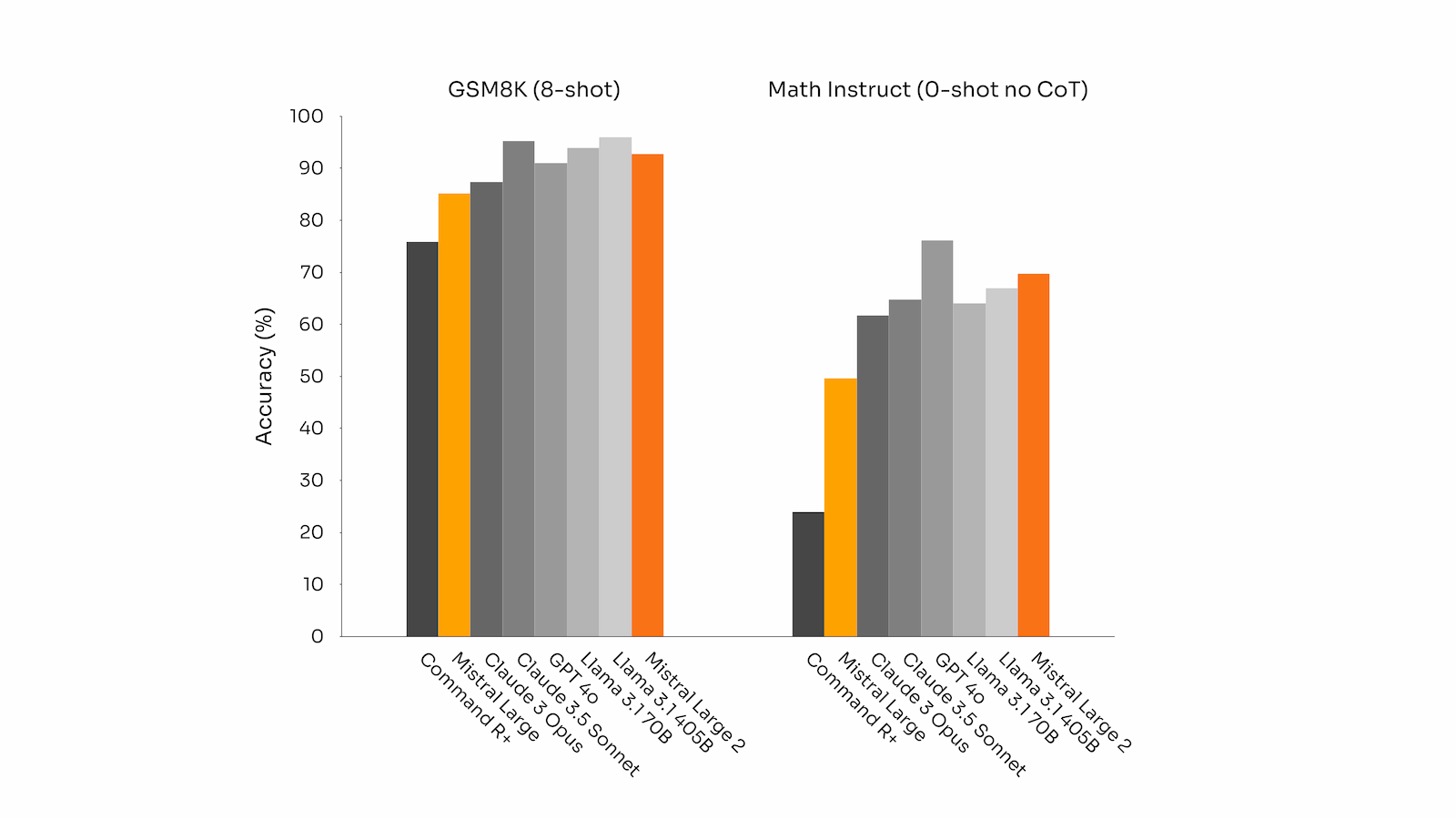
This latest generation continues to push the boundaries of cost efficiency, speed, and performance. Mistral Large 2 is exposed on la Plateforme and enriched with new features to facilitate building innovative AI applications.
Mistral Large 2
Mistral Large 2 has a 128k context window and supports dozens of languages including French, German, Spanish, Italian, Portuguese, Arabic, Hindi, Russian, Chinese, Japanese, and Korean, along with 80+ coding languages including Python, Java, C, C++, JavaScript, and Bash.
Mistral Large 2 is designed for single-node inference with long-context applications in mind – its size of 123 billion parameters allows it to run at large throughput on a single node. We are releasing Mistral Large 2 under the Mistral Research License, that allows usage and modification for research and non-commercial usages. For commercial usage of Mistral Large 2 requiring self-deployment, a Mistral Commercial License must be acquired by contacting us.
General performance
Mistral Large 2 sets a new frontier in terms of performance / cost of serving on evaluation metrics. In particular, on MMLU, the pretrained version achieves an accuracy of 84.0%, and sets a new point on the performance/cost Pareto front of open models.
Code & Reasoning
Following our experience with Codestral 22B and Codestral Mamba, we trained Mistral Large 2 on a very large proportion of code. Mistral Large 2 vastly outperforms the previous Mistral Large, and performs on par with leading models such as GPT-4o, Claude 3 Opus, and Llama 3 405B.
A significant effort was also devoted to enhancing the model’s reasoning capabilities. One of the key focus areas during training was to minimize the model’s tendency to “hallucinate” or generate plausible-sounding but factually incorrect or irrelevant information. This was achieved by fine-tuning the model to be more cautious and discerning in its responses, ensuring that it provides reliable and accurate outputs.
Additionally, the new Mistral Large 2 is trained to acknowledge when it cannot find solutions or does not have sufficient information to provide a confident answer. This commitment to accuracy is reflected in the improved model performance on popular mathematical benchmarks, demonstrating its enhanced reasoning and problem-solving skills:
Performance accuracy on code generation benchmarks (all models were benchmarked through the same evaluation pipeline)
Performance accuracy on MultiPL-E (all models were benchmarked through the same evaluation pipeline, except for the "paper" row)

