☕ Welcome to The Coder Cafe! Today, we will explore CRDTs, why they matter in distributed systems, and how they keep nodes in sync. Get cozy, grab a coffee, and let’s begin!
CRDTs, short for Conflict-Free Replicated Data Types, are a family of data structures built for distributed systems. At first sight, CRDTs may look intimidating. Yet at their core, the idea is not that complex. What makes them special is that they allow updates to happen independently on different nodes while still guaranteeing that all replicas eventually converge to the same state.
To understand how CRDTs achieve this, we first need to step back. We need to talk about concurrent operations and what coordination means in a distributed system. Let’s take it step by step.
What does concurrent operations mean? Our first intuition might be to say they happen at the same time. That’s not quite right. Here’s a counterargument based on a collaborative editing example.
While on a plane, Alice connects to a document and makes an offline change to a sentence.
An hour later, Bob connects to the same document and edits the very same sentence, but online.
Later, when Alice lands, both versions have to sync.
The two edits (1. and 2.) were separated by an hour. They didn’t happen at the same time, yet they are concurrent.
So what’s a better definition for concurrent operations? Two operations that are not causally related.
In the previous example, neither operation was made with knowledge of the other. They are not causally related, which makes them concurrent. Yet, if Bob had first seen Alice’s update and then made his own, his edit would depend on hers. In that case, the two operations wouldn’t be concurrent anymore.
We should also understand concurrent ≠ conflict:
If Alice fixes a missing letter in a word while Bob removes the whole word, that’s a conflict.
If Alice edits one sentence while Bob edits another, that’s not a conflict.
Concurrency is about independence in knowledge. Conflict is about whether the effects of operations collide.
Now, let’s talk about coordination in distributed systems.
Imagine a database with two nodes, node 1 and node 2. A bunch of clients connect to it. Sometimes requests go to node 1, sometimes to node 2. Let’s say two clients send concurrent and conflicting operations:
In this case, we can’t have node 1 storing $200 while node 2 stores -$100. That would be a consistency violation with the two nodes disagreeing on Alice’s balance.
Instead, both nodes need to agree on a shared value. To do that, they have to communicate and decide on one of the following:
The very action of nodes communicating and, if needed, waiting to agree on a single outcome is called coordination.
Coordination is one way to keep replicas consistent under concurrent operations. But coordination is not the only way. That’s where CRDTs come in.
CRDT stands for Conflict-Free Replicated Data Types. In short, CRDTs are data structures built so that nodes can accept local updates independently and concurrently, without the need for coordination.
If you read our recent post on availability models, you might notice we’re now in the territory of total availability: a system is totally available if every non-faulty node can execute any operation. Total availability comes with weaker consistency. For CRDTs, the consistency guarantee is called Strong Eventual Consistency (SEC).
For that, CRDTs rely on a deterministic conflict resolution algorithm. Because every node applies the same rules, all replicas are guaranteed to eventually converge to the same state.
Let’s make this more concrete with a classic CRDT: the G-Counter (Grow-Only Counter).
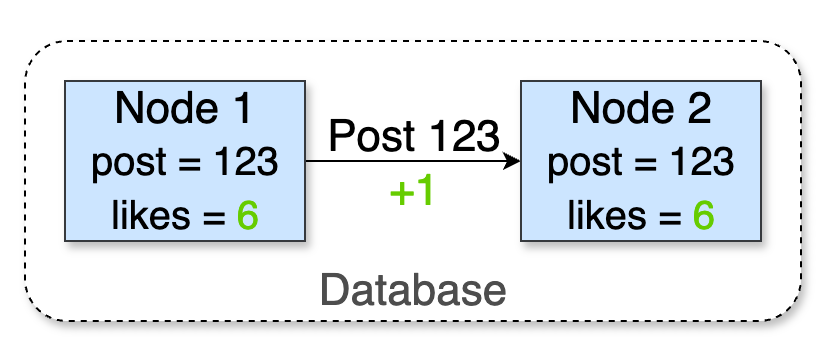
Imagine a database with two nodes tracking the number of likes on a post. Node 1 receives a new like, increments its counter, and replies success to the client:
Then, node 1 communicates with node 2 to send this update:

Ultimately, both nodes converge to the same value: 6.
