![]()
binmoji is a C library and command-line tool that encodes any standard Unicode emoji into a single, fixed-size 64-bit integer (uint64_t). This provides a highly efficient, compact, and indexable alternative to storing emojis as variable-length UTF-8 strings.
- Compact Storage: Represents any emoji, no matter how complex, as a single
uint64_t. - High Performance: Blazing-fast encoding and decoding with minimal overhead.
- Lossless Conversion: Guarantees perfect round-trip conversion from emoji to ID and back.
- Unicode Compliant: The lookup table is generated from the official Unicode emoji data files, ensuring compatibility.
- Self-Contained: Includes a test suite to verify correctness against the Unicode standard.
- Low hash table bloat: Skin tone variations are flags, leading to a small lookup table (~158 entries)
- C89: Works everywhere
An emoji sequence is deconstructed into its fundamental parts, which are then packed into a 64-bit integer.
| Bits (63-0) | Field Name | Size (bits) | Description |
|---|---|---|---|
63-42 |
Primary Codepoint | 22 | The first base emoji in the sequence (e.g., '👩'). |
41-10 |
Component Hash | 32 | A CRC-32 hash of all subsequent emojis (e.g., '👩👧👦'). |
9-7 |
Skin Tone 1 | 3 | The first skin tone modifier. |
6-4 |
Skin Tone 2 | 3 | The second skin tone modifier (for couple/family emojis). |
3-0 |
Flags | 4 | Reserved for future use. |
Because hashing is a one-way process, a pre-computed lookup table (binmoji_table.h) is used to map a Component Hash back to its original list of component codepoints during decoding.
I was designing a cache-friendly, zero-copy metadata table for nostrdb. This table needed a way to record the number of reactions a nostr note has received for various different emoji reactions. To do this, the data needed to be aligned in the database as an array of metadata entries.
The problem is emojis are not just single characters, they can sometimes be composed of many different unicode codepoints separated by zero width joiners:
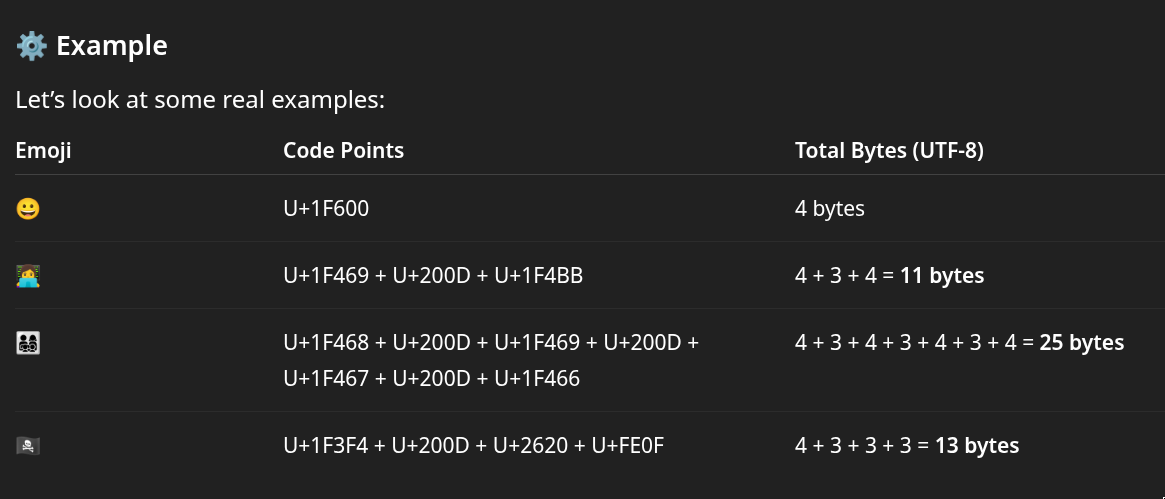
To avoid having annoying data structures like string tables, I wanted a way to simply have a fixed sized representation of any emoji. Hence, this library was born.
binmoji can be used for storing emojis in succinct data structures without having to deal with the headache of separate string storage.
I wanted an emoji ID that didn't require massive rainbow tables for every possible emoji combination. by moving some skin tone data into bits, our lookup table can be much smaller, which avoids code bloat.
This is simple enough that I believe it can become the canonical 64-bit emoji representation used across various systems. Let me know if you agree or disagree!
There is a possibility of collisions in the future, we can use the reserved flags as a nonce for known collisions if this ever comes up.
Just type make with a C compiler. You can regenerate the small ZWJ sequence hash table by getting the txt files from https://www.unicode.org/Public/17.0.0/emoji/. We also provide a snapshot of these in the repository for convenience.
The compiled binmoji executable can be used for encoding, decoding, and testing.
Pass the emoji string as an argument to get its unique Binmoji ID. The tool handles everything from simple icons to complex ZWJ sequences with multiple skin tones.
The simplest emojis have no components or modifiers.
./binmoji ❤️
0x009D918FB6174C00The pirate flag is formed by joining 🏴 and ☠️ with a ZWJ.
./binmoji 🏴☠️
0x07CFD3F0E9125C00Here, a dark skin tone is applied to the astronaut.
./binmoji 🧑🏿🚀
0x07E746E4F8DD5680This complex sequence requires storing two separate skin tones.
./binmoji 👩🏻🤝👩🏿
0x07D1A7747240B0D0To convert a Binmoji ID back to its emoji string, pass the hex ID (prefixed with 0x) as an argument.
# Decode the dual skin-tone emoji
./binmoji 0x07D1A7747240B0D0
👩🏻🤝👩🏿
# Decode the pirate flag
./binmoji 0x07CFD3F0E9125C00
🏴☠️To verify the implementation, run the built-in test suite. It performs a round-trip conversion test on thousands of emojis from the official Unicode data files.
A successful run will report zero failures.
You can integrate the core logic into your own C projects by including the header binmoji.h and compiling/linking binmoji.c. The main data structure is struct binmoji.
The main functions are:
void binmoji_parse(const char *emoji, struct binmoji *binmoji);- Parses a UTF-8 emoji string into the
struct binmoji.
- Parses a UTF-8 emoji string into the
uint64_t binmoji_encode(const struct binmoji *binmoji);- Generates a 64-bit ID from a populated
struct binmoji.
- Generates a 64-bit ID from a populated
void binmoji_decode(uint64_t id, struct binmoji *binmoji);- Decodes a 64-bit ID into a
struct binmoji, using an internal hash table to look up components.
- Decodes a 64-bit ID into a
void binmoji_to_string(const struct binmoji *binmoji, char *out_str, size_t out_str_size);- Builds the final UTF-8 emoji string from a
struct binmoji.
- Builds the final UTF-8 emoji string from a