
{kind=link}
As part of our Public Data Project, LIL recently launched Data.gov Archive Search. In this post, we look under the hood and reflect on how and why we built this project the way we did.
Rethinking the Old Trade-Off: Cost, Complexity, and Access
Libraries, digital humanities projects, and cultural heritage organizations have long had to perform a balancing act when sharing their collections online, negotiating between access and affordability. Providing robust features for data discovery, such as browsing, filtering, and search, has traditionally required dedicated computing infrastructure such as servers and databases. Ongoing server hosting, regular security and software updates, and consistent operational oversight are expensive and require skilled staff. Over years or decades, budget changes and staff turnover often strand these projects in an unmaintained or nonfunctioning state.
The alternative, static file hosting, requires minimal maintenance and reduces expenses dramatically. For example, storing gigabytes of data on Amazon S3 may cost $1/month or less. However, static hosting often diminishes the capacity for rich data discovery. Without a dynamic computing layer between the user’s web browser and the source files, data access may be restricted to brittle pre-rendered browsing hierarchies or search functionality that is impeded by client memory limits. Under such barriers, the collection’s discoverability suffers.
For years, online collection discovery has been stuck between a rock and a hard place: accept the complexity and expense required for a good user experience, or opt for simplicity and leave users to contend with the blunt limitations of a static discovery layer.
Why We Explored a New Approach
When LIL began thinking about how to provide discovery for the Data.gov Archive, we decided that building a lightweight and easily maintained access point from the beginning would be worth our team’s effort. We wanted to provide low-effort discovery with minimal impact on our resources. We also wanted to ensure that whatever path we chose would encourage, rather than impede, long-term access.
This approach builds on our recent experience when the Caselaw Access Project (CAP) hit a transition moment. At that time, we elected to switch case.law to a static site and to partner with others dedicated to open legal data to provide more feature-rich access.
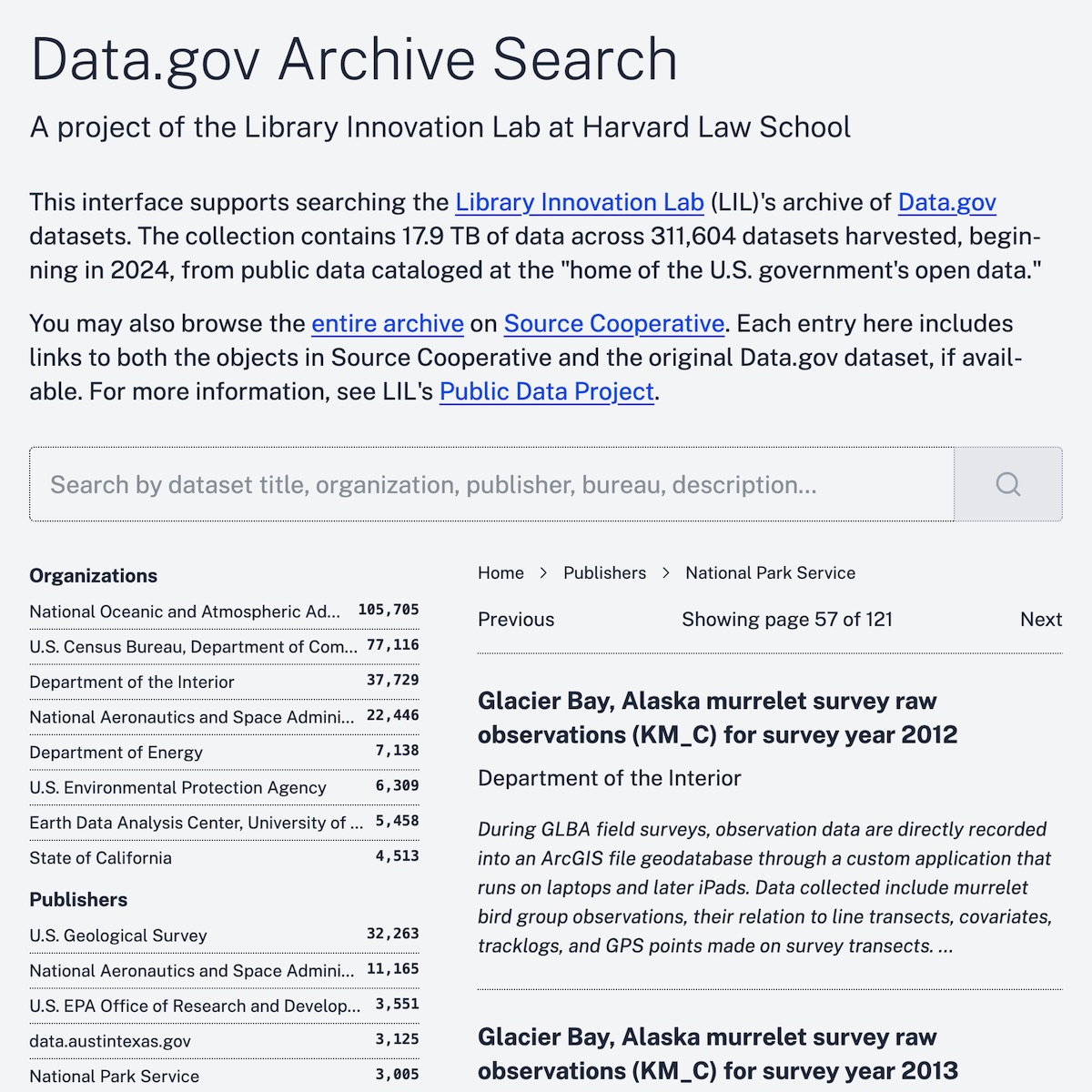
CAP includes some 11 TB of data; the Data.gov Archive represents nearly 18 TB, with the catalog metadata alone accounting for about 1 GB. Manually browsing the archive data in its repository, even for a user who knows what she’s looking for, is laborious and time-consuming. Thus we faced a challenge. Could we enable dynamic, scalable discovery of the Data.gov Archive while enjoying the frugality, simplicity, and maintainability of static hosting?
Our Experiment: Rich Discovery, No Server Required