How does the conflict resolution work for a G-Counter?
Each replica keeps a vector of counters, with one slot per node. In our example, the total number of likes is 5. Let’s say node 1 has seen 2 likes and node 2 has seen 3 likes. So the initial state is the following:
Node 1: [2, 3]
Node 2: [2, 3]When node 1 receives a new like, it only increments its own slot. Node 2 is now temporarily out of sync:
Node 1: [3, 3]
Node 2: [2, 3]During synchronization, both nodes merge their vectors by taking the element-wise maximum:
[max(3,2), max(3,3)] = [3, 3]Now both replicas converge to the same state:
Node 1: [3, 3]
Node 2: [3, 3]The beauty of this algorithm is that it’s deterministic and order-independent. No matter when or how often the nodes sync, they always end up with the same state.
NOTE: Do you know Gossip Glomers? It’s a series of distributed systems challenges we briefly introduced in an earlier post. Challenge 4 is to build a Grow-Only Counter. It’s worth checking out if you haven’t already.
CRDTs can also be combined to make a more complex CRDT. For example, if we want to track both likes and dislikes, we can use two G-Counters together. This data type is called a PN-Counter (Positive-Negative Counter).
Imagine two clients act concurrently on the same post: one likes it, another dislikes it.
The nodes exchange their updates and converge to the same value:
In the case of a PN-Counter, the conflict resolution algorithm is similar to the G-Counter. The difference lies in the fact that it involves not one but two vectors: one for increases and one for decreases.
Assume an initial state where node 1 has received 2 likes and 0 dislikes, and node 2 has received 3 likes and 0 dislikes:
-- Increase
Node 1: [2, 3]
Node 2: [2, 3]
-- Decrease
Node 1: [0, 0]
Node 2: [0, 0]Now, suppose node 1 receives a new like and node 2 receives a dislike. Before the sync, the state is the following:
-- Increase
Node 1: [3, 3]
Node 2: [2, 3]
-- Decrease
Node 1: [0, 0]
Node 2: [0, 1]When the replicas exchange their state, the merge rule is element-wise maximum for each vector:
-- Increase
[max(3,2), max(3,3)] = [3, 3]
-- Decrease
[max(0,0), max(0,1)] = [0, 1]After sync, both nodes converge to:
-- Increase
Node 1: [3, 3]
Node 2: [3, 3]
-- Decrease
Node 1: [0, 1]
Node 2: [0, 1]The final counter of likes is:
node1Likes + node2Likes - node1Dislikes - node2Dislikes
= 3 + 3 - 0 - 1
= 5Let’s pause for a second. Based on what we’ve discussed, can you think of some use cases for CRDTs? A data structure where nodes are updated independently, concurrently, without coordination, and still guarantees that they converge to the same state?
One main use case is collaborative and offline-first systems. For example, Notion, a collaborative workspace, recently introduced a feature that lets people edit the same content offline. They rely on CRDTs, and more specifically on Peritext, a CRDT for rich-text collaboration co-authored by multiple people, including
.Another big use case is totally available systems that put availability ahead of strong consistency. As we’ve seen, nodes don’t need to coordinate before acknowledging a client request, which makes the system more highly available.
Take Redis, for example. It can be configured in an active-active architecture with geographically distributed datacenters. Clients connect to their closest cluster and get local latencies without waiting for coordination across distant regions. And yes, this setup is built on CRDTs.
We could also think about other applications for CRDTs, like:
Edge & IoT: Devices update offline and merge later without a central server.
Peer-to-peer: Peers share changes directly and match up when they reconnect.
CDN/edge state: Keep preferences, drafts, or counters near users and sync to the origin later.
There are two main types of CRDTs:
In the previous examples, we looked at two state-based CRDTs: the G-Counter (Grow-Only Counter) and the PN-Counter (Positive-Negative Counter). In both cases, what was exchanged between the nodes was the entire state. For example, node 1 could tell node 2 that its total number of likes is 3.
