Oct 30, 2025
AWS published a post-mortem about a recent outage [1]. Big systems like theirs are complex, and when you operate at that scale, things sometimes go wrong. Still, AWS has an impressive record of reliability.
The post-mortem mentioned a race condition, which caught my eye. I don’t know all the details of AWS’s internal setup, but using the information in the post-mortem and a few assumptions, we can try to reproduce a simplified version of the problem.
As a small experiment, we’ll use a model checker to see how such a race could happen. Formal verification can’t prevent every failure, but it helps us think more clearly about correctness and reason about subtle concurrency bugs. For this, we’ll use the Spin model checker, which uses the Promela language.
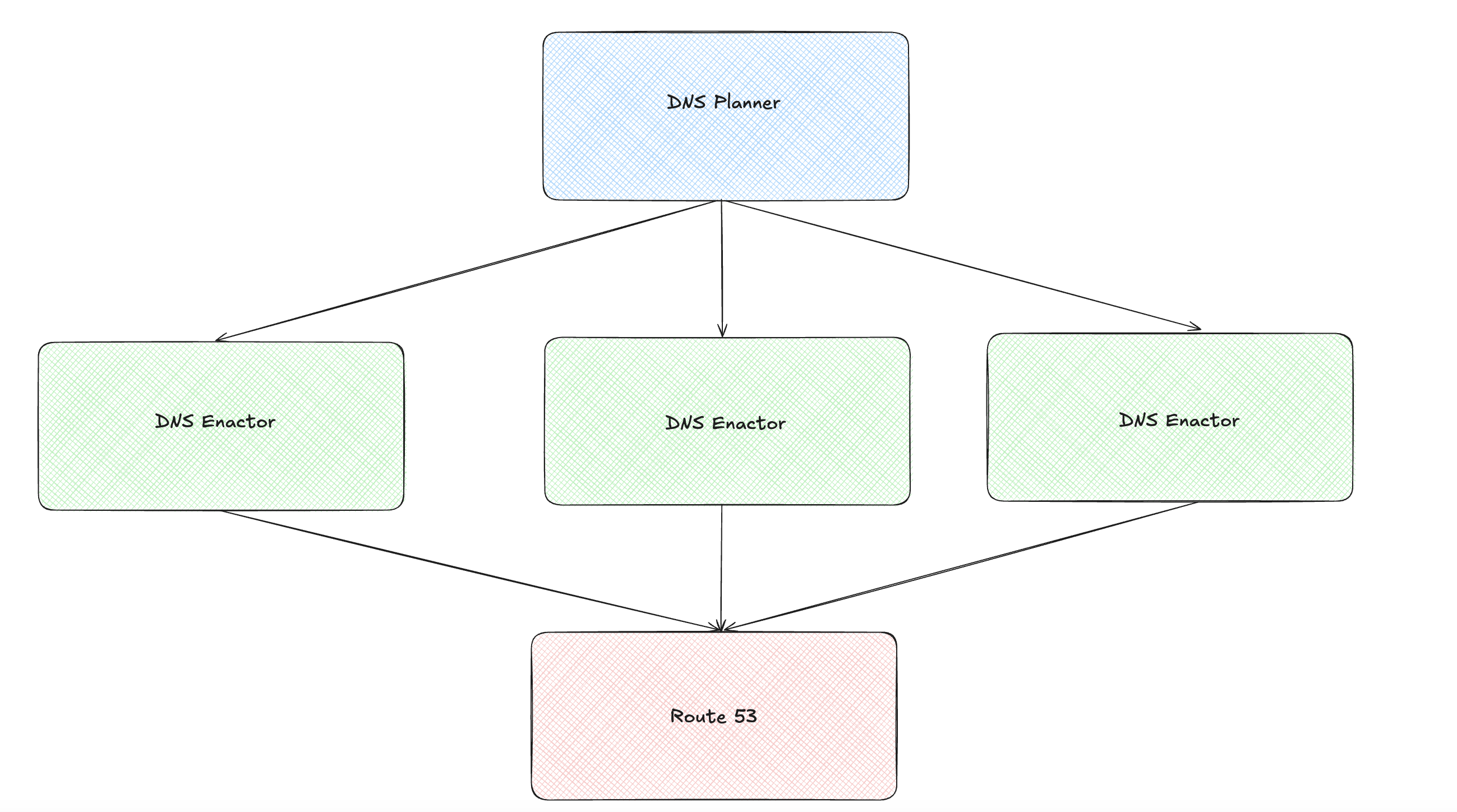
There’s a lot of detail in the post-mortem, but for simplicity we’ll focus only on the race-condition aspect. The incident was triggered by a defect in DynamoDB’s automated DNS management system. The components of this system involved in the incident were the DNS Planner, DNS Enactor, and Amazon Route 53 service.
