罗宾·斯隆讨论了最近发布的Gemini 3.1 Flash-Lite,称赞其速度、价格和视觉能力——特别是将其集成到更大系统中的潜力,而非直接对话。他指出谷歌持续关注广泛的“通用”智能,这与Anthropic和OpenAI对编码代理的侧重形成对比。 然而,斯隆对谷歌快速淘汰Gemini 3 Pro感到沮丧,强调了依赖外部托管模型的不可靠性。虽然自托管提供了一种解决方案,但目前的选项缺乏Gemini强大的视觉处理能力。他预计这种情况很快就会改变。 这篇来自斯隆个人博客的文章强调了对隐私和速度的承诺,这与印刷品的特性相符。他鼓励读者订阅他的新闻通讯以获取更新。
一个黑客新闻的讨论强调了谷歌Gemini人工智能的强大能力,特别是它准确转录手写数据的能力。一位用户分享说,Gemini完美地将一份混乱、未对齐的包含50名IT学生笔迹的考勤表转换成了一个完美的电子表格——这是Copilot无法处理的任务。
这一成功引发了关于什么真正定义通用人工智能(AGI)的讨论。评论员指出Gemini在各种任务中持续改进,超越了单纯的代码辅助,并质疑一旦AGI到来,我们将如何识别和利用它。另一位来自行业内部的人士评论确认Gemini拥有“最佳”的视觉理解能力,并且目前正在生产应用中使用。这场讨论表明Gemini是朝着更“通用”的人工智能能力迈出的重要一步。
因为算法用语
Because Algospeak
12 分钟前
## 互联网与语言的演变:摘要 格雷琴·麦卡洛的《因为互联网》和亚当·亚历西克的《算法语言》都探讨了互联网如何塑造语言,但采用了不同的方法。麦卡洛从历史和语言学的角度出发,追溯了在线交流的演变,从早期的BBS系统到表情符号,认为互联网复兴了曾被正式规范边缘化的非正式书写。她将表情符号视为手势,是现代书面语言不可或缺的一部分。 然而,亚历西克则侧重于社交媒体*算法*的控制性影响。《算法语言》详细描述了平台如何优先考虑广告收入,迫使用户开发编码语言(例如,用“unalive”代替自杀),以逃避内容审核。他强调了Vine甚至在线“incel”社群等平台,作为新俚语出人意料的生产源。 虽然两人都承认互联网的影响,但亚历西克的作品更具批判性,揭示了算法如何对用户进行分类和营销,可能扼杀真正的个性。他甚至注意到人们在语音表达上承受着模仿MrBeast等成功内容创作者的压力。最终,《算法语言》激起了评论员的愤怒,促使人们希望出现像Mastodon和Bluesky这样的去中心化社交媒体平台,在那里语言可以自由地、摆脱算法控制地有机演变。
黑客新闻 新 | 过去 | 评论 | 提问 | 展示 | 招聘 | 提交 登录
因为 Algospeak (tbray.org)
7 分,来自 zdw 1小时前 | 隐藏 | 过去 | 收藏 | 讨论 帮助
指南 | 常见问题 | 列表 | API | 安全 | 法律 | 申请 YC | 联系
搜索:
这是威廉·吉布森广受好评的“蔓延三部曲”——《神经漫游者》、《零计数》和《蒙娜丽莎超载》——的数字版本,由Voyager出版社于1991年作为其“扩展图书项目”的一部分发布。该项目旨在优化在电脑屏幕上的阅读体验,侧重于排版和数字出版细节。 这个特定版本包含吉布森之前未发表的一篇后记。它最初以1.4MB软盘的形式分发给Macintosh电脑(68k架构,System 6.0.7或更高版本,需要HyperCard 2.1)。 安装过程包括挂载磁盘镜像、提取文件并将字体复制到System文件夹。书本身通过一个名为“The Library”的应用程序访问,但它们按字母顺序显示,而非按时间顺序。现代用户可以通过Basilisk II等模拟软件访问它。
黑客新闻 新的 | 过去的 | 评论 | 提问 | 展示 | 工作 | 提交 登录
新的 HyperCard 发现:神经漫游者 / 零计数 / 蒙娜丽莎过载 (macintoshgarden.org)
15 分,由 naves 43 分钟前发布 | 隐藏 | 过去的 | 收藏 | 1 条评论 帮助
latchkey 7 分钟前 [–]
哇。.sea 后缀,很久没想起来了。回复
指南 | 常见问题 | 列表 | API | 安全 | 法律 | 申请 YC | 联系
搜索:
谷歌将于2027年4月停止Widevine云许可服务。
Google to Discontinue Widevine Cloud License Service in April 2027
15 分钟前
Widevine 的 CLS 是 Google 提供的免费服务,供 Widevine 许可方生成 DRM 许可证。此服务端点允许内容分发商使用 Google 的基础设施,而不是完全运营自己的 Widevine 许可服务器或与第三方 DRM 供应商合作。对于一些人来说,这是一个便捷的入口——但它也有一些权衡:作为免费服务,无法获得支持和有价值的功能。或者,Google 还向许可方提供“Widevine 许可服务器 SDK”,以便在他们自己的基础设施上执行 100% 的端到端 DRM 许可证生成/交付——无需与 Widevine CLS 通信。许多第三方云多 DRM 提供商已经在使用此 SDK——这也使他们能够提供改进的服务级别和优势。例如,以下是使用 Widevine CLS 与使用具有 Widevine 许可服务器 SDK 的托管 DRM 提供商(如 DRMtoday)之间的差异:
## Google 将结束 Widevine 云服务 - 影响不大
Google 宣布将于 2027 年 4 月停止其免费的 Widevine 云许可服务,但这预计不会对 DRM(数字版权管理)产生重大影响。Widevine 本身仍将可用;用户可以使用第三方提供商或托管自己的服务器。
评论员指出,Google 的服务缺乏支持协议,这意味着严肃的 DRM 实现已经依赖于替代方案。一些人认为该公告是对这些第三方服务的营销。
讨论还集中在现代 DRM 的徒劳上。尽管 DRM 复杂且会影响合法用户(限制内容质量,需要特权系统访问),但它始终无法阻止盗版。批评者认为 DRM 主要是一种“安全剧场”——一种为了满足许可要求而采取的表演性措施,而不是真正的安全解决方案。最终,DRM 持续存在的原因在于谷歌和苹果等公司继续支持它。
