You run a program. It reads and writes addresses as if a giant, continuous slab of memory had been waiting there all along. It didn’t. Linux builds that illusion on the fly, one page at a time. This is a walk through what your process actually owns, what happens on the first touch of a byte, how protections and huge pages fit in, how to see the truth from /proc, and why modern kernels do a little extra dance to defend against Meltdown.
Note: This tour targets Linux on x86‑64, other architectures differ in details (page sizes, cache rules), but the ideas carry over.
Intro
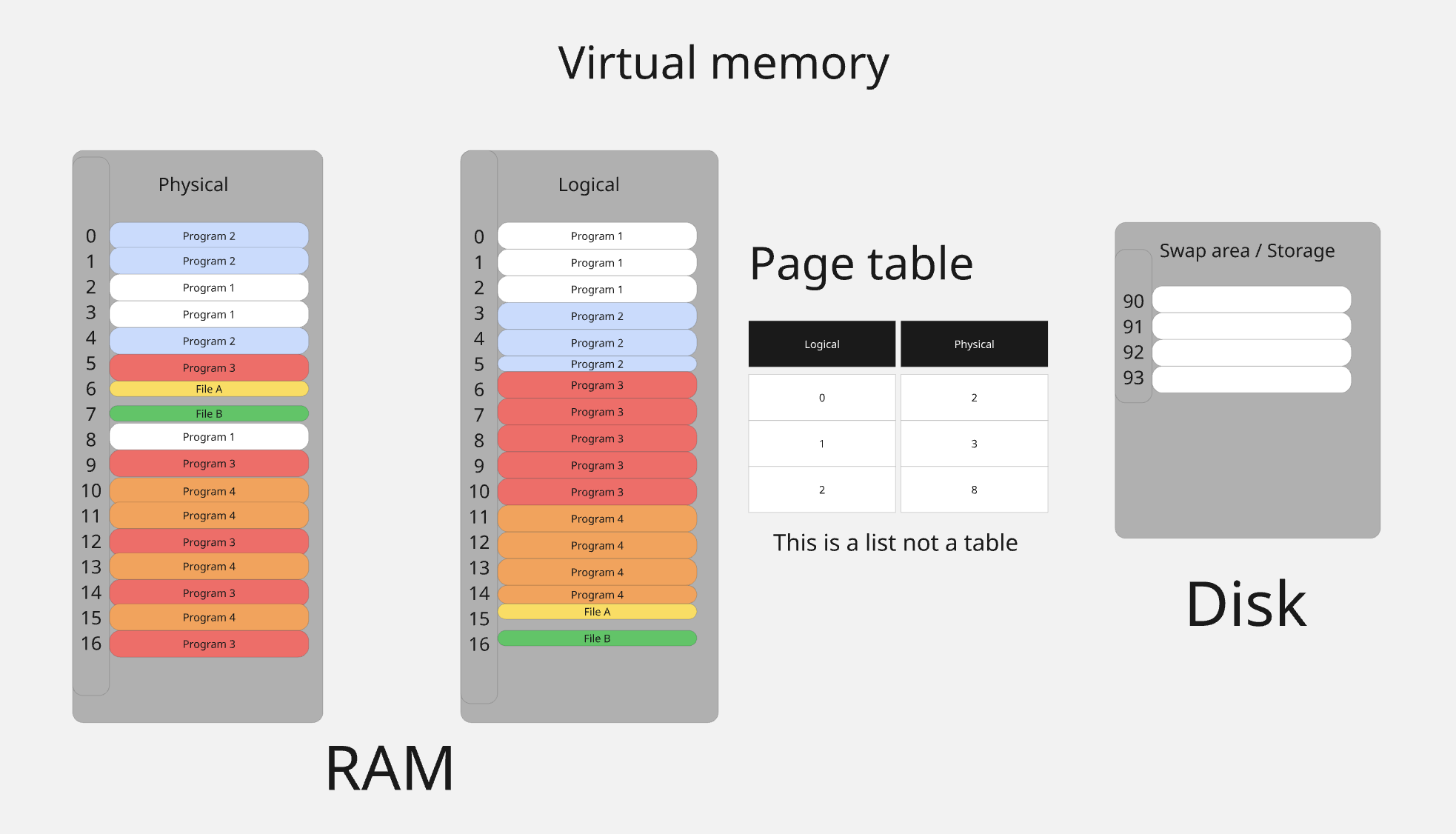
The picture below is a quick introduction. It is a simple map you can keep in mind as you read.
