As we continue to focus our AI research and development on solving increasingly complex problems, one of the most significant and challenging shifts we’ve experienced is the sheer scale of computation required to train large language models (LLMs).
Traditionally, our AI model training has involved a training massive number of models that required a comparatively smaller number of GPUs. This was the case for our recommendation models (e.g., our feed and ranking models) that would ingest vast amounts of information to make accurate recommendations that power most of our products.

With the advent of generative AI (GenAI), we’ve seen a shift towards fewer jobs, but incredibly large ones. Supporting GenAI at scale has meant rethinking how our software, hardware, and network infrastructure come together.
The challenges of large-scale model training

As we increase the number of GPUs in a job, the likelihood of an interruption due to a hardware failure also increases. Also, all of these GPUs still need to communicate on the same high-speed fabric to perform optimally. This underscores the importance of four factors:
- Hardware reliability: Ensuring that our hardware is reliable is important. We need to minimize the chances of a hardware failure interrupting a training job. This involves rigorous testing and quality control measures, and automation to quickly detect and remediate issues.
- Fast recovery on failure: Despite our best efforts, hardware failures can and do occur. When they do, we need to be able to recover quickly. This involves reducing re-scheduling overhead and fast training re-initialization.
- Efficient preservation of the training state: In the event of a failure, we need to be able to pick up where we left off. This means we need to regularly checkpoint our training state and efficiently store and retrieve training data.
- Optimal connectivity between GPUs: Large-scale model training involves transferring vast amounts of data between GPUs in a synchronized fashion. A slow data exchange between a subset of GPUs can compound and slow down the whole job. Solving this problem requires a robust and high-speed network infrastructure as well as efficient data transfer protocols and algorithms.
Innovating across the infrastructure stack
Perfecting every layer of our infrastructure stack is important due to the demands of GenAI at scale. This has encompassed developments in a wide range of areas.
Training software
We enable researchers to use PyTorch and other new open source developments, facilitating extremely fast research-to-production development. This includes developing new algorithms and techniques for efficient large-scale training and integrating new software tools and frameworks into our infrastructure.
Scheduling
Efficient scheduling helps ensure that our resources are used optimally. This involves sophisticated algorithms that can allocate resources based on the needs of different jobs and dynamic scheduling to adapt to changing workloads.
Hardware
We need high-performance hardware to handle the computational demands of large-scale model training. Beyond size and scale, many hardware configurations and attributes need to be best optimized for GenAI. Given that hardware development times are traditionally long, we had to adapt existing hardware, and to this end we explored various dimensions including power, HBM capacity and speed, and I/O.
We also pivoted by modifying the Grand Teton platform that was developed using NVIDIA H100 GPUs, increased the TDP of the GPUs to 700W, and moved to HBM3 on the GPUs. Since we did not have time to change the cooling infrastructure, we had to remain in an air-cooled environment. The mechanical and thermal designs had to change to accommodate this, and that triggered a validation cycle to support a large-scale deployment.
All of these hardware-related changes were challenging because we had to find a solution that fit within the existing resource constraints, with a very small degree of freedom to change and meet a tight schedule.
Data center deployment
Once we’ve chosen a GPU and system, the task of placing them in a data center for optimal usage of resources (power, cooling, networking, etc.) requires revisiting trade-offs made for other types of workloads. Data center power and cooling infrastructure cannot be changed quickly (or easily) and we had to find an optimal layout that allowed maximum compute capability within a data hall. This required relocating supporting services such as readers out of the data hall and packing as many GPU racks as possible to maximize the power and network capability for highest compute density with the largest network cluster.
Reliability
We need to plan for detection and remediation to minimize downtime during hardware failures. The number of failures scales with the size of the cluster, and having a job that spans the cluster makes it necessary to keep adequate spare capacity to restart the job as soon as possible. In addition, we monitor failures and can sometimes take preventive measures to mitigate downtime.
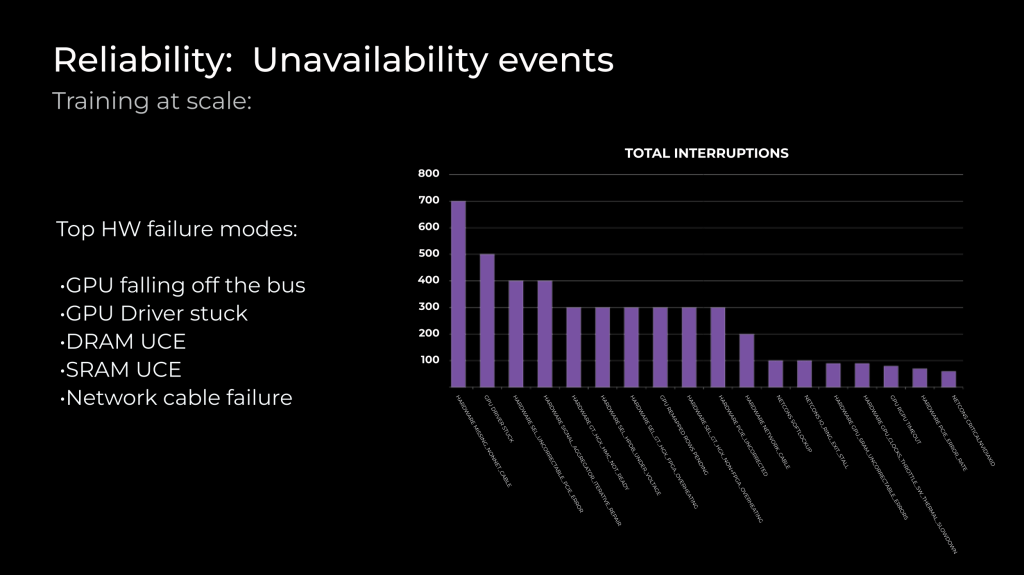
Some of the most frequent failure modes we have observed are:
- GPUs falling off: In this case, GPUs are not detected by the host on PCIe. There are several reasons for this failure, but this failure mode is seen more in the early life and settles as the server ages.
- DRAM & SRAM UCE: Uncorrectable errors are common in memories, and we monitor and identify repeat offenders, track against thresholds, and initiate RMAs when error rates exceed vendor thresholds.
- HW network cable: In the general category of unreachable servers, these failures are also seen most often in the early life of the server.
Network
Large-scale model training involves transferring vast amounts of data quickly between GPUs. This requires robust and high-speed network infrastructure as well as efficient data transfer protocols and algorithms.
There are two leading choices in the industry that fit these requirements: RoCE and InfiniBand fabrics. Both of these options had tradeoffs. On the one hand, Meta had built RoCE clusters for the past four years, but the largest of those clusters only supported 4K GPUs. We needed significantly larger RoCE clusters. On the other hand, Meta had built research clusters with InfiniBand as large as 16K GPUs. However, those clusters were not tightly integrated into Meta’s production environment, nor were they built for the latest generation of GPUs/networking. This made for a difficult decision of what fabric to build with.
So we decided to build both: two 24k clusters, one with RoCE and another with InfiniBand. Our intent was to build and learn from the operational experience. These learnings will inform the future direction of GenAI fabrics. We optimized the RoCE cluster for quick build time, and the InfiniBand cluster for full-bisection bandwidth. We used both InfiniBand and RoCE clusters to train Llama 3, with the RoCE cluster used for training the largest model. Despite the underlying network technology differences between these clusters, we were able to tune both of them to provide equivalent performance for these large GenAI workloads