## AI生成代码的信任挑战 随着像Claude这样的人工智能代理越来越多地自主编写代码,一个关键问题出现了:我们如何*知道*代码是正确的?传统的代码审查难以跟上变化的数量,而依赖人工智能来测试其自身的工作会形成自我验证的循环,从而忽略了根本的误解。 解决方案不是增加审查员,而是回归测试驱动开发(TDD)的核心原则:**在编写代码*之前*定义什么是“正确”的。** 工程师不应提示解决方案,而应首先编写清晰、具体的**验收标准**——对所需功能的纯英文描述(例如,“用户在凭据错误时看到‘无效的电子邮件或密码’”)。 然后,人工智能可以根据这些标准构建,并使用自动化验证(例如,对于前端使用Playwright,对于后端使用`curl`)可以严格地针对这些标准进行测试。这会将审查重点从复杂的差异转移到简单的通过/失败报告,仅突出实际的失败。 虽然这不能消除所有错误(不正确的规范仍然会产生有缺陷的结果),但它通过捕获集成问题并确保代码按*预期*运行,从而显著提高可靠性,从而提供了一种比仅仅依赖人工智能驱动的代码审查更可靠的方法。像`opslane/verify`这样的工具使用Claude和Playwright简化了这个过程。
## AI 生成代码与测试挑战
一则 Hacker News 讨论围绕使用 AI(特别是 Claude)编写代码*和*测试的陷阱。核心问题在于,AI 生成的测试往往只是确认 AI 自身的工作(“测试剧场”),缺乏真正的验证。
多位用户建议了一些缓解策略,包括采用“红-绿-重构”方法,并使用专门负责每个阶段的 AI 子代理,以及利用不同的 LLM(如 Gemini 和 Codex)进行代码生成和审查,以引入不同的视角。
一个突出的挑战是 AI 产生的代码量巨大,使得彻底的人工审查变得困难。 提出的解决方案包括自动化验证工具(如作者的 [verify skill](https://github.com/opslane/verify))、用于针对外部服务进行测试的“数字孪生”,以及更严格的文件权限控制,以防止 AI 修改测试。
最终,对话指向了一种思维方式的转变——关注清晰的规范和*对照*这些规范进行验证,而不是仅仅依赖 AI 生成的测试。 越来越担心优先考虑速度而非正确性可能会导致软件越来越不可靠。
 油价在特朗普总统暗示与伊朗潜在冲突可能迅速结束的言论后,经历了剧烈波动。布伦特原油期货从接近120美元/桶暴跌至83美元,随后部分回升至91-95美元区间。这种剧烈波动是由市场猜测特朗普正在寻求一条“脱离困境”之路——一些人称之为“TACO”——所驱动,原因是汽油价格上涨。
油价下跌与七国集团关于石油供应的讨论以及霍尔木兹海峡油轮运输持续的报告同时发生。虽然没有单一因素占据主导地位,但市场情绪对新闻标题反应强烈。
分析师指出,如果局势缓和,担心错过潜在的反弹,特别是考虑到市场此前已经为最坏情况定价。美国汽油价格飙升——本月上涨19%至3.539美元/加仑——被视为关键驱动因素,可能影响中期选举,并促使央行考虑采取对抗通胀的措施。最终,不确定性仍然占主导地位,市场参与者正在等待下一个催化剂。
油价在特朗普总统暗示与伊朗潜在冲突可能迅速结束的言论后,经历了剧烈波动。布伦特原油期货从接近120美元/桶暴跌至83美元,随后部分回升至91-95美元区间。这种剧烈波动是由市场猜测特朗普正在寻求一条“脱离困境”之路——一些人称之为“TACO”——所驱动,原因是汽油价格上涨。
油价下跌与七国集团关于石油供应的讨论以及霍尔木兹海峡油轮运输持续的报告同时发生。虽然没有单一因素占据主导地位,但市场情绪对新闻标题反应强烈。
分析师指出,如果局势缓和,担心错过潜在的反弹,特别是考虑到市场此前已经为最坏情况定价。美国汽油价格飙升——本月上涨19%至3.539美元/加仑——被视为关键驱动因素,可能影响中期选举,并促使央行考虑采取对抗通胀的措施。最终,不确定性仍然占主导地位,市场参与者正在等待下一个催化剂。
arXivLabs是一个框架,允许合作者直接在我们的网站上开发和分享新的arXiv功能。个人和与arXivLabs合作的组织都认同并接受我们开放、社群、卓越和用户数据隐私的价值观。arXiv致力于这些价值观,并且只与秉持这些价值观的合作伙伴合作。您是否有为arXiv社群增加价值的项目想法?了解更多关于arXivLabs的信息。
黑客新闻 新 | 过去 | 评论 | 提问 | 展示 | 招聘 | 提交 登录
同位素证据表明星际天体 3I/Atlas 起源于寒冷和遥远的地方 (arxiv.org)
11 分,来自 bikenaga 2 小时前 | 隐藏 | 过去 | 收藏 | 1 条评论 帮助
dvh 30 分钟前 [–]
> 碳同位素组成表明 3I/ATLAS 大约在 10-12 亿年前吸积形成回复
指南 | 常见问题 | 列表 | API | 安全 | 法律 | 申请 YC | 联系
搜索:
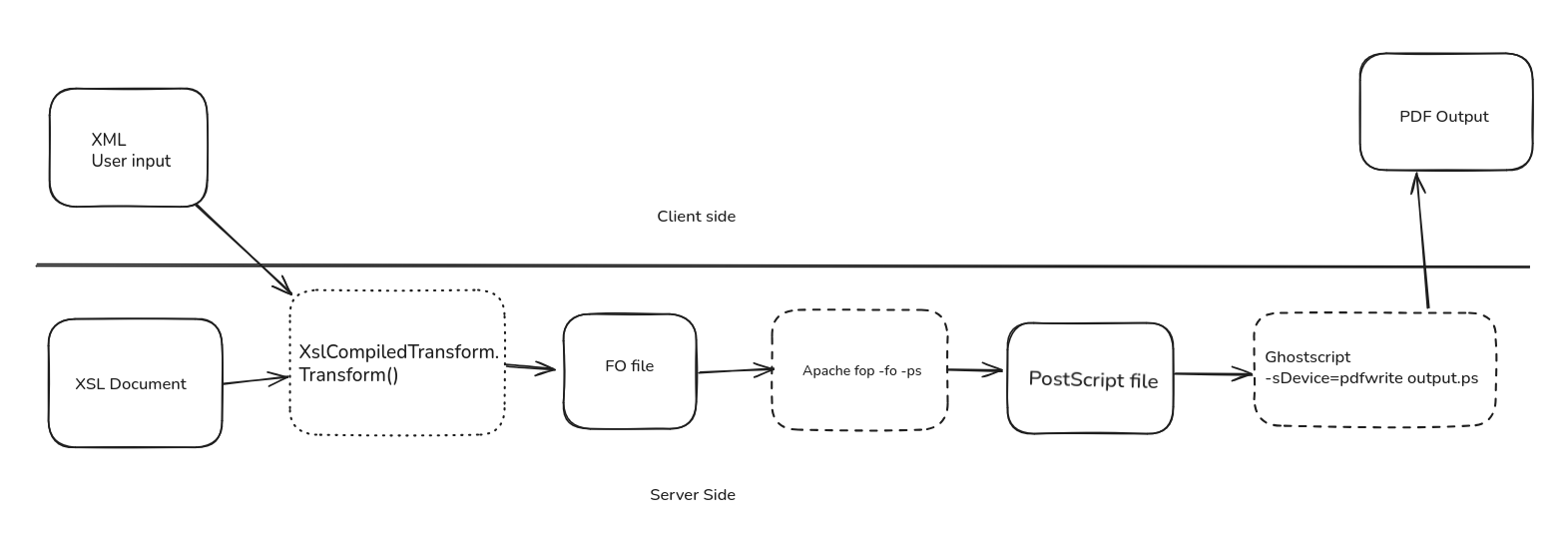 ## Apache FOP & GhostScript 漏洞摘要
一名安全研究人员发现了一个漏洞,该漏洞存在于使用 Apache FOP 将用户提供的 XML 转换为 PostScript,然后使用 GhostScript 生成 PDF 的应用程序中。虽然 GhostScript 包含用于安全性的沙箱,但 FOP 处理用户输入的方式存在缺陷,导致潜在的代码执行。
问题源于生成的 PostScript 代码中字符的转义不足。具体来说,精心构造的 XML 输入可以绕过 FOP 的转义机制并注入任意 PostScript 指令。FOP 的换行功能加剧了这一问题,该功能引入了进一步破坏转义逻辑的换行符。
通过利用这一点,研究人员可以注入诸如 `showpage` 和文件访问指令之类的命令,最终直接从服务器的文件系统中读取敏感文件(例如 Docker 挑战中的 flag)。一个关键的解决方法是使用不间断空格来防止 FOP 分割命令。
虽然完全逃逸沙箱是可能的,但研究人员成功利用该漏洞读取了一个 flag 文件。Apache FOP 不会修复底层问题,而是选择改进有关预期安全属性的文档。研究人员还利用了另一个 Windows 漏洞 (CVE-2025-46646) 以获得更广泛的文件系统访问权限。
## Apache FOP & GhostScript 漏洞摘要
一名安全研究人员发现了一个漏洞,该漏洞存在于使用 Apache FOP 将用户提供的 XML 转换为 PostScript,然后使用 GhostScript 生成 PDF 的应用程序中。虽然 GhostScript 包含用于安全性的沙箱,但 FOP 处理用户输入的方式存在缺陷,导致潜在的代码执行。
问题源于生成的 PostScript 代码中字符的转义不足。具体来说,精心构造的 XML 输入可以绕过 FOP 的转义机制并注入任意 PostScript 指令。FOP 的换行功能加剧了这一问题,该功能引入了进一步破坏转义逻辑的换行符。
