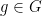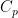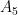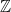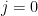When I first learned about Diffie-Hellman and especially elliptic curve Diffie-Hellman, I had one rather obvious question: Why elliptic curves? Why use this strange group that seems rather arbitrary, with its third intersection of a line and then reflected? Why not use, say, the Monster Group? Surely a monster is better equipped to guard your secrets than some curve thing named after, but legally distinct from, a completely different curve thing!
I wouldn’t have a satisfying answer to this question until way into my graduate studies, and the answer makes a perfect blog post for the “Cryptography (Incomprehensible)” category of this blog, so here we go.
Groups
First, as a recap, what do we mean by Diffie-Hellman? Well, we need a group , and element of this group with some order , so is the smallest positive integer with where is the neutral element of the group. The we take our private key and compute our public key as . We can now compute a shared secret with some other public key as .
This should work for any group , no? So why doesn’t it work for the monster? Let’s take a closer look at the map that computes public keys from private keys (in fact, the rest of this blog will only focus on that map, the whole key exchange thing doesn’t really matter much, you could also compute Schnorr signatures or whatever). Given any group element , we can always create the exponentiation map . This map is a group homomorphism and is not necessarily injective. In fact, for finite groups, it is never injective. There is an old trick in algebra, where you can make any group homomorphism injective, by dividing the domain by its kernel. The kernel in question here is the ideal of all multiples of our order , so setting our key space to is a sensible first step with no drawbacks, you don’t really get new keys by allowing all integers. The map is also not necessarily surjective, though. In fact, image of the map is exactly , the subgroup of consisting of all multiples of the generator (This is why we call the generator, it generates the whole thing).
So we can somewhat simplify our private to public map by looking at . With that our private to public key map is not just a group homomorphism, but also injective and surjective, in other words, a group isomorphism.
A tangent on finite simple groups
This gives us the first answer to “why not the monster group?”, although it is an answer that leads to even more questions. To get to that answer we have to ask an even deeper question, namely, what groups even are there? We want to work on a computer, so finite would be nice, and we have heard of small subgroup attacks, so something without normal subgroups, please. (If you don’t know what a normal subgroup is, it’s things you can divide out of a group). A finite simple group, in other words.
One of the most impressive results in 20th century mathematics has to be the classification of finite simple groups. The (not quite) ultimate answer to the question of “what groups even are there?”
To classify groups, we need to figure out what we mean by two groups being the same. Clearly, the numbers on a clock and are the same thing, even if the clock uses Roman numerals. So simple relabeling of group elements should not count as a separate thing. In other words, we want to classify finite simple groups up to isomorphism.
The answer to this classification problem is absolutely mind boggeling: First, there are infinite families of groups. For example , the cyclic groups with prime order. Another such family are the alternating groups, from onwards. There are 16 more such infinite families, the others being said to be of “Lie type”. And then there are 26 groups that just, sort, of hang out by themselves. They are not part of an infinite family, they just exist, and there is no way to make them bigger or anything. The monster group mentioned above is the largest of them, and I totally did not chose it in the intro because it has a cool name and let’s me go on a tangent about sporadic groups.
But with this classification out of the way, we can now spot a problem (we could have spotted the problem before stating the classification result, but come on, it’s such a cool result!). Namely that, in order to even answer the question “what groups are there”, we had to say that we want to look at groups up to isomorphism. But our private to public map is a group isomorphism! To a group theorist, the idea that somehow differs from is preposterous, they both clearly are just the cyclic group of order p!
Categories
So, uhm, we kinda – accidentally – by asking the innocent question why we use elliptic curves instead of any other group for Diffie-Hellman, have blown a wide hole in the entire concept of Diffie-Hellman. If the private key space and the public key space are one and the same, then how does Diffie-Hellman even exist? How can it be secure, if we cannot even distinguish private keys from public keys?
Well, we are already talking to the group theorists, and are having an existential crisis of sorts, so why not just give in and let them pull us deeper, into the realm of the category theorists? Things can’t possibly get worse, can they?