Recent advancements in client-side data analysis led us to try something new. Tools like DuckDB-Wasm, sql.js-httpvfs, and Protomaps, powered by standards such as WebAssembly, web workers, and HTTP range requests, allow users to efficiently query large remote datasets in the browser. Rather than downloading a 2 GB data file into memory, these tools can incrementally retrieve only the relevant parts of the file and process query results locally.
We developed Data.gov Archive Search on the same model. Here’s how it works:
- Data storage: We store Data.gov Archive catalog metadata as sorted, compressed Parquet files on Source.coop, taking advantage of performant static file hosting.
- In-browser query engine: Our client-side web application loads DuckDB-Wasm, a fully functional database engine running inside the user’s browser.
- On-demand data access: When a user navigates to a resource or submits a search, our DuckDB-Wasm client executes a targeted retrieval of the data needed to fulfill the request. No dedicated server is required; queries run entirely in the browser.
This experiment has not been without obstacles. Getting good performance out of this model demands careful data engineering, and the large DuckDB-Wasm binary imposes a considerable latency cost. As of this writing, we’re continuing to explore speedy alternatives like hyparquet and Arquero to further improve performance.
Still, we’re pleased with the result: an inexpensive, low-maintenance static discovery platform that allows users to browse, search, and filter Data.gov Archive records entirely in the browser.
Why This Matters for Libraries, Digital Humanities Projects, and Beyond
This new pattern offers a compelling model for libraries, academic archives, and DH projects of all sizes:
- Lower operating costs: By shifting from an expensive server to lower cost static storage, projects can sustainably offer their users access to data.
- Reduced technical overhead: With no dedicated backend server, security risks are reduced, no patching or upgrades are needed, and crashing servers are not a concern.
- Sustained access: Projects can be set up with care, but without demanding constant attention. Organizations can be more confident that their archive and discovery interfaces remain usable and accessible, even as staffing or funding changes over time.
Knowing that we are not the only group interested in approaching access in this way, we’re sharing our generalized learnings. We see a few ways forward for others in the knowledge and information world:
- Prototype or pilot: If your organization has large, relatively static datasets, consider experimenting with a browser-based search tool using static hosting.
- Share and collaborate: Template applications, workflows, and lessons learned can help this new pattern gain adoption and maturity across the community.
This project is still evolving, and we invite others—particularly those in libraries and digital cultural heritage—to explore these possibilities with us. We’re committed to open sharing as we refine our tools, and we welcome collaboration or feedback at [email protected].