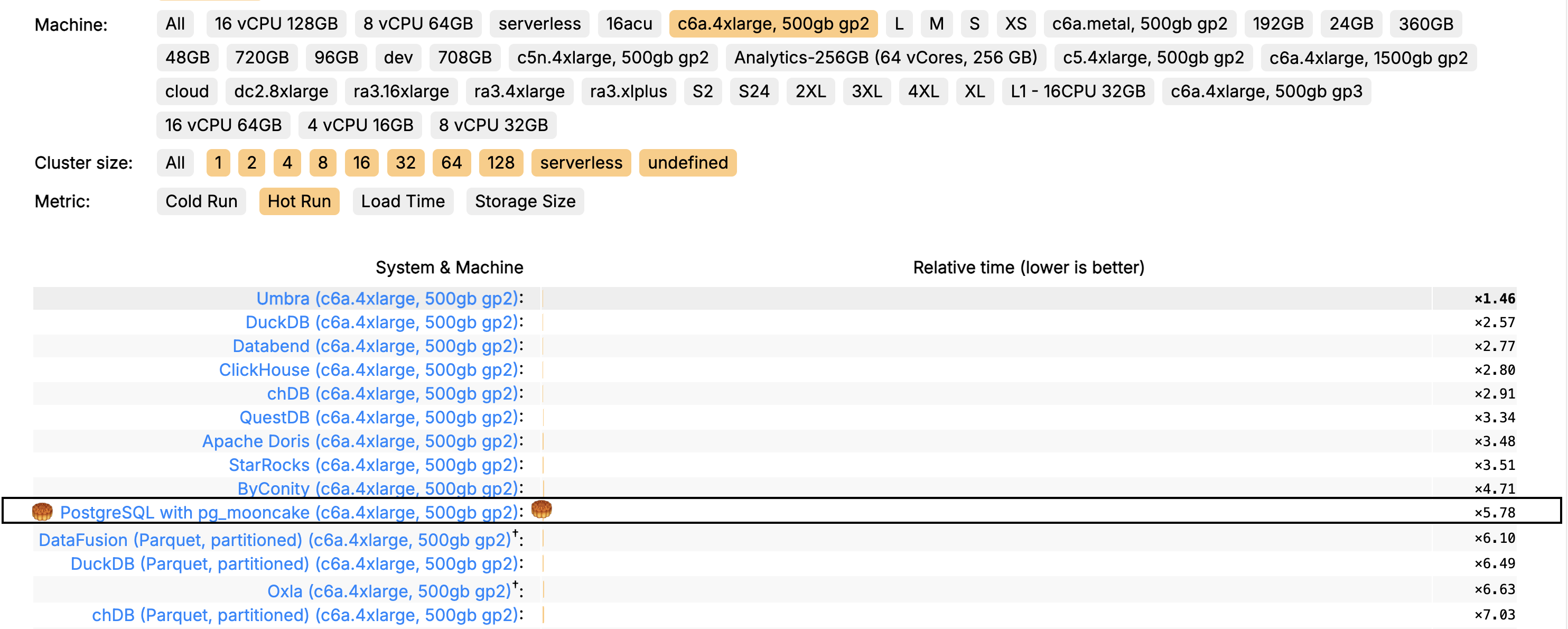
TLDR: We spent a few months optimizing PostgreSQL and made it to the Top 10 on ClickBench, a benchmark typically dominated by specialized analytics databases.
What’s more, all compute is within Postgres, and all tables are managed directly by PostgreSQL—it’s not a simple wrapper. This is the story of pg_mooncake.

ClickBench is the definitive benchmark for real-time analytics databases, originally designed to showcase the performance of ClickHouse. It evaluates databases on their ability to handle real-world analytics workloads, including high-volume table scans and complex aggregations.
Historically, ClickHouse and other purpose-built analytics databases have led this benchmark, while general-purpose databases like Postgres/MySQL have lagged behind by 100x. But we wanted to challenge that perception—and Postgres delivered.
How to Build Analytics in Postgres?
When most people think of PostgreSQL, they think of a rock-solid OLTP database, not a real-time analytics powerhouse. However, PostgreSQL’s extensibility makes it uniquely capable of punching above its weight class. Here’s how we approached the challenge:
1. Build a PG Extension
We leveraged PG's extensibility to build pg_mooncake as a native PG extension.
2. Storage Format: Columnstore
For analytics workloads, a columnstore format is essential. ClickBench workloads typically involve wide tables, but queries only access a small subset of columns.
- In a row store (like PostgreSQL heap table), reading a single column means jumping through rows.
- In a columnstore, reads are sequential, which is faster (and it also enables better compression and execution on compressed data).
3. Vectorized Execution
To enhance query execution speed, we embedded DuckDB as the execution engine for columnstore queries. This means across the execution pipeline, data is processed in batches instead of row by row, enabling SIMD, which is a lot more efficient for scans, groupbys, and aggregations.
4. Table Metadata & Management Directly in PostgreSQL
Efficient metadata handling is critical for real-time analytics, since fixed latency matters. Instead of fetching metadata or statistics from storage formats like Parquet, we store them directly in PG.
- This enables faster query planning.
- It also allows for advanced features like file skipping, significantly improving performance.
More details on the architecture.
What Does It Mean?
PostgreSQL is no longer just an OLTP workhorse. With careful tuning and engineering, it’s capable of delivering analytics performance on par with specialized databases while retaining the flexibility and ecosystem advantages of PostgreSQL.
After building advanced data systems for a decade, part of my core belief is: we can make the data stack a lot simpler.
pg_mooncake is MIT licensed, so if you don’t believe it, give it a try.
We launched v0.1 last week. And is now available on Neon Postgres and coming to Supabase.
🥮