The DNS Planner creates DNS plans, and the DNS Enactors look for new DNS plans and apply them to the Amazon Route 53 service. Three Enactors operate independently in three different availability zones.
Here is an illustration showing these components (if the images appear small, please open them in a new browser tab):

My understanding of how the DNS Enactor works is as follows: it picks up the latest plan and, before applying it, performs a one-time check to ensure the plan is newer than the previously applied one. It then applies the plan and invokes a clean-up process. During the clean-up, it identifies plans significantly older than the one it just applied and deletes them.
Using the details from the incident report, we could sketch an interleaving that could explain the race condition. Two Enactors running side by side: Enactor 2 applies a new plan and starts cleaning up, while the other, running just a little behind, applies an older plan, making it an active one. When the Enactor 2 finishes its cleanup, it deletes that plan, and the DNS entries disappear. Here’s what that sequence looks like:

Let’s try to uncover this interleaving using a model checker.
In Promela, you can model each part of the system as its own process. Spin then takes those processes, starts from the initial state, and systematically applies every possible transition, exploring all interleavings to build the set of reachable states [2]. It checks that your invariants hold in each one, and if it finds a violation, it reports a counterexample.
We’ll create a DNS Planner process that produces plans, and DNS Enactor processes that pick them up. The Enactor will check whether the plan it’s about to apply is newer than the previous one, update the state of certain variables to simulate changes in Route 53, and finally clean up the older plans.
In our simplified model, we’ll run one DNS Planner process and two concurrent DNS Enactor processes. (AWS appears to run three across zones; we abstract that detail here.) The Planner generates plans, and through Promela channels, these plans are sent to the Enactors for processing.
Inside each DNS Enactor, we track the key aspects of system state. The Enactor keeps the current plan in current_plan, and it represents DNS health using dns_valid. It also records the highest plan applied so far in highest_plan_applied. The incident report also notes that the clean-up process deletes plans that are “significantly older than the one it just applied.” In our model, we capture this by allowing an Enactor to remove only those plans that are much older than its current plan. To simulate the deletion of an active plan, the Enactor’s clean-up process checks whether current_plan equals the plan being deleted. If it does, we simulate the resulting DNS failure by setting dns_valid to false.
Here’s the code for the DNS Planner:
active proctype Planner() {
byte plan = 1;
do
:: (plan <= MAX_PLAN) ->
latest_plan = plan;
plan_channel ! plan;
printf("Planner: Generated Plan v%d\n", plan);
plan++;
:: (plan > MAX_PLAN) -> break;
od;
printf("Planner: Completed\n");
}
It creates plans and sends them over a channel (plan is being sent to the channel plan_channel) to be picked up later by the DNS Enactor.
We start two concurrent DNS Enactor processes by specifying the number of enactors after the active keyword.
active [NUM_ENACTORS] proctype Enactor()
The DNS Enactor waits for plans and receives them (? opertaor receives a plan from the channel plan_channel). It then performs a staleness check, updates the state of certain variables to simulate changes in Route 53, and finally cleans up the older plans.