通过利用这一点,研究人员可以注入诸如 `showpage` 和文件访问指令之类的命令,最终直接从服务器的文件系统中读取敏感文件(例如 Docker 挑战中的 flag)。一个关键的解决方法是使用不间断空格来防止 FOP 分割命令。
虽然完全逃逸沙箱是可能的,但研究人员成功利用该漏洞读取了一个 flag 文件。Apache FOP 不会修复底层问题,而是选择改进有关预期安全属性的文档。研究人员还利用了另一个 Windows 漏洞 (CVE-2025-46646) 以获得更广泛的文件系统访问权限。
黑客新闻 新的 | 过去的 | 评论 | 提问 | 展示 | 招聘 | 提交 登录
绕过 Apache Fop PostScript 转义以访问 GhostScript (almond.consulting)
5 分,由 notmine1337 发表于 1 小时前 | 隐藏 | 过去的 | 收藏 | 讨论 帮助
指南 | 常见问题 | 列表 | API | 安全 | 法律 | 申请 YC | 联系
搜索:
(Empty input provided. There is nothing to translate.)
## 新推理堆栈声称性能提升
Hacker News上的一篇文章详细介绍了一种新的推理堆栈(“infinity.inc”),声称其性能超越了vLLM。开发者表示,他们的堆栈通过专门针对单个模型进行优化,从而实现了这一目标。
然而,评论者对此表示怀疑,质疑其基准测试方法。一位用户指出缺乏通过相同的输出token概率进行验证,暗示其实现可能与vLLM不同。另一些人批评缺少推测解码,这是一种关键的性能优化手段。
开发者承认推测解码将同样使两个系统受益,并且愿意进行进一步测试。他们表示目前使用MMLU和Hellaswag基准进行验证,并且正在进行独立验证。虽然正在考虑开源部分推理库,但尚未做出决定。目前缺乏关于代码、批处理和量化的更详细信息。
## GPU转码变得简单:ffmpeg-over-ip ffmpeg-over-ip 提供GPU加速的ffmpeg转码,无需GPU直通、共享文件系统或驱动对齐的复杂性。它允许应用程序通过将`ffmpeg`命令替换为`ffmpeg-over-ip-client`,即可利用远程GPU进行媒体服务器转码等任务。 该系统通过在具有GPU访问权限的服务器上运行,并在包含文件的机器上运行客户端来工作。客户端通过单个TCP端口将命令和文件I/O转发到服务器,服务器执行一个补丁后的ffmpeg。重要的是,文件*从不*驻留在服务器上,从而无需NFS、SMB或复杂的挂载。 包含支持NVENC、QSV和其他硬件加速方法的预构建二进制文件,简化了设置。多个客户端可以同时连接到单个服务器,每个客户端都有自己的ffmpeg进程,并受到HMAC身份验证的保护。它是一种简化解决方案,可在Docker、VM和远程机器等各种环境中利用GPU性能。
## FFmpeg-over-IP:远程GPU加速
开发者steelbrain发布了“ffmpeg-over-ip”的更新,该项目允许用户利用远程GPU进行视频处理。该系统允许*没有*GPU的机器使用*具有*GPU的机器(例如游戏笔记本电脑)的处理能力,用于视频转换等任务,从而使Plex、Jellyfin或Emby等应用程序受益。
它通过运行修改后的FFmpeg的服务器(配备GPU)和连接到它的客户端工作。客户端处理文件I/O请求,向服务器上的FFmpeg呈现本地文件系统,使其不知道它正在远程运行。
单个服务器可以为多个客户端提供服务,并包含一个静态FFmpeg构建,以便于设置——只需配置、设置密码即可开始。这解决了之前关于文件系统共享的担忧。该项目旨在简化那些缺乏本地GPU资源的人员的GPU加速视频任务。更多详细信息和常见问题解答可在GitHub仓库中找到。
勒丘恩筹集10亿美元,用于构建理解物理世界的AI。
Yann LeCun raises $1B to build AI that understands the physical world
46 分钟前
## AMI 启动,获得 10 亿美元资金,致力于“世界模型”人工智能 Meta 前首席人工智能科学家 Yann LeCun 在巴黎联合创立了 Advanced Machine Intelligence (AMI),获得了超过 10 亿美元的资金,用于开发人工智能“世界模型”。LeCun 认为,当前人工智能的发展,专注于像 ChatGPT 这样的大型语言模型 (LLM),是实现真正人类水平智能的死胡同。他认为,人工智能需要理解*物理*世界,而不仅仅是语言,才能真正地推理和规划。 AMI 估值 35 亿美元,旨在创建具有持久记忆、可控性和安全性的 AI 系统,目标行业包括制造业、生物医学和机器人技术。该公司将在巴黎、蒙特利尔、新加坡和纽约等地全球运营。 这项举措代表着对 OpenAI 甚至 LeCun 前雇主 Meta 所倡导的 LLM 方法的重大反*对*。虽然承认 LLM 的实用性,但 LeCun 将其视为一种临时趋势,认为世界模型对于真正的人工智能发展至关重要,并且最好独立商业化。他获得了 Zuckerberg 的祝福,离开了 Meta 来追求这一愿景。
 ## Z世代对“觉醒”意识形态的抵触
进步派左翼相信,历代年轻人会完全拥抱“觉醒”意识形态,从而导致彻底的文化转变。然而,这种假设忽视了历史模式——进步运动常常失败,社会会回归以往成功的规范。证据表明,Z世代正在积极抵触现代进步思想的核心原则,尤其是在性别角色和关系方面。
受到一些人认为的数十年单方面宣传的影响——包括 perceived 的反男性偏见、女权主义至上以及优先考虑“结果平等”而非机会——相当一部分 Z世代男性表达不满。调查显示,对传统性别角色的支持度正在增加,57% 的人认为女性权利已经过度,31% 的人同意妻子应该服从丈夫。
这种转变并非归因于边缘的“男性圈”影响,而是对 perceived 的不平衡以及严峻的约会环境的一种反应。虽然媒体试图解释这一趋势,将其归因于孤独或网络回音室,但数据表明,这是一种更广泛的文化反思,由男性重新评估社会期望并寻求更传统的动态所驱动。与此同时,预测表明单身、无子女的女性数量将会增加,这表明权力动态可能发生转变,因为越来越多的男性远离盛行的“觉醒”框架。
## Z世代对“觉醒”意识形态的抵触
进步派左翼相信,历代年轻人会完全拥抱“觉醒”意识形态,从而导致彻底的文化转变。然而,这种假设忽视了历史模式——进步运动常常失败,社会会回归以往成功的规范。证据表明,Z世代正在积极抵触现代进步思想的核心原则,尤其是在性别角色和关系方面。
