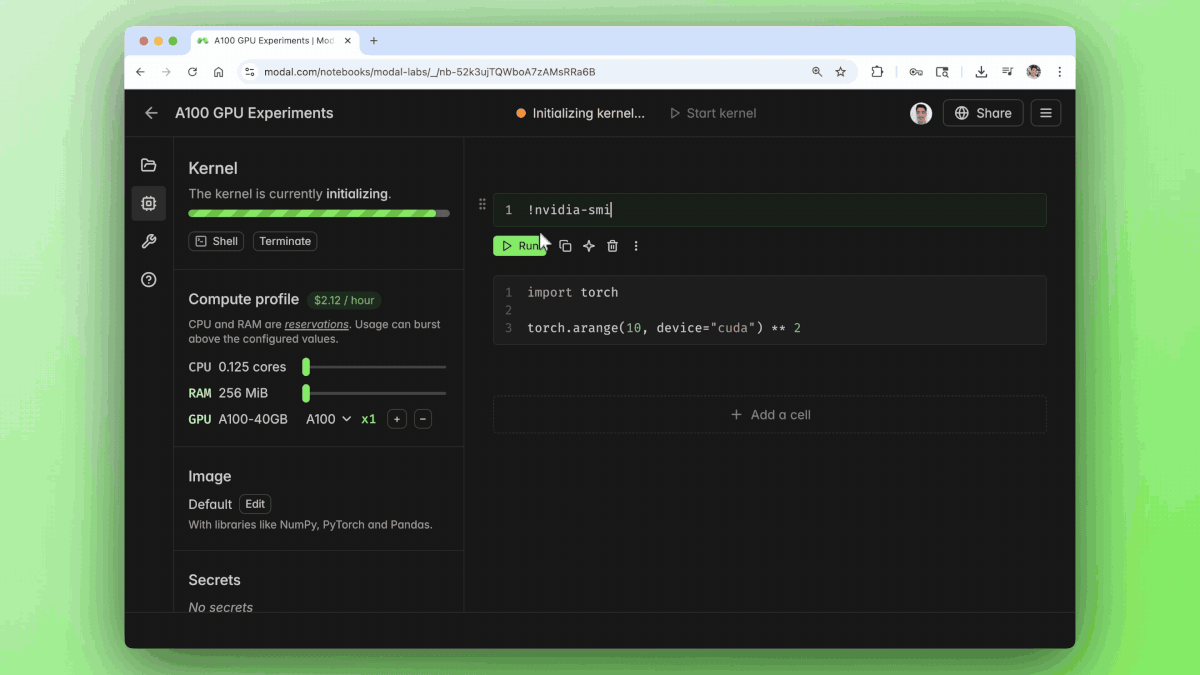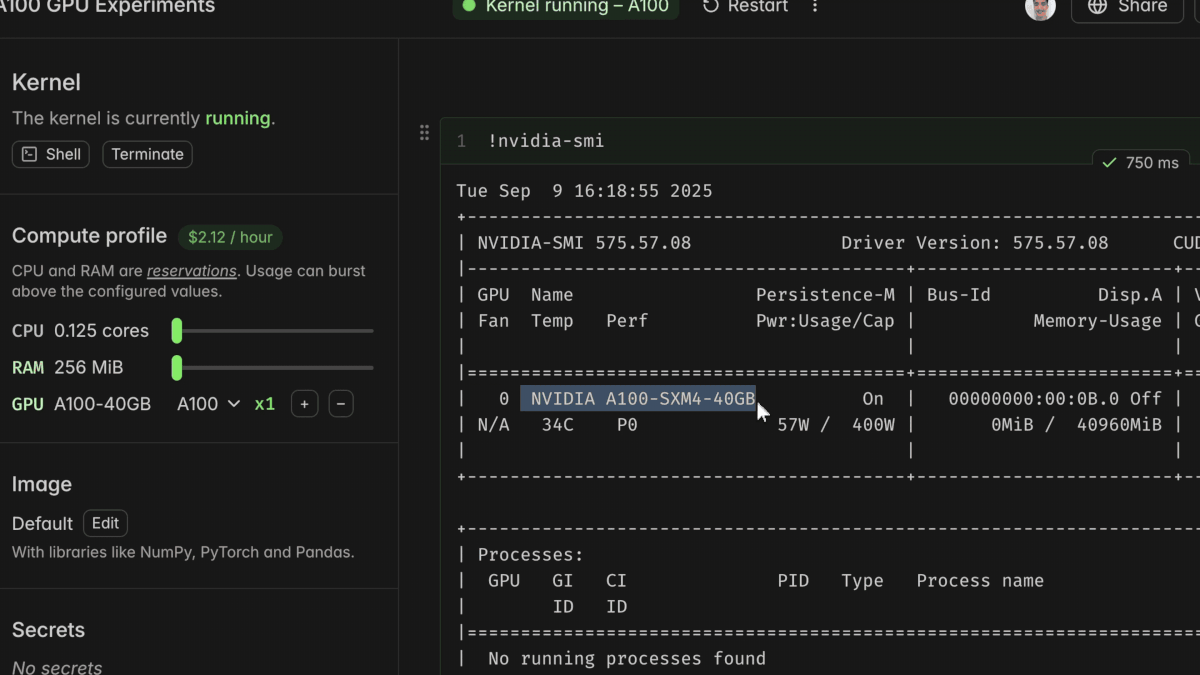
Notebooks began as a small experiment: could we build a hosted, collaborative notebook without sacrificing local speed? Most supercomputing workflows today involve forwarding a Jupyter server on a large, expensive devbox that has to stay warm (plus Slurm for batch runs). We wanted something better—a modern editor that combines collaboration with Modal’s primitives like persistent storage, custom images, and instant access to GPUs.
“Modal Notebooks have been incredible for sharing ML research across Suno. Engineers and designers can start playing with cutting-edge models within minutes after training runs are completed.”
— Victor Tao, ML Research Engineer