:: plan_channel ? my_plan ->
snapshot_current = current_plan;
// staleness check
if
:: (my_plan > snapshot_current || snapshot_current == 0) ->
if
:: !plan_deleted[my_plan] ->
/* Apply the plan to Route53 */
current_plan = my_plan;
dns_valid = true;
initialized = true;
/* Track highest plan applied for regression detection */
if
:: (my_plan > highest_plan_applied) ->
highest_plan_applied = my_plan;
fi
// runs the clean-up process (omitted for brevity, included in the
// code linked below)
fi
fi
How do we discover the race condition? The idea is this: we express as an invariant what must always be true of the system, and then ask the model checker to confirm that it holds in every possible state. In this case, we can set up an invariant stating that the DNS should never be deleted once a newer plan has been applied. (With more information about the real system, we could simplify or refine this rule further.)
We specify this invariant formally as follows:
/*
A quick note on some of the keywords used in the invariant below:
ltl - keyword that declares a temporal property to verify (ltl: linear temporal logic lets you specify properties about all possible executions of your program.)
[] - "always" operator (this must be true at every step forever)
-> - "implies" (if left side is true, then right side must be true)
*/
ltl no_dns_deletion_on_regression {
[] ( (initialized && highest_plan_applied > current_plan
&& current_plan > 0) -> dns_valid )
}
When we start the model checker, one DNS Planner process begins generating plans and sending them through channels to the DNS Enactors. Two Enactors receive these plans, perform their checks, apply updates, and run their cleanup routines. As these processes interleave, the model checker systematically builds the set of reachable states, allowing the invariant to be checked in each one.
When we run the model with this invariant in the model checker, it reports a violation. Spin reports one error and writes a trail file that shows, step by step, how the system reached the bad state.
$ spin -a aws-dns-race.pml
$ gcc -O2 -o pan pan.c
$ ./pan -a -N no_dns_deletion_on_regression
pan: wrote aws-dns-race.pml.trail
(Spin Version 6.5.2 -- 6 December 2019)
State-vector 64 byte, depth reached 285, errors: 1
23201 states, stored
11239 states, matched
34440 transitions (= stored+matched)
(truncated for brevity....)
The trail file in the repository below shows how the race happens. The trail file shows that two Enactors operate side by side: the faster one applies plan 4 and starts cleaning up. Because cleanup only removes plans much older than the one just applied, it deletes 1 and 2 but skips 3. The slower Enactor then applies plan 3 and makes it active, and when the faster Enactor picks up cleanup again, it deletes 3 and the DNS goes down.
Here’s an illustration of the interleaving reconstructed from the trail:

Before publishing, I reread the incident report and noted: “Additionally, because the active plan was deleted, the system was left in an inconsistent state…”. This suggests a direct invariant: the active plan must never be deleted.
ltl never_delete_active {
[] ( current_plan > 0 -> !plan_deleted[current_plan] )
}
Running the model checker with this invariant produces essentially the same counterexample as before: one Enactor advances to newer plans while the other lags and applies an older plan, thereby making it active. When control returns to the faster Enactor, its cleanup deletes that now-active plan, violating the invariant.
Invariants are invaluable for establishing correctness. If we can show that an invariant holds in the initial state, in every state reachable from it, and in the final state as well, we gain confidence that the system’s logic is sound.
To fix the code, we execute the problematic statements atomically. You can find both versions of the code, the one with the race and the fixed one, along with the interleaving trail in the accompanying repository [3]. I’ve included detailed comments to make it self-explanatory, as well as instructions on how to run the model and explore the trail.
Some of the assumptions in this model are necessarily simplified, since I don’t have access to AWS’s internal design details. Without that context, there will naturally be gaps between this abstraction and the real system. This model was created in a short time frame for experimental purposes. With more time and context, one could certainly build a more accurate and refined version.
Please keep in mind that I’m only human, and there’s a chance this post contains errors. If you notice anything off, I’d appreciate a correction. Please feel free to send me an email.
- AWS Post-Incident Summary — October 2025 Outage
- How concurrency works: A visual guide
- Source code repository
- Spin model checker