With state-based CRDTs, states are merged with a function that must be:
Commutative: We can merge in any order and get the same result.
Idempotent: Merging something with itself doesn’t change it.
Associative: We can merge in any grouping and get the same result.
Each synchronization monotonically increases the internal state. In other words, when two replicas sync, the state can only move forward, never backward. This is enforced by a simple “can’t-go-backwards” rule (a partial order), where merges use operations like max for numbers (as we’ve seen) or union for sets.
In operation-based CRDTs, nodes share the operations rather than the full state. Convergence relies on three properties:
Commutativity of concurrent operations
Causality: Either carried in the operations’ metadata (for example, vector clocks) or guaranteed by the transport layer through causal delivery
Duplicate tolerance: Handled by idempotent operations, unique operation IDs with deduplication, or a transport layer that guarantees no duplicates
One example of an operation-based CRDT is the LWW-Register (Last-Writer-Wins Register), which stores a single value. Updates are resolved using a logical timestamp (such as Lamport clocks) along with a tie-breaker like the node ID. When a node writes a value, it broadcasts an operation (value, timestamp, nodeID). On receiving it, a node applies the update if the pair (timestamp, nodeID) is greater than the one it currently holds.
To summarize:
State-based CRDTs:
Convergence is guaranteed because merging states is associative, commutative, and idempotent.
Don’t require assumptions on the delivery layer beyond eventual delivery.
Simpler to reason about.
Exchanging full states can be more bandwidth-intensive.
Operation-based CRDTs:
More bandwidth-efficient; we only send the operations, not the whole state.
Correctness usually depends on having causal order (or encoding causality in the ops) and tolerating duplicates via idempotence/dedup.
More complex to implement (causal broadcast, vector clocks, or equivalent).
For completeness, there’s also a third type we should be aware of: delta-based CRDTs. Here, convergence is achieved by sending and merging fragments of state (deltas) rather than the entire state. A quick analogy to picture the differences:
State-based CRDT: “From time to time, send me the whole document.”
Operation-based CRDT: “When you make a change, tell me exactly what you did.” → “Adding word `miles` at position 42.”
Delta-based CRDT: “When you make a change, send me just the delta that reflects it (for example, the updated sentence)” → “And miles to go before I sleep.”
We talked about collaborative document editing. So you might assume a system like Google Docs is based on CRDTs, right?
Well, that’s not the case. Google Docs is based on another concept called OT (Operational Transformation). The goal of OT and CRDT is the same: convergence among all nodes in a collaborative system.
The main difference is that OT requires all communication to go through the same server:
We haven’t mentioned it until now (on purpose), but with CRDTs, there’s no need for a central server to achieve convergence.
Back to our collaborative editing tool: if Alice and Bob are both offline but manage to connect their laptops directly, they could still achieve convergence without talking to a central server:

As we saw earlier, CRDTs embed a deterministic conflict resolution algorithm. The data type itself ensures convergence.
That’s the key difference: CRDTs don’t need to make any assumptions about the network topology or about a central server.
considers CRDT to be the natural successor of OT.NOTE: So, why is Google Docs still based on OT? Historical reasons. Google Docs was launched before CRDTs existed, and it still works really well. There’s no practical reason for Google to migrate from OT to CRDT, despite some discussions about it in the past.
Operations are concurrent when they aren’t causally related; concurrency doesn’t automatically mean conflict.
Coordination is when replicas communicate and, if needed, wait to agree on a single outcome for concurrent updates before acknowledging clients, so they don’t diverge.
CRDTs accept independent updates on each replica and still converge via deterministic merge rules.
Three types: state-based (share full state), operation-based (share operations), delta-based (share just the changed parts).
CRDTs are a great fit for systems like offline-first collaboration and highly available systems.
Unlike OT, CRDTs don’t rely on a central server to reach the same result everywhere.

❤️ If you enjoyed this post, please hit the like button.
💬 Have you worked with CRDTs before, or do you see another use case where they shine? Share your thoughts in the comments!