In this post I’ll walk through how we did it, from the runtime (sandboxes, image loading, kernel protocol) to the collaboration layer, and finally the editor surface.
Modal Sandboxes for stateful backends
It all begins with kernels.
At the heart of every Jupyter notebook is the kernel protocol, the language that you “speak” to the IPython kernel process to run code. It may look complicated at first, but the idea is simple: send a code cell in, get back the result, plus streams of stdout, stderr, and rich outputs.
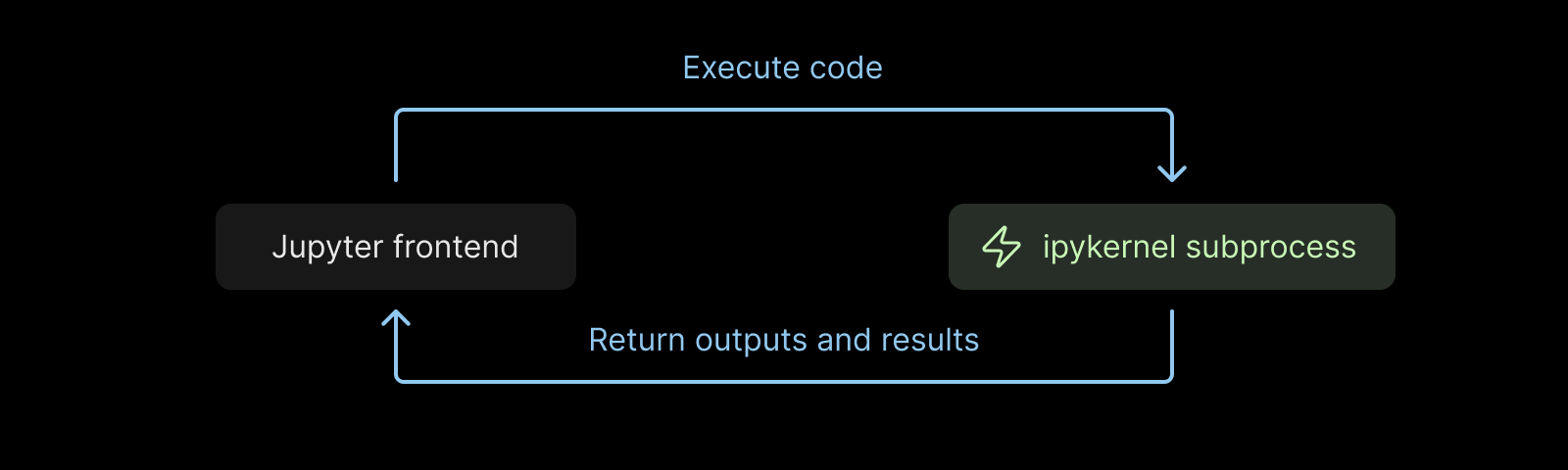
In the standard setup, Jupyter runs on a single backend machine with a one-to-one link to the web editor. Running it reliably in a collaborative, multi-tenant cloud GPU environment required us to rethink that model.