We optimized three aspects of the overall stack to make network communication for GenAI models performant on both clusters:
- We assigned communication patterns resulting from different model, data and pipeline parallelisms to different layers of the network topology so that the network capabilities were effectively exploited.
- We implemented collective communication patterns with network topology awareness so that they can be less latency-sensitive. We do this by changing the default implementation of collectives with custom algorithms such as recursive doubling or halving instead of conventional algorithms like rings.
- Just like ranking jobs, GenAI jobs produce additional fat flows that make it hard to distribute traffic across all possible network paths. This required us to further invest in network load balancing and routing to achieve an optimal distribution of traffic across network resources.
We spoke in depth about our RoCE load-balancing techniques at Networking @Scale 2023.
Storage
We need efficient data-storage solutions to store the vast amounts of data used in model training. This involves investing in high-capacity and high-speed storage technologies and developing new data-storage solutions for specific workloads.
Looking ahead
In the next few years we will be working with hundreds of thousands of GPUs, handling even larger volumes of data, and dealing with longer distances and latencies. We’ll be adopting new hardware technologies—including newer GPU architectures—and evolving our infrastructure.
These challenges will push us to innovate and adapt in ways we can’t fully predict yet. But one thing is certain: We are only at the beginning of this journey. As we continue to navigate the evolving landscape of AI, we remain committed to pushing the boundaries of what’s possible.