
|
|
Zopf means “braid” and it also denotes a medium-size bread type, made with some milk and glazed with yolk, shaped like a braid, traditionally eaten on Sunday.
|
|
|
> Also, I'm not "Jia Tan"! You're just going to have to trust me on both of those claims. :-/ No need to trust – it's actually easily verified :) Your activity pattern (blue) is entirely different than jia tan's (orange): https://i.k8r.eu/vRRvVQ.png (Each day is a row, each column is an hour in UTC. A pixel is filled if a user made a commit, wrote a comment, etc during that hour) |
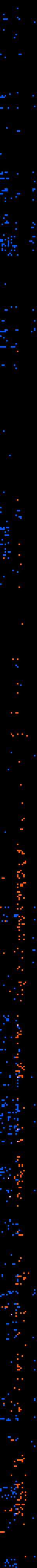{kind=link}
|
|
> Their claims about Jpegli seem to make WebP obsolete regarding lossy encoding? Similar compression estimates as WebP versus JPEG are brought up. I believe Jpegli beats WebP for medium to high quality compression. I would guess that more than half of all WebP images on the net would definitely be smaller as Jpegli-encoded JPEGs of similar quality. And note that Jpegli is actually worse than MozJPEG and libjpeg-turbo at medium-low qualities. Something like libjpeg-turbo q75 is the crossover point I believe. > Hell, I question if AVIF is even worth it with Jpegli. According to another test [1], for large (like 10+ Mpix) photographs compressed with high quality, Jpegli wins over AVIF. But AVIF seems to win for "web size" images. Though, as for point 2 in your next paragraph, Jpegli is indeed much faster than AVIF. > JPEG XL would've still been worth it though because it's just covering so much more ground than JPEG/Jpegli and it has a streaming decoder like a sensible format geared for Internet use, as well as progressive decoding support for mobile networks. Indeed. At a minimum, JXL gives you another 20% size reduction just from the better entropy coding. [1] https://cloudinary.com/blog/jpeg-xl-and-the-pareto-front |
|
|
> In order to quantify Jpegli's image quality improvement we enlisted the help of crowdsourcing raters to compare pairs of images from Cloudinary Image Dataset '22, encoded using three codecs: Jpegli, libjpeg-turbo and MozJPEG, at several bitrates. Looking further [1]: > It consists in requiring a choice between two different distortions of the same image, and computes an Elo ranking (an estimate of the probability of each method being considered higher quality by the raters) of distortions based on that. Compared to traditional Opinion Score methods, it avoids requiring test subjects to calibrate their scores. This seems like a bad way to evaluate image quality. Humans can tend towards liking more highly saturated colours, which would be a distortion of the original image. If it was just a simple kernel that turned any image into a GIF cartoon, and then I had it rated by cartoon enthusiasts, I'm sure I could prove GIF is better than JPEG. I think that to produce something more fair, it would need to be "Given the following raw image, which of the following two images appears to better represent the above image?" The allowed answers should be "A", "B" and "unsure". ELO would likely be less appropriate. I would also like to see an analysis regarding which images were most influential in deciding which approach is better and why. Is it colour related, artefact related, information frequency related? I'm sure they could gain some deeper insight into why one method is favoured over the other. [1] https://github.com/google-research/google-research/blob/mast... |
|
|
Oh, that's interesting. I typically serve thumbnails at 2x resolution and heavily compressed. Should I try to instead compress them less but serve at 0.5x resolution?
|
|
|
Thanks, I was on the team that did Ultra HDR at Google so I was curious if it was being used here. Didn't see anything in the code though so that makes sense.
|
|
|
Something I've been wondering about with the Ultra HDR format, is why did you add the Google GContainer? As far as I can tell, it doesn't do anything that the MPF part doesn't already.
|
|
|
I can't blame you, my comment originally didn't have the word "linked", I edited that in after I realized the potential misunderstanding. Maybe you saw it before the edit. My bad.
|
|
|
> all decoders will render the same pixels Not true. Even just within libjpeg, there are three different IDCT implementations (jidctflt.c, jidctfst.c, jidctint.c) and they produce different pixels (it's a classic speed vs quality trade-off). It's spec-compliant to choose any of those. A few years ago, in libjpeg-turbo, they changed the smoothing kernel used for decoding (incomplete) progressive JPEGs, from a 3x3 window to 5x5. This meant the decoder produced different pixels, but again, that's still valid: https://github.com/libjpeg-turbo/libjpeg-turbo/commit/6d91e9... |
|
|
If you do creative work countless tools just don’t support webp, AVIF or HEIF. It’s so prominent running into files you can’t open in your tools that I have a right click convert to PNG context menu |
|
|
This is work from Google research outside US. You could even call it a different company with the same name. It is Google US who made those AOM / AVIF decisions.
|
|
|
Your posts here seem of the “just asking questions” variety—no substance other than being counterculture. Do you have any proof or resemblance of any logical reason to think this?
|
|
|
By "they" I mean "Google, the organization", not "the authors of this work", who most likely have zero say in decisions concerning Chrome.
|
|
|
Chrome advised and inspired this work in their position about JPEG XL. Here: https://www.mail-archive.com/[email protected]/msg04351... "can we optimize existing formats to meet any new use-cases, rather than adding support for an additional format" It's a yes! Of course full JPEG XL is quite a bit better still, but this helps old compatible JPEG to support HDR without 8-bit banding artefacts or gainmaps, gives a higher bit depth for other uses where more precision is valuable, and quite a bit better compression, too. |
|
|
Despite the answer being yes, IMO it's pretty clear that the question is disingenuous, otherwise why did they add support for WebP and AVIF? The question applies equally to them.
|
|
|
I agree, this is a very exciting direction. We shouldn’t let existing formats stifle innovation, but there is a lot of value in back porting modern techniques to existing encoders.
|
|
|
I believe guetzli is slightly more robust around quality 94, but jpegli likely better at or equal at lower qualities like below 85. Jpegli is likely about 1000x faster and still good.
|
|
|
Does anyone have compiled this to WASM? I'm currently using MozJPEG via WASM for a project and would love to test replacing it by Jpegli.
|
|
|
> These heuristics are much faster than a similar approach originally used in guetzli. I liked guetzli but it's way too slow to use in production. Glad there is an alternative. |
|
|
Feels like I'm quite wrong when I said (and got flagged for saying), "Gonna cause quite the firestorm, creating something new everyone will be expected to support and maintain, after Google balked at bringing in jpegxl because they would have to support it." I still really find the messaging here to be awful. There's tons of comments asking how this related to JXL. @JyrkAlakuijala chimes in in https://news.ycombinator.com/item?id=39921484 that yes it uses JXL techniques, but also it's just using that repo because it had infrastructure which was easy to get started with (absolutely cannot argue with that). I'm not sure what my ask is, but this felt like a really chaotic release. It's unclear how much good from JPEG XL got chopped off. I'm glad for the iteration, this just seemed really chaotic & unexpected, & NIMBY-istic. |
|
|
8-bit JPEG actually uses 12-bit DCT coefficients, and traditional JPEG coders have lots of errors due to rounding to 8 bits quite often, while Jpegli always uses floating point internally.
|
|
|
Google sure did a shitty job of explaining the whole situation. JpegXL was kicked out. This thing is added, but the repo and code seems to be from jxl. I'm very confused. |
|
|
Not to mention that it's 35% more efficient than existing encoders, and can support 10+ bits per component encoding while remaining compatible with existing decoders. That's pretty amazing.
|