To start with the compute layer, kernels run inside Modal Sandboxes: our abstraction for secure, isolated processes with their own filesystem, resources, and lifecycle. They’re a low-level API that can start containers around the world in seconds.
Compared to other sandbox systems (Cloudflare, Vercel, e2b), Modal Sandboxes are a little bit different: they’re built to support high-performance workloads with hundreds of CPUs, top-tier Nvidia GPUs, gigabytes of disk, and a lazy-loading content-addressed FUSE filesystem. This means that Modal Sandboxes can run AI workloads.
(Modal Sandboxes aren’t just for us; they’re a primitive we want others to use. For example, they’re how Lovable runs AI developer environments. And Marimo built their Molab cloud product on top of Sandboxes as well, a very different notebook experience from Modal’s own, which shows how Sandboxes can power many kinds of interactive computing.)
To bridge the gap between the kernel and the outside world, we wrote a daemon called modal-kernelshim that sits inside each Sandbox. It translates Jupyter protocol messages over ZeroMQ into HTTP calls tunneled through our control plane. This lets us handle cell execution, interrupts, and shutdown in a way that looks like a local Jupyter kernel, but much simplified.
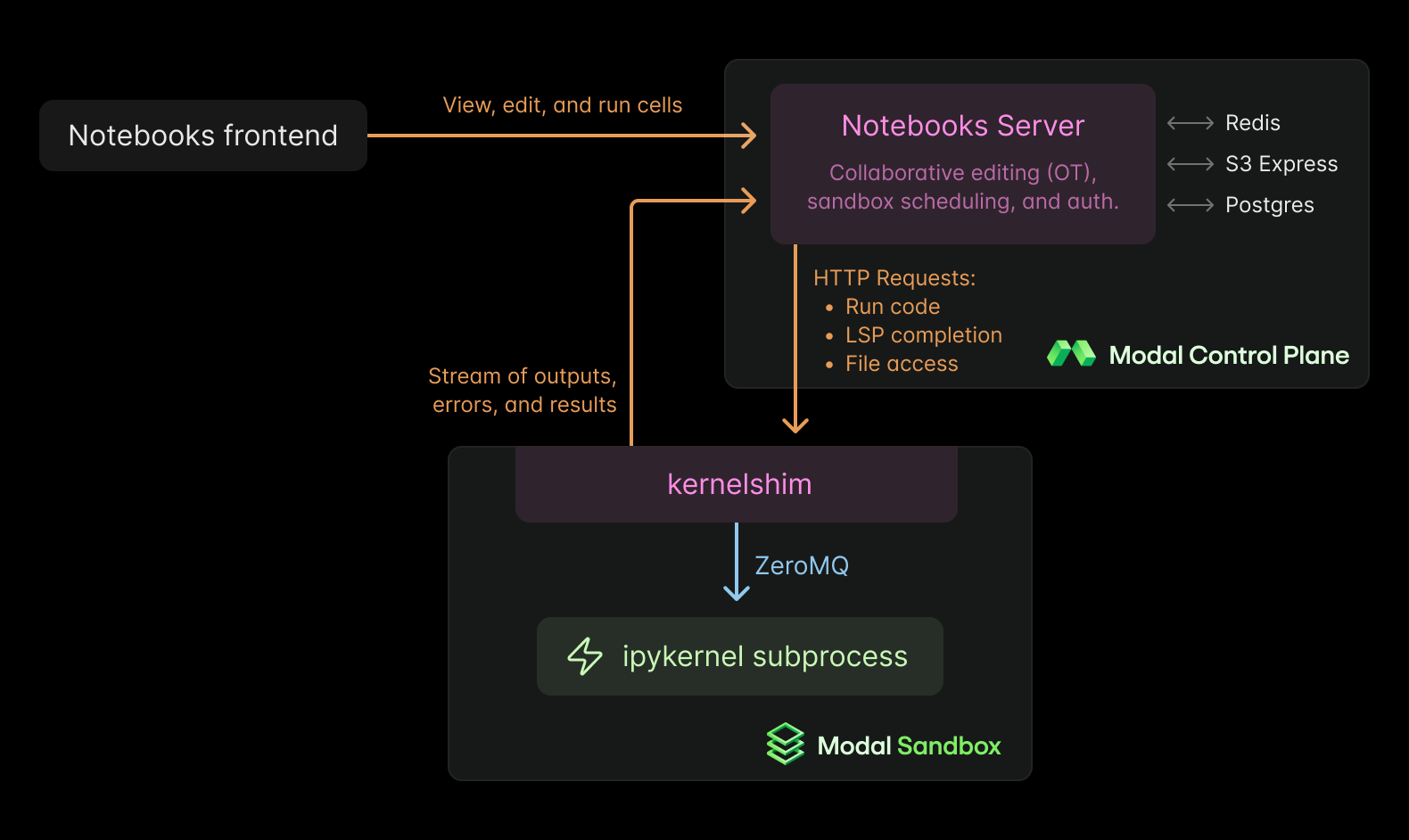
From the user’s perspective, you see streaming outputs appear in your browser as soon as your code runs. Behind the scenes, those outputs are sent over TLS from the Sandbox back to the frontend through a server component.
That architecture (shim → server → frontend) is how we expose instantaneous, remote access to kernels, while providing a modern interface that multiple users can connect to.
Instant, distributed container infrastructure
For the past 4 years, we’ve been quietly building a lot of distributed systems and core infrastructure to power our container runtime. I wanted to share some of this work here, since it’s ultimately the low-level systems that make Notebooks tick.
Lazy-loading container images