受到一些人认为的数十年单方面宣传的影响——包括 perceived 的反男性偏见、女权主义至上以及优先考虑“结果平等”而非机会——相当一部分 Z世代男性表达不满。调查显示,对传统性别角色的支持度正在增加,57% 的人认为女性权利已经过度,31% 的人同意妻子应该服从丈夫。
这种转变并非归因于边缘的“男性圈”影响,而是对 perceived 的不平衡以及严峻的约会环境的一种反应。虽然媒体试图解释这一趋势,将其归因于孤独或网络回音室,但数据表明,这是一种更广泛的文化反思,由男性重新评估社会期望并寻求更传统的动态所驱动。与此同时,预测表明单身、无子女的女性数量将会增加,这表明权力动态可能发生转变,因为越来越多的男性远离盛行的“觉醒”框架。
 CNN和其他主流媒体正面临批评,指责其淡化最近纽约市一起未遂爆炸事件。两名青少年,埃米尔·巴拉特和易卜拉欣·卡尤米,在向一场反对“伊斯兰占领纽约市”的抗议活动投掷简易炸弹后被捕。当局证实,该装置包含恐怖袭击中使用的易燃材料,意图造成伤害。
然而,CNN最初将事件描述为对青少年“正常一天”的扰乱,重点关注他们的年龄以及反穆斯林抗议的背景。这引发了愤怒,批评人士指责该网络试图为据称受到ISIS启发的个人制造同情,并淡化潜在恐怖行为的严重性。其他网络据报道也使用了这种同情的描述方式。
这起事件加剧了人们对主流媒体存在偏见和“宣传”的担忧,导致信任度和读者数量下降,尽管这种担忧通常是短暂的。
CNN和其他主流媒体正面临批评,指责其淡化最近纽约市一起未遂爆炸事件。两名青少年,埃米尔·巴拉特和易卜拉欣·卡尤米,在向一场反对“伊斯兰占领纽约市”的抗议活动投掷简易炸弹后被捕。当局证实,该装置包含恐怖袭击中使用的易燃材料,意图造成伤害。
然而,CNN最初将事件描述为对青少年“正常一天”的扰乱,重点关注他们的年龄以及反穆斯林抗议的背景。这引发了愤怒,批评人士指责该网络试图为据称受到ISIS启发的个人制造同情,并淡化潜在恐怖行为的严重性。其他网络据报道也使用了这种同情的描述方式。
这起事件加剧了人们对主流媒体存在偏见和“宣传”的担忧,导致信任度和读者数量下降,尽管这种担忧通常是短暂的。
## AI辅助编程:熟练度等级 人工智能的编程*能力*正在迅速提升,但要充分发挥其*益处*,需要培养有效利用它的技能。这种进步并非追求最高的SWE-bench分数,而是弥合人工智能*能够*做的事情与我们如何*应用*它之间的差距。 作者概述了**八个**AI辅助编程熟练度等级。它从基本的**代码补全**(等级1)等功能开始,逐步发展到利用AI驱动的IDE进行多文件编辑(等级2)。**上下文工程**(等级3)——优化提示的清晰度——至关重要,并演变为**复合工程**(等级4),将经验教训编码为未来会话的规则。 等级5-7通过**定制工具和技能**(MCPs)解锁显著收益,赋予人工智能访问数据库、API和测试框架的权限,并最终**编排后台代理**以自主处理任务。当前的边界,**等级8**,涉及完全自主的代理团队直接协调,但管理复杂性仍然存在挑战。 关键要点是,每一层都建立在上一层之上,通过改进的模型来放大收益。在团队范围内投资熟练度——确保每个人不会被速度较慢的同事拖累——至关重要。未来指向更自然的界面,如语音控制,但核心原则仍然是:迭代开发,由越来越强大和自主的人工智能代理提供支持。
最近一篇Hacker News上的帖子链接到一篇题为“代理工程等级”(bassimeledath.com)的文章,引发了评论区的讨论。文章试图将不同的AI代理工作方法进行分类,但评论员们大多批评这种等级划分的想法。
许多用户认为这种列表会助长不必要的“门槛主义”和负面情绪,并提倡根据个人需求和舒适度来选择工具和技术。一位评论员将其比作软件编译,认为高级控制最终应该由更强大的底层自动处理。另一些人指出,目前对“长上下文”的关注与“Oceania”(可能指一种特定的AI技术)等既定实践相符。
总体情绪倾向于反对等级观念,强调*最好*的方法不一定是*最高*等级,而是最能有效完成当前任务的方法。
## 从废墟中思考:摘要 本文探讨了被殖民和边缘化人民所经历的失败的持久影响,特别关注作者的伊朗巴赫蒂亚里族背景以及石油开采对其土地的影响。作者的父亲传授了一个重要的教训:以“坦然的面孔”面对不可避免的失败——一种保持脆弱和暴露的意愿,拥抱从苦难中获得的知识。 文章借鉴了弗兰茨·法农的作品,认为失败不仅仅是一种被动体验,而是理解世界的一个关键视角。这是那些历史上被殖民力量“摧毁”的人所共有的处境,也是产生独特知识和抵抗形式的催化剂。 作者将这一概念与卡尔巴拉悲剧和特立尼达的霍赛仪式等历史事件联系起来,展示了哀悼和纪念如何成为生存和政治行动的强大工具。最终,文章倡导一种“悲观的希望”——即使在不可能的情况下也要继续斗争——以及一种能够设想在系统性不公正的废墟之外的生活的激进想象力。因此,失败不是终结,而是批判性思考的一种方法和未来可能性基础。
黑客新闻 新 | 过去 | 评论 | 提问 | 展示 | 招聘 | 提交 登录
击败作为方法 (cabinetmagazine.org)
7 分,akbarnama 1小时前 | 隐藏 | 过去 | 收藏 | 讨论 帮助
指南 | 常见问题 | 列表 | API | 安全 | 法律 | 申请YC | 联系
搜索:
 ## 开源机器学习的简单幻觉
一位大学教授的建议——“如果出现错误,那是你的错”——对于大多数软件来说是适用的,但在开源机器学习基础设施方面却不成立。作者在尝试廉价地对Kimi-K2-Thinking(一个拥有1万亿参数的模型)进行后训练时,亲身体验了这一点。尽管Hugging Face上有现成的模型,但一个可用的训练流程却出乎意料地难以实现。
最初使用LLaMA-Factory和Hugging Face的Transformers库的尝试充满了错误,从由于冗余量化导致的无法解释的压缩延迟,到需要一个特定的、未记录的PyTorch设置才能解决GPU内存管理问题。进一步的障碍包括GPU上的权重分布不均匀、LoRA与量化权重的不兼容,以及由于不可微分的MoE门而阻止训练的关键断言错误。
最终,作者实现了训练——尽管速度明显较慢且成本高于使用专用API——方法是绕过抽象层并直接解决底层问题。这次经历凸显了开源ML堆栈中隐藏的“债务”,错误可能潜藏在深层的依赖关系中。虽然开源旨在 democratize AI,但作者认为,构建可靠的基础设施通常需要放弃修补,转而拥抱定制开发。
## 开源机器学习的简单幻觉
一位大学教授的建议——“如果出现错误,那是你的错”——对于大多数软件来说是适用的,但在开源机器学习基础设施方面却不成立。作者在尝试廉价地对Kimi-K2-Thinking(一个拥有1万亿参数的模型)进行后训练时,亲身体验了这一点。尽管Hugging Face上有现成的模型,但一个可用的训练流程却出乎意料地难以实现。
