Over the past few months, through activities such as MiMo Orbit and the Quadrillion Token Creator Incentive Program, we have enabled more people to experience MiMo and solve real problems - this is the first step for MiMo on the path to large-scale application.
Now, with the continuous improvement of underlying technologies, we can finally do something more thorough - permanently renovate the entire model pricing system.
Quick Overview of the Core of This Announcement:
-
MiMo-V2.5 Series API Permanent Price Reduction
-
Token Plan billing system optimization, with usage increased to 5-8 times the original
-
The Creator Incentive Program for Quadrillion Tokens Concludes Successfully
-
Full reset of the current effective Token Plan user quota
Effective Time: 0:00, May 27, 2026, Beijing Time
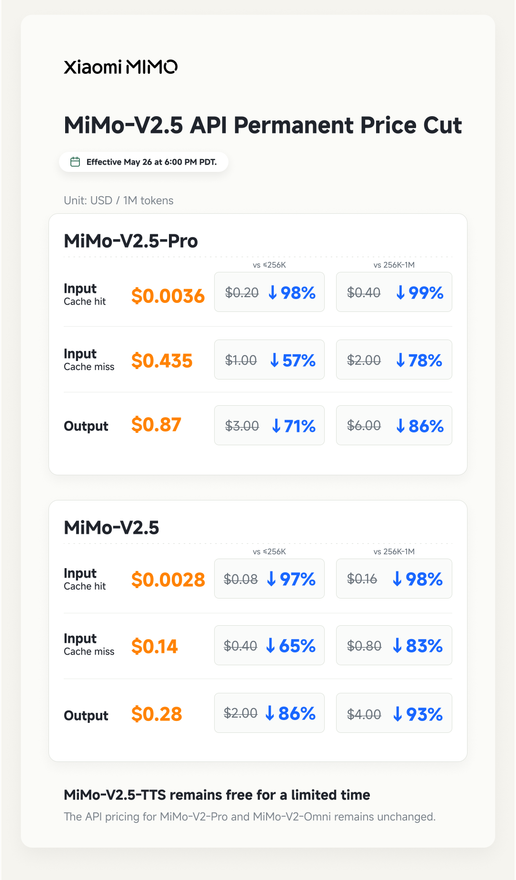
MiMo-V2.5 Series API Permanent Price Reduction
Compared to the original API pricing, the new pricing can have a maximum reduction of up to 99%, and no longer differentiates based on the input length.

This price adjustment officially takes effect at 0:00 on May 27th, Beijing time, with global synchronization. We sincerely invite all developers to integrate and experience it.
Optimization of TokenPlan Billing System
-
Increase the quantity without increasing the price, with the usage volume increased to 5-8 times the original, unlocking more abundant productivity for you
-
Billing rules have been adjusted to be clearer, more understandable, and what you see is what you get.

The Creator Incentive Program for Quadrillion Tokens Concluded Successfully
Since its launch on April 28, the "Trillion Token Creator Incentive Program" has been enthusiastically pursued and widely followed by users worldwide. As of 16:08 on May 26, Beijing Time, all 100T Tokens have been fully distributed ahead of schedule, and the event has concluded successfully ahead of schedule. We thank all developers for their enthusiastic participation!
Note: The exclusive welfare activities for members of the Apache Software Foundation are valid for a long term, can continue to be applied for, and are not affected by this finalization.

Surprise: All existing TokenPlan user quotas have been fully reset
Regardless of the current usage of the package, the Credits quota of all users who have subscribed to the Token Plan and are still within the validity period (including users who participated in the Quadrillion Token Creator Incentive Program and obtained the Token Plan, covering users with exclusive benefits from the Apache Software Foundation) will be fully reset at 0:00 on May 27th, Beijing Time, and implemented according to the new billing rules.
One More Thing: For historical paid users whose Token Plan has expired, we have also prepared surprise gifts, which will be announced within the next week. Please stay tuned.
Optimization Instructions for Inference Technology
Behind this price adjustment is the continuous optimization of the inference system by Xiaomi's technical team.
We fully support SWA (Sliding Window Attention) based on SGLang HiCache, reducing the data transfer volume of KV Cache among multi-level storage such as GPU memory, CPU memory, and SSD to nearly 1/7 of that before optimization, and increasing the number of cacheable tokens to nearly 5 times of that before optimization, significantly improving cache hit rate and inference efficiency.
Meanwhile, we further enhanced the input throughput capacity of the cluster by optimizing the expert parallelism scheme, input length bucketing strategy, etc., thereby continuously reducing the service cost per token while ensuring service quality.
Conclusion
The value of technology ultimately lies in the breadth of its use.
Relying on continuous technological innovation, we hope to leverage real, sustainable, and large-scale inference demand by providing model services that combine low cost with top-notch capabilities, thereby promoting the construction of a complete AI infrastructure chain.
Enabling more people to use better models - this is MiMo's unwavering mission.