The idea behind an AI code review agent is simple. Listen to PR events, send each diff in the PR to an LLM and ask it to find issues, and then comment on the diff with any issues you find. The hope is that this catches issues that a human missed, improving code quality and stability.
There's a lot of these agents on the market right now: GitHub copilot review, Coderabbit, Greptile, Korbit, Qodo, Panto, Diamond, and probably 10 more I haven't heard of. But are these agents actually useful, and if so - how hard is it to make one?
Are they useful?
We've been using Coderabbit for the past few weeks at Sourcebot and have enjoyed it. A lot of the time it generates suggestions that aren't really related or helpful, but these are outweighed by the few times where it suggests a fix that a human reviewer completely missed.
Here's an example of a suggestion it gave us in a PR to add Bitbucket support to Sourcebot. Bitbucket has two different APIs, one for cloud and another for self-hosted. I had incorrectly assumed the pagination API was similar between the two, and Coderabbit was able to detect this. Granted, the proper solution here is to have just tested this better (oops) - but a human reviewer unfamiliar with the API wouldn't have caught this.
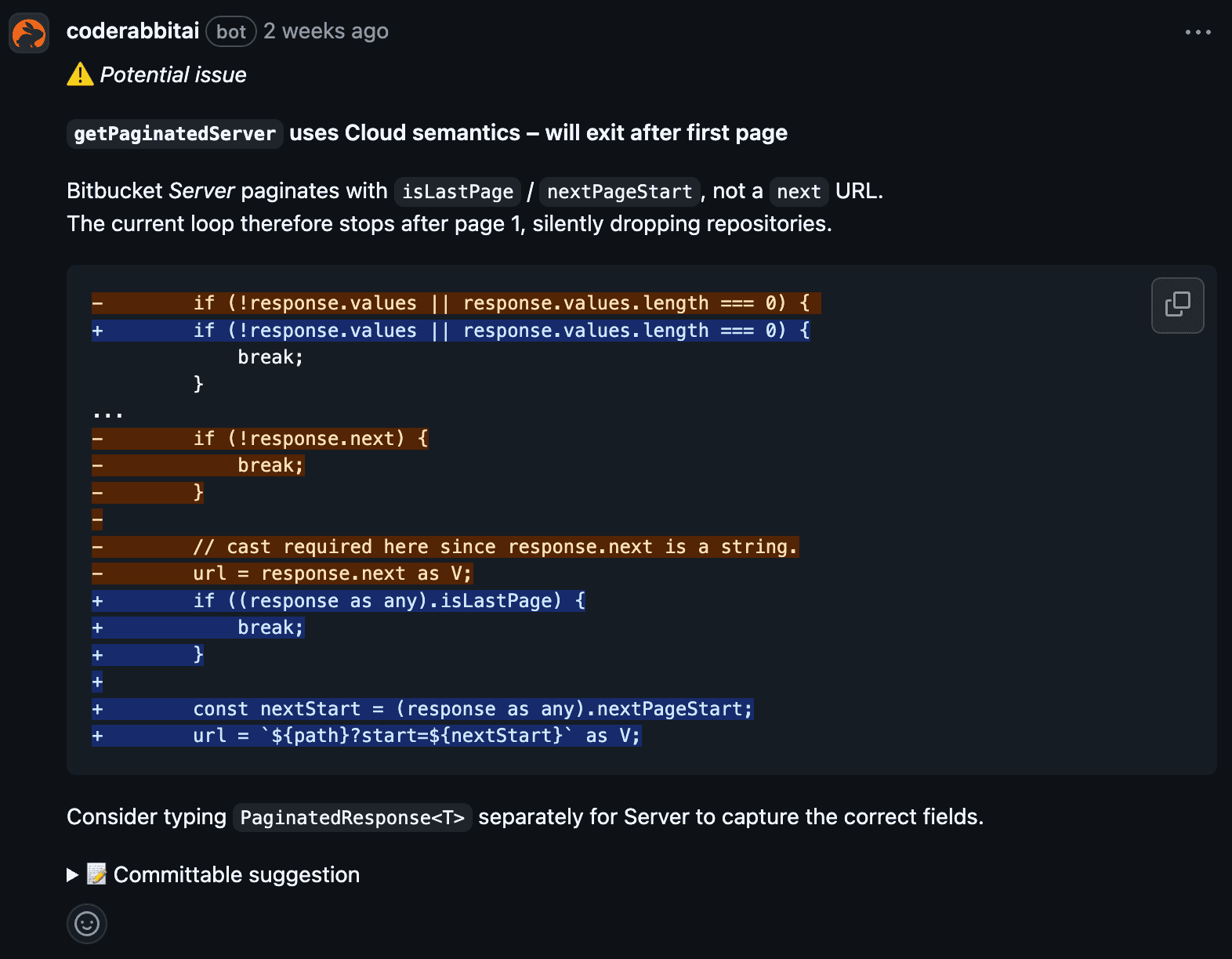
However, not all suggestions are this great. For example, on the same PR it suggested adding a projects field to a struct that keeps tracks of missing orgs/repos. On the surface this looks great, but it's missing key context about what this data is and where its being used. This new projects field would never be read anywhere and would introduce a subtle bug in our UI.