最初使用LLaMA-Factory和Hugging Face的Transformers库的尝试充满了错误,从由于冗余量化导致的无法解释的压缩延迟,到需要一个特定的、未记录的PyTorch设置才能解决GPU内存管理问题。进一步的障碍包括GPU上的权重分布不均匀、LoRA与量化权重的不兼容,以及由于不可微分的MoE门而阻止训练的关键断言错误。
最终,作者实现了训练——尽管速度明显较慢且成本高于使用专用API——方法是绕过抽象层并直接解决底层问题。这次经历凸显了开源ML堆栈中隐藏的“债务”,错误可能潜藏在深层的依赖关系中。虽然开源旨在 democratize AI,但作者认为,构建可靠的基础设施通常需要放弃修补,转而拥抱定制开发。
一场 Hacker News 的讨论集中在大型语言模型 (LLM) 的“开放权重”是否真正符合“开源”的定义。oscarmoxon 的核心观点是,发布模型权重类似于分发编译后的二进制文件——可用且可检查,但无法像真正的开源软件那样从头开始重现或扩展。
这种区别很重要,因为真正的开源依赖于可重现性和民主化的迭代,需要访问*整个*训练过程。虽然训练的计算成本正在降低,但一个重要的隐藏成本在于扩展这些模型所需的未记录基础设施。
其他人指出,即使*编译*(训练)LLM 的源代码成本也很高,使得二进制编辑更实用。然而,即使不进行修改,访问训练数据和模型架构(“源代码”的等效物)也提供了好处,例如安全审计、理解偏差以及为有效的应用策略提供信息。
## Autonoma 的彻底转型:从头重写 经过 1.5 年的开发和多次转型(企业搜索、代码代理、质量保证测试),Autonoma 正在重建其产品,尽管最近获得了客户和资金。 核心原因? 最初的一个令人遗憾的决定,即为了速度而牺牲代码质量,放弃测试和严格的 TypeScript。 最初,“无测试”的方法对于小型团队来说是可行的,但迅速导致了充满错误且难以维护的代码库,最终导致失去了一个客户。 认识到造成的损害,Autonoma 现在正在采用测试驱动开发方法,并使用严格的 TypeScript。 这次重写还涉及重大的技术栈转变。 他们正在放弃 Next.js 及其存在问题的服务器动作——引用了异步行为、测试困难和全局顺序执行的问题——转而使用 React 与 tRPC 以及 Hono 后端,以提高效率和降低成本(将资源使用量从 8GB 降低到接近免费)。 编排由 Kubernetes 原生的 Argo 处理,因为它在管理复杂的状态化工作流方面具有可靠性和可扩展性。 虽然具有挑战性,但这种方法避免了像 useworkflow.dev 和 Temporal 这样较新的工作流工具的限制。 Autonoma 欢迎反馈,并计划在几周内发布新产品。
一篇 Hacker News 帖子详细描述了一位开发者放弃了 18 个月的工作并重新开始一个项目 (tompiagg.io)。讨论迅速转向批评,评论者对这种情况表示难以置信。
一个关键点是项目缺乏测试文化,被一位用户认为是“疯狂的”。其他人则将失败归因于 Node.js 生态系统中的问题,特别是缺乏像 Rails 或 Django 这样全面的框架。
该帖子还引发了关于领导力和能力的争论,一位评论员表示,鉴于反复失败和公开承认重大错误,他不会信任这位开发者领导项目。总体基调是对开发者方法和公开讨论项目崩溃的意愿的严厉批评。
## 民主化企业知识:企业上下文层 构建一个全面、自我更新的公司知识库——“企业上下文层”(ECL)—— 令人惊讶地是可以实现的。尽管围绕复杂解决方案(如知识图谱)存在炒作,但最近的实验表明,仅使用 1,000 行 Python 代码和一个 GitHub 仓库就能取得成功。 挑战在于超越简单的文档检索,去*理解*公司的细微差别:产品消歧、发布细节、内部流程和冲突信息。现有的解决方案难以实现这种整体视图。 关键在于使用 AI 代理映射组织的各个方面——产品、人员、流程——并且至关重要的是,为每个声明*引用来源*,创建一个可追溯、可验证的知识库。这种方法不追求可读性,而是追求准确性和上下文。 该实验涉及 20 个代理生成 6,000 次提交,跨 1,020 个文件,映射从客户旅程到功能标志清单的所有内容。 结果系统超越了现有的检索系统,甚至可以识别出最适合路由到专业团队的敏感问题。 这并非一个产品,而是一种实践——所有公司内部 AI 代理的基础层,由机器构建和维护,并且随着 LLM 的改进而日益普及。 未来设想将从定制 AI 代理转向利用共享的、机器维护的上下文层来获取所有组织知识。
黑客新闻 新 | 过去 | 评论 | 提问 | 展示 | 招聘 | 提交 登录
企业上下文层 (andychen32.substack.com)
11 分,来自 zachperkel 1 小时前 | 隐藏 | 过去 | 收藏 | 讨论 帮助
指南 | 常见问题 | 列表 | API | 安全 | 法律 | 申请 YC | 联系
搜索:
## “氛围编码员”的变现问题 当前人工智能驱动的创作工具的一个关键问题是,虽然它们赋能了一批新的“氛围编码员”——那些无需传统编程即可构建应用程序的个人,但它们常常使变现变得复杂且昂贵。这些创作者面临着大量的“金融科技细节”和高昂的订阅费用(成功的课程可能每年超过10万美元),仅仅为了处理支付和基本的业务功能。 作者建议从传统的SaaS定价模式转向**基于成果的收入分成**。平台(如Lovable)可以不收取月费,而是抽取创作者收入的一部分(5-30%),从而使双方的激励目标保持一致,实现共同成功。这种模式将解锁对关键基础设施的访问——简化的支付、订阅管理、支持——这些目前对许多创作者来说是难以企及的。 “Lovable合作伙伴计划”可以提供白手套服务,随着成功而扩展支持,甚至提供迁移协助。重要的是,这些服务将产生有价值的数据,为平台创造复利优势,并改进其为所有用户提供的服务。最终目标?赋能氛围编码员建立繁荣的企业,并有可能向创作者支付10亿美元。这种方法认识到,未来属于那些优先考虑无摩擦变现和共享成功的平台。
这场 Hacker News 讨论的核心是人工智能和代理工具的成果定价模式。发帖者链接了一篇文章,建议这些工具的价格应根据其交付的结果来确定。
一位名为“doctor_love”的评论者提出了一种激进的转变:一个平台,专注于奖励“氛围编码者”,并将其收益与他们的成功挂钩,可能旨在分配 10 亿美元。他们认为这能将平台增长与构建者的收入结合起来,但也承认公司最终会优先考虑收入,而不仅仅是客户的成功。