A category is a class of objects, such that for any two objects there is a class of homomorphisms between and . Homomorphisms are just that, elements of this class. We are generous enough to require there to be an identity homomorphism in and a composition operations, where the existence of and gives you a homomorphism , but that’s about it. In particular, we do not even necessarily require our objects to be sets. We definitely do not require our homomorphisms to be functions. In fact, just so that nobody gets any stupid ideas, when we don’t call them homomorphisms, we call them arrows. A category is really more like a directed graph. A graph that has so many vertices that they do not necessarily fit in a set any more, and where two vertices might have so many edges between them that they don’t fit either. This is why we said class above, a class is a collection of things that is potentially larger than any set. For example, there is a class of all sets, but there cannot be a set of all sets, because nobody knows how to shave them or something. In fact, sets, written as SET is an example of a category. The objects are sets, and homomorphisms are the functions between those sets.
In order to not fully drift off into space, we will only look at locally small categories. Locally small categories are categories where the homomorphisms actually do form a set. Which makes life a whole lot simpler, and pretty much encompasses everything we want to know about anyways.
So aside from SET, what are examples of categories? Why does this kinda thin definition turn out to be so useful that is sprung force an entire field of mathematics, with so much abstract nonsense? Well, it turns out, pretty much every thing can be seen as a category. Graphs? Category. Groups? Category. Rings? Category. Fields? Category. Topological spaces? Category. Analytic varieties? Category. Algebraic varieties? You might have guessed it, also a category. Vector spaces? Category. Modules? Category.
It turns out, if all you require from things is that they somehow have some homomorphisms between them that vaguely act like functions, you can pull in pretty much every mathematical object known to humanity. But is it useful? We didn’t even define our objects to be sets, yet all the examples I gave above are sets. Surely something more concrete than an absurdly infinite directed graph would be better? It turns out, categories are immensely useful. You do have to redefine terms in somewhat awkward ways, but once you have done that you can make statements that are true for fields, rings, groups, vector spaces, topological space, etc all at once. For example, we no longer can define a kernel as all the elements mapping to zero, because remember, objects aren’t necessarily sets, so they do not necessarily have elements, so instead we have to say fancy words like “the kernel of a homomorphism f in a locally small category with zero homomorphisms is a homomorphism k that when composed with f is zero, and is universal in that property”. We won’t quite need that full apparatus today (In particular, we won’t need universal properties), but we do need the slightly simpler concept of initial and terminal objects. An initial object is an object such that for any , has exactly one element. A terminal object is the dual object, i.e. for every we have exactly one element in . If an object is both initial and terminal we call this object a zero object, and the unique homomorphism it has for a given the zero homomorphism. Examples are important for this, so let’s first look at SET. The initial object here is the empty set, since there is a unique function (the empty function) from the empty set to any given set. The empty set however is not the terminal object, as there are no functions into the empty set from a non-empty set. Instead, the singleton set with exactly one element takes the place of the terminal object. When we look at GROUP, we see an example of a category with a zero object, the trivial group consisting of only the neutral element. There is exactly one group homomorphism from the trivial group to any given group, since group homomorphisms have to map neutral elements to neutral elements, and there is exactly one group homomorphism from any given group to the trivial group, given by mapping everything to the neutral element. To tie off our examples, a slightly more interesting case is the category RING of (commutative) rings. Our terminal object is again the trivial ring consisting only of the element 0, but it cannot be the initial object, since a ring homomorphism needs to map 1 to 1, and the trivial ring, having only one element, cannot map that element to both 0 and 1. Instead, the initial object of the category of rings are the integers . The most generic cyclic group.
Group Objects
What where we talking about again, oh right Diffie-Hellman. So with the language of category theory under our belt, we can now point exactly to why “any group should works” is not working. As long as we are only looking at groups, we have to look at groups up to isomorphism (otherwise relabeling things would be a different thing), but our private to public key map is a group isomorphism. We are not looking at the right category. Diffie-Hellman does not work with groups.
The relevant part is in chapter 3, wedged in there between copious amounts of abstract nonsense.