Physical RAM is the real memory. It is a bunch of frames scattered around. The virtual view is the clean line your program sees. It does not match the real layout. The page table is a list. It tells which spot on the virtual line points to which frame in RAM. Disk is extra space the system can use when RAM is full.
Here is how it plays out. When you read or write, the CPU looks in the page table. If there is an entry it goes to that frame. If there is no entry you get a page fault. The system then fills a frame and adds the entry, or it stops you with an error. We will explain faults later.
When RAM is tight the system makes room. It moves pages you have not used in a while to disk, or drops file pages it can load again. If you touch one of those later it brings it back.

Tiny explainers appear throughout so anyone can follow along, regardless of background.
Tiny explainer:
/proc/procis a virtual filesystem the kernel builds in memory. It exposes process and kernel state as files. You can read them with normal tools likecat.
The floor plan you never see
Inside the kernel, your process owns one object that represents its whole address space. Think of it as a floor plan. Each room on that plan is a virtual memory area (VMA) a contiguous range with the same permissions (read, write, execute) and the same kind of backing (anonymous memory or a file).
Tiny explainer: VMA
A VMA is a continuous virtual address range with one set of rights and one kind of backing.
Under the plan sit the page tables that the hardware reads to translate your virtual addresses to real page frames.
Tiny explainer: page tables and PTE
Page tables are lookup structures the CPU walks to translate addresses. A page table entry (PTE) maps one virtual page to one physical page and holds bits like present and writable.
All threads in the process share the same plan. When the scheduler runs you, the CPU is pointed at your page tables, so pointer dereferences don’t need a syscall once a mapping exists, the hardware does the translation on its own.
You change the plan in three ways: mmap draws a room, mprotect changes the sign on its door (R/W/X), and munmap tears it down.
Tiny explainer:
mmapmmapreserves a virtual range with given permissions and a backing source.
Tiny explainer:mprotectmprotectchanges the permissions on an existing range.
Tiny explainer:munmapmunmapremoves a mapping from the address space.
Everything else (creating pages, reading file data, swapping) happens lazily when you touch memory.
Tiny explainer: page
Hardware manages memory in fixed chunks called pages. On many x86‑64 machines a base page is 4 KiB. Bigger pages exist at 2 MiB and 1 GiB.
A quick glance at your own house
Run:cat /proc/self/maps | sed -n '1,80p'
You’ll see your main binary’s segments (code, data, bss), the heap, anonymous mappings (allocators use these for big chunks), shared libraries, and thread stacks near the top.
You’ll typically also see two small regions:
[vdso]: a tiny shared object the kernel maps in so a few calls likegettimeofdaycan run without a kernel trap.[vvar]: read‑only data those helpers use.
Tiny explainer:
vdsoandvvarvdsois code the kernel maps into your process to make some syscalls fast.vvarholds data that code reads.
They’re why asking the time is fast.
mmap, without the fog
When you call mmap, you’re not “allocating memory” so much as drawing a promise on the floor plan. You say give me a range of addresses with these rights and back it by this file plus offset or by anonymous memory. Linux picks an address, makes sure it doesn’t collide, adjusts VMAs so each remains uniform, and records the promise.
Tiny explainer: ASLR
Address Space Layout Randomization places mappings at randomized locations to make exploits harder.
Tiny explainer: anonymous vs file mapping
Anonymous memory is not tied to a file and starts as zeros. File mappings mirror file contents.
It does not allocate pages yet. That comes later at first touch.
Two gotchas come up over and over:
- File mappings:
offsetmust be page aligned ormmapreturnsEINVAL. - Mapping past end of file is allowed, but touching beyond the true end raises
SIGBUS. The VMA exists, the data does not.