Performance accuracy on GSM8K (8-shot) and MATH (0-shot, no CoT) generation benchmarks (all models were benchmarked through the same evaluation pipeline)
Instruction following & Alignment
We drastically improved the instruction-following and conversational capabilities of Mistral Large 2. The new Mistral Large 2 is particularly better at following precise instructions and handling long multi-turn conversations. Below we report the performance on MT-Bench, Wild Bench, and Arena Hard benchmarks:

Performance on general alignment benchmarks (all models were benchmarked through the same evalutation pipeline)
On some benchmarks, generating lengthy responses tends to improve the scores. However, in many business applications, conciseness is paramount – short model generations facilitate quicker interactions and are more cost-effective for inference. This is why we spent a lot of effort to ensure that generations remain succinct and to the point whenever possible. The graph below reports the average length of generations of different models on questions from the MT Bench benchmark:
Language diversity
A large fraction of business use cases today involve working with multilingual documents. While the majority of models are English-centric, the new Mistral Large 2 was trained on a large proportion of multilingual data. In particular, it excels in English, French, German, Spanish, Italian, Portuguese, Dutch, Russian, Chinese, Japanese, Korean, Arabic, and Hindi. Below are the performance results of Mistral Large 2 on the multilingual MMLU benchmark, compared to the previous Mistral Large, Llama 3.1 models, and to Cohere’s Command R+.

Performance on Multilingual MMLU (measured on the base pretrained model)
Tool Use & Function Calling
Mistral Large 2 is equipped with enhanced function calling and retrieval skills and has undergone training to proficiently execute both parallel and sequential function calls, enabling it to serve as the power engine of complex business applications.
Try Mistral Large 2 on la Plateforme
You can use Mistral Large 2 today via la Plateforme under the name mistral-large-2407, and test it on le Chat. It is available under the version 24.07 (a YY.MM versioning system that we are applying to all our models), and the API name mistral-large-2407. Weights for the instruct model are available and are also hosted on HuggingFace.
we are consolidating the offering on la Plateforme around two general purpose models, Mistral Nemo and Mistral Large, and two specialist models, Codestral and Embed. As we progressively deprecate older models on la Plateforme, all Apache models (Mistral 7B, Mixtral 8x7B and 8x22B, Codestral Mamba, Mathstral) remain available for deployment and fine-tuning using our SDK mistral-inference and mistral-finetune.
Starting today, we are extending fine-tuning capabilities on la Plateforme: those are now available for Mistral Large, Mistral Nemo and Codestral.
Access Mistral models through cloud service providers
We are proud to partner with leading cloud service providers to bring the new Mistral Large 2 to a global audience. In particular, today we are expanding our partnership with Google Cloud Platform to bring Mistral AI’s models on Vertex AI via a Managed API. Mistral AI’s best models are now available on Vertex AI, in addition to Azure AI Studio, Amazon Bedrock and IBM watsonx.ai.