One of the biggest sources of latency in starting containers is unpacking images. In Docker or Kubernetes, bringing up an 8 GB Python/ML image means downloading and decompressing layers before you can run anything — often close to a minute.
That’s fine for long-lived services, but it kills the feedback loop in an interactive notebook.
Our solution was to build a lazy-loading container filesystem. Instead of pulling in every file upfront, we load only a lightweight metadata index and mount it through a Rust FUSE server. The actual file contents are fetched on demand, the moment your process touches them.
Those reads flow through a content-addressed tiered cache: memory page cache, local SSD, zonal cache servers, regional CDN, and finally blob storage. Most accesses hit one of the fast tiers; when they don’t, we stream only the files you actually need, often at speeds that can saturate the hardware.
This file system and its associated container runtime are actually the first things I built when I joined Modal as a founding engineer: the very first lines of Rust at the company. It started as an experiment to improve benchmarks, and it’s now the foundation that makes fast container startup possible, from notebooks to production AI inference.
Scheduling and capacity
Running notebooks efficiently isn’t just about fast container startup — it’s about how those containers are placed. At Modal, notebooks share the same pool as our functions, backed by thousands of CPUs and GPUs. The scheduler balances workloads across this pool, so whether you start small with 0.125 CPUs or scale up to multiple H100s or B200s, your container still gets placed instantly if there’s capacity.
We’ve previously written about how we scale our fleet automatically to match demand, spanning clouds and optimizing for price.
Notebooks add another wrinkle: kernels are often idle. Leaving a giant GPU instance running idle is a fast way to burn money. Our solution is to pause them automatically; and when you come back, they start up again in seconds. You get the experience of a persistent machine without the overhead of keeping one alive.