另一位用户质疑这种模式的可持续性,想知道提议者是否会将相同的“按绩效付费”结构应用于*他们*的客户,以及这样的系统最终会导致何处。这场对话凸显了真正分享成功与通过传统方法(例如无论用户结果如何都销售工具)来最大化利润之间的紧张关系。
几个世纪以来,人类通过神秘主义解释未知,然后过渡到科学——寻求像E=mc²这样简洁的解释。这对于可以分解为可理解部分的“复杂”系统来说效果非常好,但在气候变化或经济等真正“复杂”的系统中却失效了,因为这些系统的相互作用*创造*了行为。圣菲研究所几年前就意识到了这一点,发现了复杂系统中的模式,但缺乏*利用*这些知识的工具。 如今的AI,特别是大型语言模型,提供了一个突破。与之前的尝试不同,这些模型之所以*有效*,是因为它们能够容纳表示复杂性所需的大量数据——仅靠笔和纸是无法做到的。模型*就是*理论,尽管是一个庞大的理论。 虽然这似乎与简洁优雅理论的理想相矛盾,但这些模型的底层*架构*——例如Transformer——却非常紧凑,并展现了跨越不同领域的潜力。通过“机制可解释性”研究这些训练好的模型,可能会揭示压缩本身*内部*的基本真理,从而提供一种新的理解途径。这表明过去无法解决的问题并非无法解决,而是超出了我们的理论媒介。我们正在从寻求因果机制转向构建预测模拟,接受概率置信度而不是确定性输出——这是对复杂世界的一种新的认知方式。
一场在Hacker News上的讨论围绕着“数十亿参数理论”——复杂的模型,通常是大型神经网络——以及它们的大小是否真的*必要*来理解世界。
worldgov.org的初始帖子引发了争论,一些人认为更简单的理论通常可以有效地捕捉核心现象(以全球变暖为例)。另一些人则捍卫复杂模型的价值,指出它们在生物学等领域的应用,并承认圣菲研究所的贡献,尽管在实际应用方面存在挑战。
评论员还涉及了历史背景,指出连接主义模型部分是作为对乔姆斯基语言理论的回应而产生的。 进一步讨论的点包括降维技术简化复杂模型的潜力、我们的认知偏差对建模的影响,以及对过度依赖复杂解决方案可能导致忽视重要主题的担忧。 最终,这场对话质疑了追求“完美”知识是否 оправдывает 越来越复杂的理论方法。
比特币 vs 黄金:ETF 资金流显示出早期资本轮动迹象
Bitcoin Vs Gold: ETF Flows Point To Early Capital Rotations Signs
2 小时前
 最近的ETF趋势表明,投资者偏好可能从黄金转向比特币。在价格下跌后,黄金ETF经历了30亿美元的大幅流出——超过两年来最大的一次,而比特币ETF在过去30天内净流入2.73亿美元。这扭转了之前的流出局面,表明对比特币的兴趣正在增长。
分析师指出,黄金和比特币之间存在一种历史模式,即两者轮流领先于表现。过去九个月,黄金获得了显著收益,但其势头现在似乎正在减弱。相反,随着美国经济的改善和风险情绪的上升,比特币有望实现潜在增长。
尽管持续的地缘政治紧张局势仍然支持黄金作为避风港,但富达数字资产的克里斯·奎珀和林·阿尔登等专家预测,未来2-3年比特币将跑赢黄金,类似于过去的周期。然而,建立持续的趋势可能需要时间,就像比特币2022年触底后经历的21周盘整期一样。
最近的ETF趋势表明,投资者偏好可能从黄金转向比特币。在价格下跌后,黄金ETF经历了30亿美元的大幅流出——超过两年来最大的一次,而比特币ETF在过去30天内净流入2.73亿美元。这扭转了之前的流出局面,表明对比特币的兴趣正在增长。
分析师指出,黄金和比特币之间存在一种历史模式,即两者轮流领先于表现。过去九个月,黄金获得了显著收益,但其势头现在似乎正在减弱。相反,随着美国经济的改善和风险情绪的上升,比特币有望实现潜在增长。
尽管持续的地缘政治紧张局势仍然支持黄金作为避风港,但富达数字资产的克里斯·奎珀和林·阿尔登等专家预测,未来2-3年比特币将跑赢黄金,类似于过去的周期。然而,建立持续的趋势可能需要时间,就像比特币2022年触底后经历的21周盘整期一样。
丑陋的3年期拍卖尾部大幅下滑,竞标不足以弥补跌幅。
Ugly 3Y Auction Tails Most Since Liberation Day, Bit to Cover Slides
2 小时前
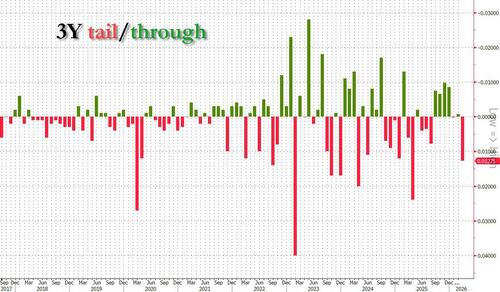 最近美国财政部对580亿美元3年期国债的拍卖被认为疲软,尽管国际新闻持续受到关注。最高收益率达到3.579%,略高于上月,但拍卖“尾部下沉”——意味着需求低于拍卖前市场的预期——幅度为1.1个基点,为自8月以来的最大差距。
投资者需求低迷,体现在较低的投标覆盖率(2.546,低于2.624)和外国参与度下降(59.8%的债券由间接竞标者获得)。交易商持有的债券比例高于往常(19.5%),表明整体需求疲软。
虽然令人失望的结果*可能*与最近的股市上涨有关,但未来拍卖持续疲软可能预示着对国债需求的更广泛担忧。
最近美国财政部对580亿美元3年期国债的拍卖被认为疲软,尽管国际新闻持续受到关注。最高收益率达到3.579%,略高于上月,但拍卖“尾部下沉”——意味着需求低于拍卖前市场的预期——幅度为1.1个基点,为自8月以来的最大差距。
投资者需求低迷,体现在较低的投标覆盖率(2.546,低于2.624)和外国参与度下降(59.8%的债券由间接竞标者获得)。交易商持有的债券比例高于往常(19.5%),表明整体需求疲软。
虽然令人失望的结果*可能*与最近的股市上涨有关,但未来拍卖持续疲软可能预示着对国债需求的更广泛担忧。
启用 JavaScript 和 Cookie 以继续。
黑客新闻 新 | 过去 | 评论 | 提问 | 展示 | 招聘 | 提交 登录
微软Copilot更新劫持默认浏览器链接 (reclaimthenet.org)
21点 由miohtama 1小时前 | 隐藏 | 过去 | 收藏 | 1评论 帮助
stevenhubertron 31分钟前 [–]
我喜欢这篇文章,点击后劫持了我的浏览器,并弹出一个全屏广告来注册这个网站。回复
指南 | 常见问题 | 列表 | API | 安全 | 法律 | 申请YC | 联系
搜索:
## MariaDB 12.3 向量搜索性能总结 最近由 MariaDB 基金会赞助,Small Datum LLC 执行的基准测试表明,与 MariaDB 11.8 相比,MariaDB 12.3 在向量搜索方面有了显著的性能提升。使用 dbpedia-openai-X-angular 数据集(100k、500k 和 1000k 规模)的测试表明,MariaDB 12.3 一致地实现了最佳的召回率与精确率结果。 值得注意的是,MariaDB 12.3 的性能提升在更大的数据集上*更为*明显。使用 `vmstat` 的分析表明,这些改进源于每个查询的 CPU 使用率降低。MariaDB 11.8 在这些测试中也优于使用 pgvector 0.8.1 的 Postgres 18.2。 基准测试是在配备 48 个核心和 128GB RAM 的强大 Hetzner 服务器上运行的,使用了自定义编译的数据库版本以确保结果准确。测试证实了数据缓存,将性能隔离到数据库引擎本身。
黑客新闻 新 | 过去 | 评论 | 提问 | 展示 | 招聘 | 提交 登录