Tiny explainer:
MAP_PRIVATEandMAP_SHAREDMAP_SHAREDmeans writes go back to the file and are visible to others that share it.MAP_PRIVATEmeans you see the file but writes go to private copy‑on‑write pages.
Anonymous mappings start life as zeroes. File mappings mirror the file. If the file ends mid page the tail of that last page reads as zeros but still belongs to the file.
MAP_FIXED means exactly here and it overwrites anything already mapped at that address. Prefer MAP_FIXED_NOREPLACE to fail instead of clobbering. Without either flag your addr is just a hint.
Tiny explainer:
MAP_FIXED_NOREPLACE
Ask for an exact address and fail if something is already there. Safer than overwriting.
The first touch
Imagine *p = 42; to a fresh mapping. The CPU tries to translate the address. It finds no entry so it raises a page fault that includes the address and an error code.
Tiny explainer: page fault
A page fault is the CPU asking the kernel to handle a missing or illegal translation for an address.
The kernel’s handler runs on your behalf and asks three questions in this order:
- Is the address inside any VMA
If not you are poking a hole in the plan →SIGSEGV. - Do the rights allow this access
Write to a read only page or execute from non exec →SIGSEGV. - If it is valid but missing make it real
For an anonymous mapping the kernel allocates a zero filled physical page, wires a page table entry with your requested permissions, and returns to your instruction. For a file mapping it first checks the page cache. If the data is not in RAM it reads from storage, then installs the translation and retries your instruction. Your store lands. You keep going.
Tiny explainer: page cache
The page cache is the kernel’s cache of file data in RAM. File mappings read and write through it.
Tiny explainer: zero page
Some reads from fresh anonymous memory can be satisfied by a shared read only page of zeros. A private page is created on the first write.
People count these faults:
- A minor fault means the data was already in RAM and only the translation was missing.
- A major fault means the kernel had to wait for I/O which is expensive.
Tiny explainer: stack guard
User stacks have a guard page. Touching just below the current stack can grow it. Touching far below looks like a bug and gets aSIGSEGV.
This same lazy first touch explains how memory is shared after fork() and how MAP_PRIVATE works. The next section shows that path.
Copy on write with fork() and MAP_PRIVATE
Why this is here. We just talked about first touch. The same rule explains why pages do not copy on fork and why MAP_PRIVATE does not change the file.
fork does not duplicate pages. The child points at the same physical pages as the parent. The kernel flips those pages to read only for both. The first write hits a copy on write fault. The kernel allocates a new page, copies the bytes, updates the writer’s page table entry to the new page with write permission, and returns. Reads still share the original page. That is why RSS stays flat after fork until you write.
Tiny explainer: RSS
Resident Set Size is how many pages of this process are currently in RAM. Tiny explainer: copy on write
Share the same page for reads. Make a private copy only when a write happens.
MAP_PRIVATE uses the same idea. You read file data through the page cache. When you write, the kernel gives you a private page. The file stays unchanged.
Things you will also run into:
forkthenexecve. The child replaces its whole address space soon after. That avoids most CoW work.vfork. The child runs in the parent’s address space until it callsexecor_exit. The parent waits. Do not touch memory in the child.clonewithCLONE_VM. This makes a thread. One address space. No copy.MAP_SHARED. Writes go to the shared page and to the file or shmem. No CoW.MADV_DONTFORK. Leave this mapping out of the child.MADV_WIPEONFORK. The child sees zeros for this mapping.- Transparent huge pages. Breaking CoW on a huge page may split it first. Small extra cost.
Changing rights, and the little pause you feel
Why you care. JITs and loaders flip a region from writable to executable after codegen which is W^X. That flip is not free.
Tiny explainer: W^X
Write xor Execute is a policy. A page is never writable and executable at the same time.
mprotect(addr, len, prot) changes permissions. Internally the kernel may split VMAs so each remains uniform, edits the page table entries for the range, and then does one more necessary thing. It invalidates old translations from the CPU’s small cache of address translations which is the TLB. That invalidation is the small pause you sometimes feel when a JIT flips RW to RX or back.