Volumes
Modern AI workloads revolve around data. Training is data in, weights out. Inference pipelines move checkpoints, embeddings, and outputs through a chain of steps. None of this works without persistent storage — and in a serverless world, where capacity shifts across regions and hardware, persistence is what keeps workloads coherent. To make Notebooks viable, we needed a storage system that was global, mutable, and fast.
That’s what VolumeFS provides, the backbone of Modal Volumes. It’s a FUSE filesystem designed for global access, built on a distributed network storing petabytes of data.
Honestly, there’s too many components to describe VolumeFS in this blog post. But suffice it to say that it’s a core piece of infrastructure at Modal that allows the platform to come together. The quick summary is that file trees live in Spanner, operations are written to be eventually consistent, and we reuse our distributed content-addressed CDN. We look forward to discussing the internals of Modal Volumes later on.
Like any good system, users never have to think about this! The result is that files feel local, but behave globally. You can spin up compute anywhere in the world and still have your data.
Real-time collaboration
Notebooks are social by nature. They’re not just for running code, but for exploring ideas together and leaving behind a literate record. So we need real-time collaborative editing.
For this piece, we leaned on Rushlight, a small library I open-sourced a couple years ago when I was experimenting with operational transformation in CodeMirror 6. Back then, I wanted a simpler, self-hosted collaboration layer. Light and robust, with real-time storage and automatic compaction in your own database.
Every edit flows through Redis Streams, where it’s broadcast to other clients. The OT layer ensures changes converge, even with several people typing at once. On the frontend, CodeMirror handles presence and multiple cursors.
We separate editing state from execution state. When you run a cell, outputs stream back inline in real time, but anyone reconnecting later can always refetch the current state from the backend. Larger results—plots, videos, model outputs—are pushed into S3 Express One Zone so the editing stream stays fast, while outputs are still durable and retrievable.
Some teams asked to share notebooks with stakeholders outside their Modal organization, so we added link-based sharing and allowed for embedding Jupyter Widgets to add interactivity. That way a notebook isn’t just a scratchpad—it can double as a lightweight demo surface. We implemented the widget protocol on Modal Notebooks. To our knowledge, this is the first working implementation of widgets in a real-time collaborative editing environment!
Editor features: LSP and AI completion
In 2025, editors need to be smart. Jupyter has historically lagged on developer ergonomics — completions, inline docs, and semantic highlighting never quite worked out of the box. For Modal Notebooks, we wanted those capabilities to be native.
We started by implementing core pieces of the Language Server Protocol (textDocument/completions, textDocument/hover, textDocument/semanticTokens/full) and wiring them up to Pyright. This nets you completions, documentation, and semantic highlighting. We open-sourced some of this implementation.
We also integrated auto-formatting with Ruff, running its bleeding-edge WebAssembly build directly in our frontend.
On the AI side, we experimented with edit prediction. Currently we use Claude 4 for next-edit suggestions. We’ve also tried pushing it further by hosting inference on Modal itself. That version runs Zed’s Zeta model on H100 GPUs, serving completions directly from our own cloud infra. It still needs some UI tweaks before we enable it as a default though.
I think we’ve really made something that actually feels like a first-class development environment, with modern editor features alongside GPU-backed execution.
Conclusion
We’ve been thinking about foundational infrastructure at Modal for years now, with systems goals at heart: speed, performance, efficiency, and ease of use. Each layer has built on the last. Modal Notebooks is the culmination of a lot of work across file systems, OS, distributed systems, scheduling, security, sandboxes, isolation, and more.
Admittedly, although we’ve invested in web interfaces and observability, Modal has never been web-first. Our starting point has always been the SDK, because we bet on programmers. But SDKs aren’t the right choice for all work, and this product is our first foray into a surface area that extends beyond the client library, our first “new product” separate from the rest.
This work began as a solo prototype and grew into a small team effort. Contributors include:
And thanks especially to our design partners at world-class companies like Suno, who’ve been using Notebooks since the very beginning.
Try notebooks