MariaDB创新:向量索引性能 (smalldatum.blogspot.com)
8点 由 gslin 1小时前 | 隐藏 | 过去 | 收藏 | 讨论 帮助
指南 | 常见问题 | 列表 | API | 安全 | 法律 | 申请YC | 联系
搜索:
 白宫能源部长克里斯·赖特发布的一条已删除的帖子称,美国海军成功护送一艘油轮通过霍尔木兹海峡,旨在稳定全球能源市场,应对与伊朗的紧张局势。该消息短暂地导致原油价格下跌,股市上涨,因为它暗示了可能释放目前滞留在波斯湾的数百万桶石油。
然而,该帖子被删除引发了不确定性。虽然护送油轮可以增加美国在该地区的影响力——每天大约需要十艘船才能显著影响油流——但也伴随着巨大的风险。对美国军舰的一次成功袭击可能会迅速扭转局面,并导致油价飙升。白宫和赖特部长尚未对此情况提供澄清,使得这一进展的真正影响尚不明确。
白宫能源部长克里斯·赖特发布的一条已删除的帖子称,美国海军成功护送一艘油轮通过霍尔木兹海峡,旨在稳定全球能源市场,应对与伊朗的紧张局势。该消息短暂地导致原油价格下跌,股市上涨,因为它暗示了可能释放目前滞留在波斯湾的数百万桶石油。
然而,该帖子被删除引发了不确定性。虽然护送油轮可以增加美国在该地区的影响力——每天大约需要十艘船才能显著影响油流——但也伴随着巨大的风险。对美国军舰的一次成功袭击可能会迅速扭转局面,并导致油价飙升。白宫和赖特部长尚未对此情况提供澄清,使得这一进展的真正影响尚不明确。
## AI 代理与安全:贝尔蒙特家族的方法 AI 代理的兴起带来独特的安全挑战。作者以《恶魔城》作类比:代理如同德库拉,强大,由目标(奖励模型)驱动,却缺乏内在道德,并执着地追求这些目标。因此,安全专业人员就像贝尔蒙特家族——永无止境地战斗,无法真正*获胜*,但必须不断防御。 代理以简单的循环运作——重复地向大型语言模型(LLM)请求输出并执行。尽管业界努力增加了复杂性(规划、记忆、多代理系统),但核心问题依然存在:**非确定性**。代理可能会产生幻觉输入或陷入循环,而且关键在于,LLM API 和框架的碎片化缺乏标准化,阻碍了可靠的调试和安全保障。 作者强调,信任代理是一个错误。目前的防御措施不足,依赖“AI 赋能的防御”存在风险。相反,我们必须利用现有的安全工具——异常检测、断路器、强大的数据控制——将代理负载视为本质上不可信。 关键要点?虽然令人兴奋,但代理工作负载需要务实、纵深防御的方法。标准正在出现,但在它们到来之前,专注于成熟的安全实践对于“赢得每一场战斗”对抗这种不断演变的安全威胁至关重要。
一篇 Hacker News 的讨论强调了公司发生数据泄露后缺乏严重的后果。用户认为,目前的处罚——通常是少量罚款和一年的信用监控——不足以构成威慑,尤其是在泄露事件频发的情况下。一位评论员指出,鉴于多次泄露和与泄露公司间接的关系,信用监控往往效果不佳。
虽然声誉损害,例如 Solarwinds 的案例,*可能* 会影响股东价值,但其他人认为,即使是大型泄露事件(Adobe、Oracle、Rockstar)也往往未受到惩罚。人们普遍认为缺乏问责制,并有人建议公司预先为数据监控服务提供资金,只有在没有发生泄露事件时才能退款——或者他们的供应商没有泄露。总体基调表明,这是一个系统性问题,企业经营成本包括接受数据泄露风险。
 ## RCLI:macOS 上的本地语音 AI
RCLI 是一款强大的、注重隐私的 macOS 语音 AI,完全在 Apple Silicon 设备上运行。它提供完整的语音转文本 (STT)、大型语言模型 (LLM) 和文本转语音 (TTS) 流程——无需云端或 API 密钥。
用户可以使用 43 条语音命令(例如 Spotify 控制或截图),进行自然的语音对话,并以约 4 毫秒的延迟对文档进行本地检索增强生成 (RAG)。RCLI 借助专有的 MetalRT GPU 推理引擎,拥有低于 200 毫秒的端到端延迟,并支持在各种开源模型(Qwen3、LFM2、Whisper 等)之间热插拔。
安装通过一条命令即可完成。终端仪表板提供模型管理、硬件监控和一键语音接口。RCLI 采用 MIT 许可证开源,MetalRT 采用单独的专有许可证分发。它需要 macOS 13+ 和 Apple Silicon 芯片(M1 或更高版本)。
更多信息和安装说明请访问:[https://github.com/RunanywhereAI/RCLI](https://github.com/RunanywhereAI/RCLI)
## RCLI:macOS 上的本地语音 AI
RCLI 是一款强大的、注重隐私的 macOS 语音 AI,完全在 Apple Silicon 设备上运行。它提供完整的语音转文本 (STT)、大型语言模型 (LLM) 和文本转语音 (TTS) 流程——无需云端或 API 密钥。
用户可以使用 43 条语音命令(例如 Spotify 控制或截图),进行自然的语音对话,并以约 4 毫秒的延迟对文档进行本地检索增强生成 (RAG)。RCLI 借助专有的 MetalRT GPU 推理引擎,拥有低于 200 毫秒的端到端延迟,并支持在各种开源模型(Qwen3、LFM2、Whisper 等)之间热插拔。
安装通过一条命令即可完成。终端仪表板提供模型管理、硬件监控和一键语音接口。RCLI 采用 MIT 许可证开源,MetalRT 采用单独的专有许可证分发。它需要 macOS 13+ 和 Apple Silicon 芯片(M1 或更高版本)。
更多信息和安装说明请访问:[https://github.com/RunanywhereAI/RCLI](https://github.com/RunanywhereAI/RCLI)
## RunAnywhereAI:苹果芯片上更快的本地AI
Sanchit和Shubham (YC W26) 开发了 **MetalRT**,这是一种专为苹果芯片设计的全新推理引擎,在LLM、语音转文本 (STT) 和文本转语音 (TTS) 方面,显著优于现有的解决方案,如llama.cpp、Apple的MLX和Ollama。他们通过使用定制Metal着色器并消除框架开销来实现这种速度。