Tiny explainer: TLB
The Translation Lookaside Buffer caches recent translations so the CPU does not walk page tables every time.
Most systems enforce W^X. A page should not be writable and executable at the same time. JITs keep to that by flipping after codegen or by keeping two virtual mappings of the same memory so no single mapping is both.
Remember there are two layers of permission checks:
- Filesystem or mount policy like
noexec - Page permissions like
PROT_EXEC
Either layer can block execution.
Seeing what’s really mapped
For everyday questions the friendly view is enough.
/proc/<pid>/mapsshapes: addresses, rights, file names/proc/<pid>/smapsandsmaps_rollupadd per region accounting like how much is resident which is RSS, private vs shared, and whether huge pages were used likeAnonHugePagesandFilePmdMapped
When you need truth at the per page level Linux exposes sharper tools.
/proc/<pid>/pagemap has one 64 bit entry per virtual page. It tells you whether a page is present, swapped, soft dirty, exclusively mapped with caveats for huge pages, whether it is write protected via userfaultfd, or part of a guard region. It can also reveal the page frame number which is PFN but modern kernels hide PFNs from unprivileged users. You need the right capability or root.
Tiny explainer: PFN
Page Frame Number is the physical page index used inside the kernel. Tiny explainer: userfaultfd
A file descriptor that lets a userspace thread handle faults and write protect events for a range.
/proc/kpagecount is indexed by PFN and tells you how many mappings point at a given physical page.
/proc/kpageflags is also indexed by PFN and tells you what kind of page it is and what is happening to it like anonymous or file backed, part of a transparent huge page, in the LRU, dirty, under writeback, a page table page, or the shared zero page.
Common wrinkles
- Sparse files. To tell hole vs data, combine
mincore()which says resident or not withlseek(..., SEEK_DATA/SEEK_HOLE)on the backing file. - Shared memory and swap. Shared and shmem pages may be non present at the PTE level while still logically allocated. Expect swap entries and non present PTEs.
- Privileges. Modern kernels restrict PFN and some flag visibility to privileged users for security.
Tiny explainer:
mincoremincoretells you which pages of a mapping are in RAM.
Tiny explainer:SEEK_DATAandSEEK_HOLE
File offsets that let you skip to the next data chunk or the next hole in a sparse file.
Tiny explainer: soft dirty vs written
Soft dirty marks pages dirtied by userland but it can get lost across swaps or VMA merges. Newer kernels offer an ioctl namedPAGEMAP_SCANthat scans a range for pages written since last write protect and can in the same step write protect them again. It pairs with userfaultfd write protect to give fast and race free userspace dirty tracking for snapshotting and live migration.
When your page suddenly gets bigger
Your CPU would rather cover more ground with fewer entries in its TLB. Linux can help by backing hot memory with bigger pages.
Tiny explainer: THP
Transparent Huge Pages automatically try to use larger pages for performance when safe.
Transparent Huge Pages do this automatically for anonymous memory and shmem or tmpfs. A fault can be satisfied with a 2 MiB page instead of 512 small ones. A background thread named khugepaged can also collapse adjacent base pages into a huge page when it is safe.
Tiny explainer:
khugepaged
A kernel thread that scans and merges adjacent small pages into huge pages when conditions are right.
Modern kernels add multi size THP which is mTHP on some architectures. Groups of base pages like 16 KiB or 64 KiB reduce fault count and TLB pressure without always jumping to 2 MiB. They are still PTE mapped but behave as larger folios inside the VM.
Tiny explainer: mTHP
Multi size THP allows variable order large folios so you get some of the benefit without a full 2 MiB page.
You can ask for THP in a region with madvise(..., MADV_HUGEPAGE) or opt out with MADV_NOHUGEPAGE. System wide behavior lives under /sys/kernel/mm/transparent_hugepage/ with per size controls. enabled can be always, madvise, never, or inherit. Shmem or tmpfs have their own knobs like a huge= mount option with always, advise, within_size, never.