To go through it in a bit more detail, we have some category that we use as our base. We want to make some object in that category into a group. But remember, this is category theory, so is not necessarily a set. I mean, it will be a set in any practical situation, but we can pretend that we don’t know that, for some really, really cool math. And you should always pretend that you don’t know something when it leads to some really, really cool math. So the only thing we have is homomorphisms. In the cropped away parts of the chapter, we did narrow things down to locally small categories that have a terminal object, and named that terminal object . So, if we don’t have elements, how can we describe the group axioms? Well the first one, associativity, is about multiplication. Multiplication is a map, mapping two elements of the group to one element, so we can just say that we require that map to be a homomorphism in (Do not ask what is if is not a set. It’s something about universal properties, and I promised there would be no universal properties). To define associativity, we need that is the same as . This is due to the universal property thing that we do not talk about, but it gives us this canonical isomorphism, i.e. those two constructions are the same, and they are the same in some very obvious way. Now associativity is just saying that the multiplication morphism, applied twice in one order, is the same as the multiplication morphism, applied twice, in some other order, what you see in the screenshot as the first property. Similarly, commutativity is also just a statement on the multiplication morphism, with yet another canonical morphism, explaining the fourth, optional property.
Way more interesting and cooler is the second property, which defines the neutral element. So how does one define a neutral element, when you try to pretend very hard that you do not have any elements? This is where our terminal object comes in. We designate an element of and call it the neutral morphism. Note that 0 is the terminal object, not the initial object, so e is not necessarily unique. In fact, if we take the category of sets as our base (which will give us back the groups we know and love), the terminal object, as discussed above, is the singleton set. A map from the singleton set into a set can be seen as pointing at one specific element in our target set. To put differently, an element of in the category of sets is just an element of . Now we need to describe what makes the neutral element, well, neutral. It should interact with our multiplication morphism in some way. We now perform the most miraculous part of our definition. We want to define the neutral property, i.e. that , but without mentioning , and instead phrase it as a series of maps. Let’s stay with for a bit, though, to come up with a battle plan. Since we want to talk about , we want to make a statement about , using the prefix notation instead of the more familiar infix. So we need to construct , ideally starting from , so we can have a nice equality in the end. So starting from a single element, we want two. There is a way to do this, by using the diagonal morphism . That’s not quite , but it at least has two components. The first component we can leave unchanged, in other words, we apply the identity to it. But how do we get rid of the second component? Well, we can map it to our terminal object 0. There is exactly one way to do that. Now that we are in 0, we can apply our neutral morphism to get back to . If we write for the only element in our terminal set 0, and write for the neutral element in our group, what we can do is a chain of maps like this: . Now we can apply and expect to end up at the same place. In other words . And suddenly, we have described what a neutral element does, without having, you know, elements.
The last property, about the inverse, uses a similar construction, this time with another morphism that maps from the group object to itself, to find the inverse. I leave it to the reader to go through why it has to look this exact way.
Finding our category
And with that, we now finally have the tools to actually answer our original question. What is the thing that we map into and what options do we have for that? We have established that it is not a group, as groups would not be able to distinguish private and public key. We need some additional structure, something that tells us how we can operate on the elements of our thing, without saying that the and nothing else. We still want something that behaves like a group, though, since the whole stuff with agreeing on keys and stuff fundamentally relied on there being some group things going on. We need a group object. But what is our category we use as a base? It can’t be SET, since that would lead straight back to groups. We probably want something with finite objects, because computers aren’t very good at dealing with things that don’t fit into their little memories and disks and registers and stuff. We do want to be able to compute at the very least the multiplication morphism . We will need a tiny amount of handwaving, but I think it is not too hard to see that taking tuples of elements of finite fields as a base might be a good idea. Computations on these tuples would involve addition, multiplication, typical field stuff. Adding and multiplying elements of a field? It kind of looks like we want our morphisms to be polynomials! And, as it turns out, there is a category just like that, the category of algebraic varieties. The category of some tuples of finite field elements, where you map stuff around by applying polynomials. So our public key space should be the group objects in the category of algebraic varieties, usually called algebraic groups.