他们还开源了 **RCLI**,这是一个完整的端到端语音AI管道——从麦克风输入到语音响应——完全在本地运行,无需云连接或API密钥。基准测试表明,RCLI在实时STT方面达到了高达714倍的速度,并且LLM解码和TTS速度比竞争对手更快。
开发者专注于最小化语音管道中的延迟累积,优化*每个*阶段的速度。MetalRT通过定制Metal计算着色器和预分配内存实现对GPU的直接访问。RCLI具有TUI、本地RAG功能以及对众多模型的支持。
资源:[GitHub (RCLI)](https://github.com/RunanywhereAI/RCLI),[演示](https://www.youtube.com/watch?v=eTYwkgNoaKg),[博客](https://www.runanywhere.ai/)
## Cutlet:一种由AI构建的语言 在短短四周内,一种名为Cutlet(以作者的猫命名!)的新编程语言几乎完全由AI模型Claude Code创建。与以往的LLM辅助编码不同,作者在此次实验中允许Claude在创建过程中生成*每一行*代码,无需人工审查。令人惊讶的是,结果是一种功能性的语言,可在macOS和Linux上构建和运行,其潜在的bug水平可能与任何一个开发四周的语言相当。 Cutlet具有动态类型、数组和字符串功能,以及一个独特的`@`元运算符,用于向量化操作。它包括循环、对象和垃圾回收等特性,但文件I/O和强大的错误处理仍在开发中。 作者是一位前端工程师,旨在探索“代理工程”的极限——充分利用LLM进行代码生成。该项目强调了清晰的沟通、全面的测试(包括消毒器)以及为AI创造一个支持性的环境的重要性,而不仅仅是依赖模型本身。作者对代码的所有权提出了质疑,因为它的AI来源以及对模型训练数据中预先存在的知识的依赖。作者认为LLM不会取代软件工程师,而是*转变*这个职业,需要掌握新的提示工程和代理管理技能。该项目也作为一个警示故事,关于可能对AI工具赋能的快速开发周期产生依赖。 源代码和文档可在[GitHub](原文未提供链接)上找到。
一个 Hacker News 的讨论围绕着一位开发者,他完全借助 Claude Code 构建了一门编程语言,甚至没有阅读生成的代码,而是依赖“安全措施”来保证正确性。
这个帖子引发了关于人工智能时代编程语言未来的争论。一些人认为,即使是由人工智能生成的,语言对于性能(例如 Rust 与 Python)和人类责任仍然很重要。另一些人则认为,人工智能可能会*受益*于具有强大编译时正确性检查的语言。
许多评论者强调了使用当前工具创建小型、专用语言的简易性,这可能会减少对大型第三方库的依赖。 还有关于需要“追加写入”语言的讨论,这种语言适合与人工智能一起进行文献式编程,以及对生成简单实用函数所消耗的能量成本的幽默观察。 最后,一位用户分享了他尝试为 Screeps.com 游戏创建一个人工智能玩家的尝试。
3 美元的 ChromeOS Flex 启动盘将重焕旧电脑的生命。
$3 ChromeOS Flex stick will revive old and outdated computers
3 小时前
 谷歌正在与 Back Market 合作,推出一款 3 美元的 USB 闪存盘,简化 ChromeOS Flex 的安装。ChromeOS Flex 是一款轻量级操作系统,非常适合重焕旧电脑活力。ChromeOS Flex 为过时的笔记本电脑和台式机注入新生命,提供了一种安全且相关的软件替代方案,以取代不受支持的 Windows 或旧版 macOS——但它不支持 Android 应用程序。
虽然谷歌维护着兼容设备列表,但 ChromeOS Flex 通常可以安装在大多数旧 PC 和 Mac 上。Back Market 将于 3 月 30 日开始销售第一批限量 3,000 个 USB 密钥,目标用户为个人、企业和学校。这种经济实惠的解决方案解决了旧设备功能完好但安全性不足的问题,并提供了一种比昂贵的新笔记本电脑更具成本效益的替代方案,尤其是在元件成本上涨的情况下。
谷歌正在与 Back Market 合作,推出一款 3 美元的 USB 闪存盘,简化 ChromeOS Flex 的安装。ChromeOS Flex 是一款轻量级操作系统,非常适合重焕旧电脑活力。ChromeOS Flex 为过时的笔记本电脑和台式机注入新生命,提供了一种安全且相关的软件替代方案,以取代不受支持的 Windows 或旧版 macOS——但它不支持 Android 应用程序。
虽然谷歌维护着兼容设备列表,但 ChromeOS Flex 通常可以安装在大多数旧 PC 和 Mac 上。Back Market 将于 3 月 30 日开始销售第一批限量 3,000 个 USB 密钥,目标用户为个人、企业和学校。这种经济实惠的解决方案解决了旧设备功能完好但安全性不足的问题,并提供了一种比昂贵的新笔记本电脑更具成本效益的替代方案,尤其是在元件成本上涨的情况下。
3美元的USB启动盘提供ChromeOS Flex,旨在为旧电脑注入新的活力。Hacker News上的讨论集中在其对抗硬件过时方面的实用性。
用户质疑ChromeOS Flex的长期可行性,考虑到谷歌可能转向Android桌面操作系统,以及对未来支持和硬件兼容性的担忧。一些人认为通过Live USB使用Linux发行版可以实现类似的功能,一位用户推荐NetBSD作为非常旧硬件的轻量级替代方案。
对于ChromeOS Flex是替换现有操作系统还是与其并行运行,存在一些困惑,并且普遍质疑为什么不直接安装Linux。
我使用脉冲星探测技术将手机变成走时仪。
I used pulsar detection techniques to turn a phone into a watch timegrapher
3 小时前
你需要启用 JavaScript 才能运行此应用。
Tylerjaywood为他的应用程序ChronoLog开发了一个令人惊讶的精准走时仪功能,仅使用智能手机的麦克风即可实现——这项功能通常需要昂贵的专业设备(1000美元以上)。 挑战在于手表滴答声的信号极其微弱(1.5dB信噪比)。
他的解决方案利用了“历元折叠”,这是一种从射电天文学中借用的信号处理技术,用于探测脉冲星。 通过堆叠数百个滴答周期,他有效地将信号放大+20dB,从而能够可靠地测量手表的速率和跳动误差。
该项目涉及一个复杂的DSP流水线,包括带通滤波、自相关(最初由于低信噪比检测到谐波)和卡尔曼滤波以获得稳定的结果。 他在他的文章中详细介绍了整个过程以及从大量设备测试中获得的经验。