How to tell if it worked. In /proc/self/smaps the lines for a region include AnonHugePages for anonymous THP and FilePmdMapped for file or shmem huge mappings. System wide /proc/meminfo has AnonHugePages, ShmemPmdMapped, and ShmemHugePages. /proc/vmstat keeps a diary of THP events allocated on fault, fell back, split, swapped as a whole, and so on.
Controls plain map:
- Top level:
/sys/kernel/mm/transparent_hugepage/enabledwhich isalwaysormadviseornever - Defrag effort:
/sys/kernel/mm/transparent_hugepage/defragtunes how hard the kernel tries on the fault path vs deferring to khugepaged - Shmem or tmpfs:
huge=always|within_size|advise|neverplus shmem specific knobs
Modern kernels may also create variable order large folios that are bigger than 4 KiB but PTE mapped not full 2 MiB PMD. This reduces fault count and TLB pressure without always jumping to 2 MiB. Behavior differs by kernel and architecture.
One trade off. Assembling a huge page may require compaction which moves other pages to free a contiguous chunk and this can add a small pause. If first touch latency matters more than steady state speed the defrag knob lets you temper how hard the kernel tries which pushes work to khugepaged instead of doing it inline.
Tiny explainer: THP vs hugetlbfs
THP is automatic and pageable. Explicit huge pages fromMAP_HUGETLBor hugetlbfs are quota managed and non swap.
Dirty‑tracking in userspace, without racing the kernel
Imagine you want to copy only the pages an application modified since your last snapshot.
- Give yourself the ability to catch write protect faults with userfaultfd in write protect mode.
- Use
PAGEMAP_SCANover your range with the category written since last write protect. Ask the kernel to write protect matching pages and to return compact ranges of what it found. - Copy those ranges. When the app later writes to one of them userfaultfd wakes your thread. Log the dirtied page, clear write protect, and let it proceed.
This avoids walking every PTE and avoids the classic race where a page is dirtied while you were looking. It is also fast because scan plus write protect happens as one atomic operation inside the kernel.
Tiny explainer:
PAGEMAP_SCAN
An ioctl that scans a virtual range for pages with properties like written since last protect and can also apply write protect in the same step.
The TLB, and why mprotect costs a little
The Translation Lookaside Buffer remembers recent translations so the CPU does not walk page tables on every access. If Linux changes a mapping or its permissions it must make sure stale entries are not used.
On x86 there are two broad ways to do it.
- Precise invalidation. Invalidate one page at a time with
INVLPG. Good for small changes. A single invalidation on a huge page mapping drops the whole 2 MiB entry. - Broader flushes. Drop many or all entries for example by reloading the page table root register. Fewer instructions now and more misses later while refilling.
Which is better depends on how big a change you made, whether you are changing small or huge pages, and the microarchitecture.
Tiny explainer: PCID
Process Context Identifiers tag TLB entries so switching page tables does not flush everything.
Tiny explainer: INVPCID
Allows targeted invalidation of TLB entries for a given tag without switching to it.
There is also a debug knob on some x86 builds named tlb_single_page_flush_ceiling that nudges when the kernel switches from per page invalidations to a broad flush.
Tiny explainer:
INVLPG
A privileged instruction that invalidates TLB entries for the page containing a given address in the current address space tag.
Meltdown, and why the kernel sometimes switches maps on entry
Early 2018 brought Meltdown. Speculative execution plus a cache side channel could leak data across the user and kernel boundary. Even if a user mode load from a kernel address would fault, the CPU might speculatively execute it and touch data that leaves a measurable cache trace.
Linux’s defense on x86‑64 is Page Table Isolation which is PTI. Keep two views and switch between them on entry and exit.
Tiny explainer: CR3
CR3 holds the current page table root and on x86 switching it changes the active address space.
Tiny explainer: PTI
PTI keeps a reduced userspace view without normal kernel data mapped and a full kernel view used while in the kernel.
Cost. More page table switches, different TLB sharing behavior, and a small memory bump for extra top level tables and the per CPU entry area. With PCID Linux keeps separate TLB tags for the two views to reduce flushes. Some systems allow opting out with nopti when acceptable. Default is on.