Overall I do think code review agents are useful at spotting issues a human reviewer may have missed, but you definitely can't accept their suggestions blindly.
How hard is it to build one?
I wanted to learn more about what seperates a good review agent from a bad one, so I decided to build one. You can check out my debug journey in this test PR.
It's pretty easy to build a basic review agent
The key word here is basic. A very dumb review agent can be developed in just a couple hours using the GitHub API and an OpenAI key. Detect PR, split up PR into chunks, feed chunks to OpenAI, comment the answer. I'm using gpt-4.1-minihere and each diff check costs around $0.0006

LLMs don't like to listen to you
Something I learned immediately is that you can beg the LLM to not do something but sometimes it just feels like doing it anyways. In the prompt to review the diff I mention Do NOT provide general feedback, summaries, explanations of changes, or praises for making good additions. But sometimes it just can't help itself:

Without broader context of the codebase, the review agent sucks
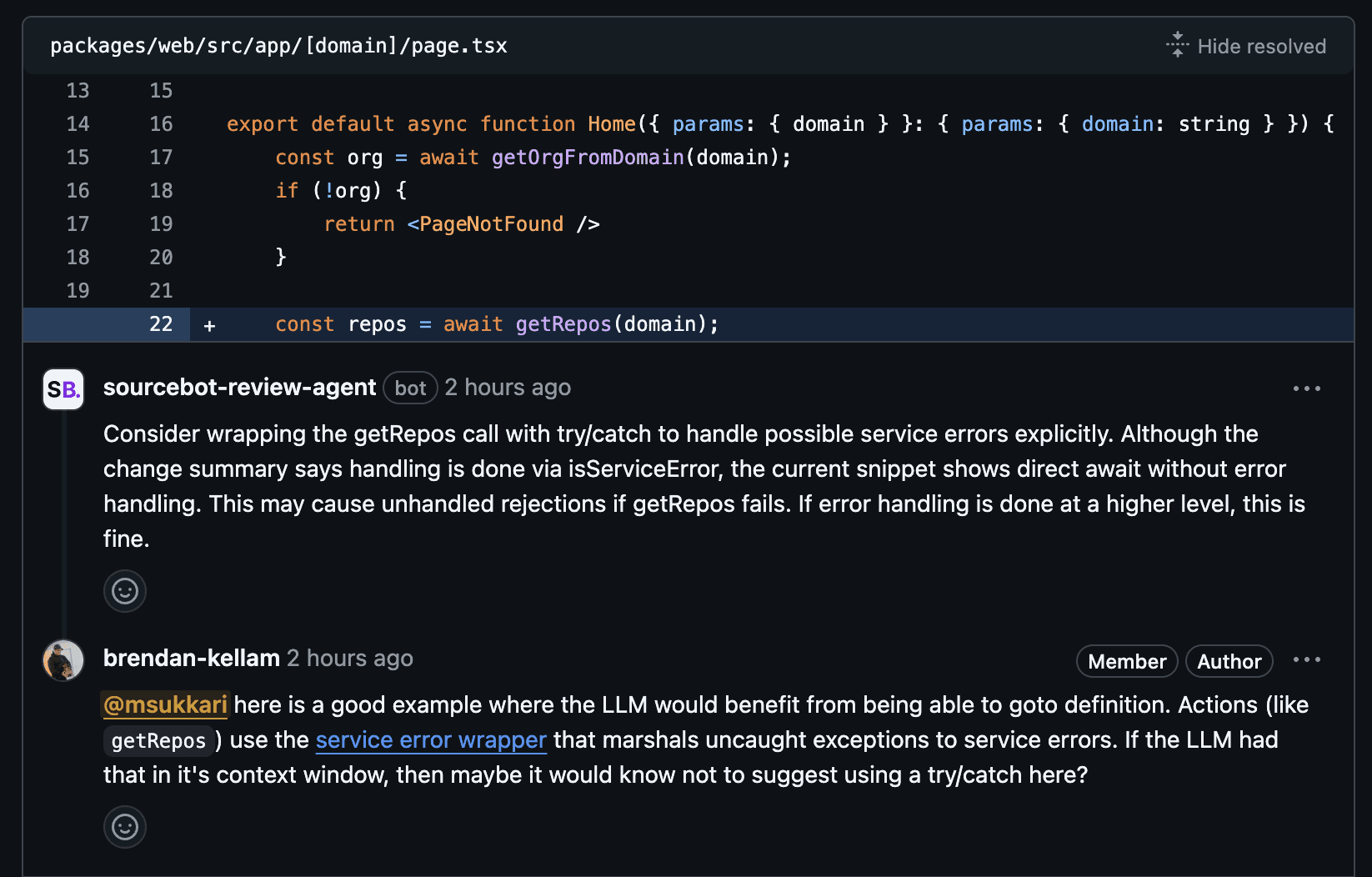
Here's an example of the review agent providing an unhelpful suggestion, likely because it doesn't understand the implementation of the function being called. As the complexity of the codebase increases this is only going to get worse.
This is an area we're excited to explore with Sourcebot, which allows you to index and query millions of lines of code. Plugging in Sourcebot context into this review agent is a natural next step to significantly improve results.
Conclusion
Do I think code review agents are useful? Yes. Do I think that you should go out and build your own? Probably not. There seems to be a decent amount of work needed to go from an agent producing lousy suggestions to something that actually makes your life easier.
The core problem here isn't really about code review agents, it's about making an LLM actually understand your code. A "code review agent" is just a component above this that chunks up diffs and sends suggestions to your PR.
I do believe there's a world where a framework exists to make building useful dev agents easier. My bet is that dev teams would prefer to have full control over their agents versus using off the shelf solutions. If you find this stuff interesting and would like to chat, feel free to reach out to me directly at [email protected]