We have classified those. There are two main types, the linear groups and the abelian varieties. You can multiply them together, too but we are really interested in simple groups, so we want them in their most basic forms. First, the linear groups. They come in two flavors, the additive group and the multiplicative group . The additive group would work for Diffie-Hellman, if it wasn’t for this very efficient algorithm that can solve the discrete log problem in this group, named “division”. The multiplicative group we set aside and get to in the next chapter. That leaves us with abelian varieties. Varieties have an important invariant, called the dimension. So what are the abelian varieties of dimension 1? Elliptic curves. And they work great. We could go to higher dimensions (and in fact people have explored this), but it turns out you don’t really get anything but headaches from that. They result in secure constructions, but point counting is hard, and you get these “special divisors” which make constant time programming a nightmare, and get nothing in return. So that is why elliptic curves, even though at first glance looking like a quite arbitrary and odd choice for a “group” are actually pretty much the only choice there is.
What about finite field Diffie-Hellman?
This only leaves the multiplicative group. It showed up in our classification, and you probably know that it has been used in cryptography (under the name finite field Diffie-Hellman), so shouldn’t the title of this blog post be “There is no Diffie-Hellman but Elliptic Curve Diffie-Hellman and also Finite Field Diffie-Hellman”?
I mean yeah, but it would be an awful title, way less clickbaity, so let’s end this blog post by showing that Finite Field Diffie-Hellman is also just Elliptic Curve Diffie-Hellman. Well “Elliptic Curve” Diffie-Hellman, but I’m getting ahead of myself.
We’ve classified a lot of objects in this blog post, so what about one more? How can we describe all elliptic curves (up to isomorphism)?
To do this, we need the so called j invariant, defined as , for an elliptic curve given by . Two elliptic curves are isomorphic (over the algebraic closure) if and only if they have the same j invariant.
How many j invariants are there? In other words, does every element of the base field show up? It turns out, yes. Given an element , if , we can use the curve . For , we can use the curve . For all other cases, we can just use . You can check that this will have the right j invariant.
In other words, two elliptic curves are isomorphic (over the algebraic closure) if they share the same j invariant, and there is one j invariant for every element of our base field. So we can think of our elliptic curves as points on the affine line, and somehow, the collection of all elliptic curves, themselves behaves like an algebraic variety. (This is an extremely powerful concept called the moduli space). Affine varieties always feel like they are incomplete, you really want to see if there are any points of infinity you could add to them. The affine line in particular really wants to be a projective line, and add its one point at infinity it is due. And it turns out, we can do this in a sensible way (constructing the moduli of stable curves of genus 1). This point at infinity? It belongs to the curve . It kind of looks like an elliptic curve at first glance. Sure it’s not in Weierstraß form, but you can rectify that and give an isomorphic curve that has that form (I’m too lazy to do that right now). However, this is not an elliptic curve. In order for a curve to be elliptic, it needs to not have any singularities, and this curve has, …, well, here is a plot of it:
When a curve intersects itself in this awkward way, that’s a singularity. But other than that, it is perfectly fine. In fact, you can even use the very same formulas as you use for elliptic curves to do point addition and everything, just stay away from that singularity at . And when you do that, you notice something strange. You can simplify the formula. It’s a bit on the lengthier side of algebra when doing it by hand the long way around, but very much doable. And when you simplify it, you notice that the points on the nodal curve (save for the singularity) can be described by a single non-zero field element, and that adding two points is the same as multiplying the corresponding field elements. In other words, this curve, the somewhat awkward reject elliptic curve, gives us the multiplicative group. Finite field Diffie-Hellman is also just Elliptic Curve Diffie-Hellman, just over a curve that accidentally twisted itself a bit. And we found that curve naturally, trying to hang out with its elliptic curve friends on the same moduli space (as opposed to the cuspial curve , with its way nastier singularity, which happens to give you the additive group instead, and does not hang out on this moduli space).
And so, far from being arbitrary, there was never an actual choice for Diffie-Hellman. There is only Elliptic Curves.