Tiny explainer: what Meltdown reads
Permissions never turn off. The architectural access still faults. The leak is in transient speculation which leaves a timing trace.
How the kernel changes mappings safely
When Linux edits page tables the order is deliberate.
- Handle cache rules first on architectures that need it.
- Modify page tables by adding, removing, or changing PTEs.
- Invalidate the TLB so the CPU forgets stale translations.
Under the hood are functions that match the granularity of the change like flush an address space, flush a range, or flush a single page.
There is a parallel story for kernel only mappings made with vmap and vmalloc. Before I/O the kernel flushes the vmap range so the physical page sees the latest bytes. After I/O it invalidates the vmap range so speculative reads do not go stale.
Tiny explainer:
vmapandvmalloc
APIs that create kernel virtual mappings to non contiguous physical pages for use inside the kernel.
On x86 you rarely think about the instruction cache because it is coherent with data stores. On others, copying code into executable memory requires an explicit instruction cache flush before running it. The VM has hooks like copy_to_user_page and flush_icache_range where architectures do this housekeeping.
Tiny explainer: icache flush
Some CPUs need an instruction cache sync after writing new code so execution sees the new bytes.
A tiny x86 aside: stacks and calls, without the haze
In 64 bit mode registers wear an R. RIP is the instruction pointer, RSP is the stack, RBP is the frame. The stack grows down. push decrements RSP and stores. pop loads then increments. CALL pushes the return address and jumps. RET pops it into RIP.
On Linux the System V AMD64 ABI passes the first arguments in registers which are RDI, RSI, RDX, RCX, R8, R9 and returns values in RAX. Large objects go by pointer. Your stack must be readable and writable.
Tiny explainer: System V AMD64 ABI
The calling convention for 64 bit Unix like systems on x86‑64 that defines where arguments and return values go.
User code runs in ring 3. The kernel runs in ring 0. Crossings like syscalls, interrupts, and exceptions go through CPU defined gates. In 64 bit mode Linux uses a flat segmentation model and relies on paging for isolation.
Tiny explainer: rings
Rings are CPU privilege levels. Ring 3 is user mode. Ring 0 is kernel mode.
Tiny note for ARM64 readers
The ideas like stack growth and user vs kernel separation are similar. Register names, calling conventions, and syscall entry differ.
When things go sideways (and what that usually means)
mmap→EINVALoften a misaligned fileoffsetwhich must be page aligned or an impossible flag combommap→ENOMEMyou may be out of virtual space or VMA count or you hit strict overcommit- Store to a file mapping →
SIGBUSyou walked past EOF. The VMA existed, the data did not mprotect(PROT_EXEC)→EACCEScould be anoexecmount or a W^X policy- Big
malloccreates a new line inmapsyour allocator usedmmapfor that size - RSS balloons after
fork()copy on write did its job and you wrote to lots of shared pages - Accidentally clobbered a mapping you probably used
MAP_FIXED. PreferMAP_FIXED_NOREPLACEto fail instead of overwrite
When it is mysterious, look. Start friendly with smaps_rollup for the big picture and maps for shapes. Drop to pagemap and the kpage* files only when you truly need per page truth and expect to need privileges.
A small checklist to keep nearby
- Need memory now.
mmapanonymous withPROT_READ|PROT_WRITEandMAP_PRIVATE|MAP_ANONYMOUS - Generating code. Keep W^X. Write bytes then
mprotect(PROT_READ|PROT_EXEC) - Mapping a file.
offsetmust be page aligned. Touching beyond real EOF isSIGBUS - Lots of major faults. Nudge the kernel with
MADV_WILLNEEDor touch earlier. Watch page cache and storage - Where did memory go. Start with
/proc/<pid>/smaps_rollupthen/proc/<pid>/maps - Forking big processes. Expect CoW. RSS grows as you write. Consider
execin the child for heavy work - Latency sensitive. Consider THP or mTHP where it helps.
mlockhot sets. Watch your TLB behavior
Feedback is extremely welcomed! You can reach out to me on X @0xkato